 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedMental: Evaluating Federated Learning for Mental Health Detection from Social Media Data
May 18, 2026Social media text data are often used to train Machine Learning (ML) models to identify users exhibiting high-risk mental health behaviors. However, sharing this sensitive data poses privacy risks and limits the growth of benchmark datasets. We comprehensively evaluate whether privacy-preserving ML techniques can enable safer data sharing while preserving performance. Specifically, we apply federated learning (FL) and Differentially Private FL for two widely-studied mental health prediction tasks: depression detection on X (Twitter) and suicide crisis detection on Reddit. We simulate realistic data-sharing scenarios by treating each user as a client in a non-IID setting, evaluating across different client fractions, aggregation strategies, and privacy budgets. While FL achieves comparable performance to centralized training (centralized F1 = 85.63; best FL model F1 = 83.16) on depression identification, we find that Differentially Private FL has a large performance-privacy trade-off (up to F1 = 27.01 drop) even with low levels of noise (epsilon = 50). This is due to the distortion of highly informative yet sparse mental health linguistic markers related to mental health, like health topics and emotion words. This research empirically demonstrates the potential and limitations of current privacy preservation techniques for mental health inference tasks.
Characterizing Delusional Spirals through Human-LLM Chat Logs
Mar 17, 2026As large language models (LLMs) have proliferated, disturbing anecdotal reports of negative psychological effects, such as delusions, self-harm, and ``AI psychosis,'' have emerged in global media and legal discourse. However, it remains unclear how users and chatbots interact over the course of lengthy delusional ``spirals,'' limiting our ability to understand and mitigate the harm. In our work, we analyze logs of conversations with LLM chatbots from 19 users who report having experienced psychological harms from chatbot use. Many of our participants come from a support group for such chatbot users. We also include chat logs from participants covered by media outlets in widely-distributed stories about chatbot-reinforced delusions. In contrast to prior work that speculates on potential AI harms to mental health, to our knowledge we present the first in-depth study of such high-profile and veridically harmful cases. We develop an inventory of 28 codes and apply it to the $391,562$ messages in the logs. Codes include whether a user demonstrates delusional thinking (15.5% of user messages), a user expresses suicidal thoughts (69 validated user messages), or a chatbot misrepresents itself as sentient (21.2% of chatbot messages). We analyze the co-occurrence of message codes. We find, for example, that messages that declare romantic interest and messages where the chatbot describes itself as sentient occur much more often in longer conversations, suggesting that these topics could promote or result from user over-engagement and that safeguards in these areas may degrade in multi-turn settings. We conclude with concrete recommendations for how policymakers, LLM chatbot developers, and users can use our inventory and conversation analysis tool to understand and mitigate harm from LLM chatbots. Warning: This paper discusses self-harm, trauma, and violence.
Large Language Models for Mental Health: A Multilingual Evaluation
Feb 02, 2026Large Language Models (LLMs) have remarkable capabilities across NLP tasks. However, their performance in multilingual contexts, especially within the mental health domain, has not been thoroughly explored. In this paper, we evaluate proprietary and open-source LLMs on eight mental health datasets in various languages, as well as their machine-translated (MT) counterparts. We compare LLM performance in zero-shot, few-shot, and fine-tuned settings against conventional NLP baselines that do not employ LLMs. In addition, we assess translation quality across language families and typologies to understand its influence on LLM performance. Proprietary LLMs and fine-tuned open-source LLMs achieve competitive F1 scores on several datasets, often surpassing state-of-the-art results. However, performance on MT data is generally lower, and the extent of this decline varies by language and typology. This variation highlights both the strengths of LLMs in handling mental health tasks in languages other than English and their limitations when translation quality introduces structural or lexical mismatches.
Measurement as Bricolage: Examining How Data Scientists Construct Target Variables for Predictive Modeling Tasks
Jul 03, 2025



Data scientists often formulate predictive modeling tasks involving fuzzy, hard-to-define concepts, such as the "authenticity" of student writing or the "healthcare need" of a patient. Yet the process by which data scientists translate fuzzy concepts into a concrete, proxy target variable remains poorly understood. We interview fifteen data scientists in education (N=8) and healthcare (N=7) to understand how they construct target variables for predictive modeling tasks. Our findings suggest that data scientists construct target variables through a bricolage process, involving iterative negotiation between high-level measurement objectives and low-level practical constraints. Data scientists attempt to satisfy five major criteria for a target variable through bricolage: validity, simplicity, predictability, portability, and resource requirements. To achieve this, data scientists adaptively use problem (re)formulation strategies, such as swapping out one candidate target variable for another when the first fails to meet certain criteria (e.g., predictability), or composing multiple outcomes into a single target variable to capture a more holistic set of modeling objectives. Based on our findings, we present opportunities for future HCI, CSCW, and ML research to better support the art and science of target variable construction.
Secondary Stakeholders in AI: Fighting for, Brokering, and Navigating Agency
Jun 08, 2025

As AI technologies become more human-facing, there have been numerous calls to adapt participatory approaches to AI development -- spurring the idea of participatory AI. However, these calls often focus only on primary stakeholders, such as end-users, and not secondary stakeholders. This paper seeks to translate the ideals of participatory AI to a broader population of secondary AI stakeholders through semi-structured interviews. We theorize that meaningful participation involves three participatory ideals: (1) informedness, (2) consent, and (3) agency. We also explore how secondary stakeholders realize these ideals by traversing a complicated problem space. Like walking up the rungs of a ladder, these ideals build on one another. We introduce three stakeholder archetypes: the reluctant data contributor, the unsupported activist, and the well-intentioned practitioner, who must navigate systemic barriers to achieving agentic AI relationships. We envision an AI future where secondary stakeholders are able to meaningfully participate with the AI systems they influence and are influenced by.
Expressing stigma and inappropriate responses prevents LLMs from safely replacing mental health providers
Apr 25, 2025Should a large language model (LLM) be used as a therapist? In this paper, we investigate the use of LLMs to *replace* mental health providers, a use case promoted in the tech startup and research space. We conduct a mapping review of therapy guides used by major medical institutions to identify crucial aspects of therapeutic relationships, such as the importance of a therapeutic alliance between therapist and client. We then assess the ability of LLMs to reproduce and adhere to these aspects of therapeutic relationships by conducting several experiments investigating the responses of current LLMs, such as `gpt-4o`. Contrary to best practices in the medical community, LLMs 1) express stigma toward those with mental health conditions and 2) respond inappropriately to certain common (and critical) conditions in naturalistic therapy settings -- e.g., LLMs encourage clients' delusional thinking, likely due to their sycophancy. This occurs even with larger and newer LLMs, indicating that current safety practices may not address these gaps. Furthermore, we note foundational and practical barriers to the adoption of LLMs as therapists, such as that a therapeutic alliance requires human characteristics (e.g., identity and stakes). For these reasons, we conclude that LLMs should not replace therapists, and we discuss alternative roles for LLMs in clinical therapy.
The Users Aren't Alright: Dangerous Mental Illness Behaviors and Recommendations
Sep 08, 2022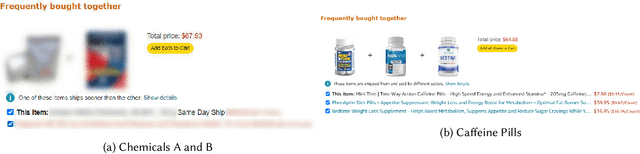
In this paper, we argue that recommendation systems are in a unique position to propagate dangerous and cruel behaviors to people with mental illnesses.
Towards Practices for Human-Centered Machine Learning
Mar 01, 2022"Human-centered machine learning" (HCML) is a term that describes machine learning that applies to human-focused problems. Although this idea is noteworthy and generates scholarly excitement, scholars and practitioners have struggled to clearly define and implement HCML in computer science. This article proposes practices for human-centered machine learning, an area where studying and designing for social, cultural, and ethical implications are just as important as technical advances in ML. These practices bridge between interdisciplinary perspectives of HCI, AI, and sociotechnical fields, as well as ongoing discourse on this new area. The five practices include ensuring HCML is the appropriate solution space for a problem; conceptualizing problem statements as position statements; moving beyond interaction models to define the human; legitimizing domain contributions; and anticipating sociotechnical failure. I conclude by suggesting how these practices might be implemented in research and practice.
#anorexia, #anarexia, #anarexyia: Characterizing Online Community Practices with Orthographic Variation
Dec 04, 2017



Distinctive linguistic practices help communities build solidarity and differentiate themselves from outsiders. In an online community, one such practice is variation in orthography, which includes spelling, punctuation, and capitalization. Using a dataset of over two million Instagram posts, we investigate orthographic variation in a community that shares pro-eating disorder (pro-ED) content. We find that not only does orthographic variation grow more frequent over time, it also becomes more profound or deep, with variants becoming increasingly distant from the original: as, for example, #anarexyia is more distant than #anarexia from the original spelling #anorexia. These changes are driven by newcomers, who adopt the most extreme linguistic practices as they enter the community. Moreover, this behavior correlates with engagement: the newcomers who adopt deeper orthographic variants tend to remain active for longer in the community, and the posts that contain deeper variation receive more positive feedback in the form of "likes." Previous work has linked community membership change with language change, and our work casts this connection in a new light, with newcomers driving an evolving practice, rather than adapting to it. We also demonstrate the utility of orthographic variation as a new lens to study sociolinguistic change in online communities, particularly when the change results from an exogenous force such as a content ban.