 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-efficient pre-training by scaling synthetic megadocs
Mar 19, 2026Synthetic data augmentation has emerged as a promising solution when pre-training is constrained by data rather than compute. We study how to design synthetic data algorithms that achieve better loss scaling: not only lowering loss at finite compute but especially as compute approaches infinity. We first show that pre-training on web data mixed with synthetically generated rephrases improves i.i.d. validation loss on the web data, despite the synthetic data coming from an entirely different distribution. With optimal mixing and epoching, loss and benchmark accuracy improve without overfitting as the number of synthetic generations grows, plateauing near $1.48\times$ data efficiency at 32 rephrases per document. We find even better loss scaling under a new perspective: synthetic generations from the same document can form a single substantially longer megadocument instead of many short documents. We show two ways to construct megadocs: stitching synthetic rephrases from the same web document or stretching a document by inserting rationales. Both methods improve i.i.d. loss, downstream benchmarks, and especially long-context loss relative to simple rephrasing, increasing data efficiency from $1.48\times$ to $1.80\times$ at $32$ generations per document. Importantly, the improvement of megadocs over simple rephrasing widens as more synthetic data is generated. Our results show how to design synthetic data algorithms that benefit more from increasing compute when data-constrained.
Characterizing Delusional Spirals through Human-LLM Chat Logs
Mar 17, 2026As large language models (LLMs) have proliferated, disturbing anecdotal reports of negative psychological effects, such as delusions, self-harm, and ``AI psychosis,'' have emerged in global media and legal discourse. However, it remains unclear how users and chatbots interact over the course of lengthy delusional ``spirals,'' limiting our ability to understand and mitigate the harm. In our work, we analyze logs of conversations with LLM chatbots from 19 users who report having experienced psychological harms from chatbot use. Many of our participants come from a support group for such chatbot users. We also include chat logs from participants covered by media outlets in widely-distributed stories about chatbot-reinforced delusions. In contrast to prior work that speculates on potential AI harms to mental health, to our knowledge we present the first in-depth study of such high-profile and veridically harmful cases. We develop an inventory of 28 codes and apply it to the $391,562$ messages in the logs. Codes include whether a user demonstrates delusional thinking (15.5% of user messages), a user expresses suicidal thoughts (69 validated user messages), or a chatbot misrepresents itself as sentient (21.2% of chatbot messages). We analyze the co-occurrence of message codes. We find, for example, that messages that declare romantic interest and messages where the chatbot describes itself as sentient occur much more often in longer conversations, suggesting that these topics could promote or result from user over-engagement and that safeguards in these areas may degrade in multi-turn settings. We conclude with concrete recommendations for how policymakers, LLM chatbot developers, and users can use our inventory and conversation analysis tool to understand and mitigate harm from LLM chatbots. Warning: This paper discusses self-harm, trauma, and violence.
Large Language Models Persuade Without Planning Theory of Mind
Feb 19, 2026A growing body of work attempts to evaluate the theory of mind (ToM) abilities of humans and large language models (LLMs) using static, non-interactive question-and-answer benchmarks. However, theoretical work in the field suggests that first-personal interaction is a crucial part of ToM and that such predictive, spectatorial tasks may fail to evaluate it. We address this gap with a novel ToM task that requires an agent to persuade a target to choose one of three policy proposals by strategically revealing information. Success depends on a persuader's sensitivity to a given target's knowledge states (what the target knows about the policies) and motivational states (how much the target values different outcomes). We varied whether these states were Revealed to persuaders or Hidden, in which case persuaders had to inquire about or infer them. In Experiment 1, participants persuaded a bot programmed to make only rational inferences. LLMs excelled in the Revealed condition but performed below chance in the Hidden condition, suggesting difficulty with the multi-step planning required to elicit and use mental state information. Humans performed moderately well in both conditions, indicating an ability to engage such planning. In Experiment 2, where a human target role-played the bot, and in Experiment 3, where we measured whether human targets' real beliefs changed, LLMs outperformed human persuaders across all conditions. These results suggest that effective persuasion can occur without explicit ToM reasoning (e.g., through rhetorical strategies) and that LLMs excel at this form of persuasion. Overall, our results caution against attributing human-like ToM to LLMs while highlighting LLMs' potential to influence people's beliefs and behavior.
Neural Nonmyopic Bayesian Optimization in Dynamic Cost Settings
Jan 10, 2026Bayesian optimization (BO) is a common framework for optimizing black-box functions, yet most existing methods assume static query costs and rely on myopic acquisition strategies. We introduce LookaHES, a nonmyopic BO framework designed for dynamic, history-dependent cost environments, where evaluation costs vary with prior actions, such as travel distance in spatial tasks or edit distance in sequence design. LookaHES combines a multi-step variant of $H$-Entropy Search with pathwise sampling and neural policy optimization, enabling long-horizon planning beyond twenty steps without the exponential complexity of existing nonmyopic methods. The key innovation is the integration of neural policies, including large language models, to effectively navigate structured, combinatorial action spaces such as protein sequences. These policies amortize lookahead planning and can be integrated with domain-specific constraints during rollout. Empirically, LookaHES outperforms strong myopic and nonmyopic baselines across nine synthetic benchmarks from two to eight dimensions and two real-world tasks: geospatial optimization using NASA night-light imagery and protein sequence design with constrained token-level edits. In short, LookaHES provides a general, scalable, and cost-aware solution for robust long-horizon optimization in complex decision spaces, which makes it a useful tool for researchers in machine learning, statistics, and applied domains. Our implementation is available at https://github.com/sangttruong/nonmyopia.
3D-Generalist: Self-Improving Vision-Language-Action Models for Crafting 3D Worlds
Jul 09, 2025Despite large-scale pretraining endowing models with language and vision reasoning capabilities, improving their spatial reasoning capability remains challenging due to the lack of data grounded in the 3D world. While it is possible for humans to manually create immersive and interactive worlds through 3D graphics, as seen in applications such as VR, gaming, and robotics, this process remains highly labor-intensive. In this paper, we propose a scalable method for generating high-quality 3D environments that can serve as training data for foundation models. We recast 3D environment building as a sequential decision-making problem, employing Vision-Language-Models (VLMs) as policies that output actions to jointly craft a 3D environment's layout, materials, lighting, and assets. Our proposed framework, 3D-Generalist, trains VLMs to generate more prompt-aligned 3D environments via self-improvement fine-tuning. We demonstrate the effectiveness of 3D-Generalist and the proposed training strategy in generating simulation-ready 3D environments. Furthermore, we demonstrate its quality and scalability in synthetic data generation by pretraining a vision foundation model on the generated data. After fine-tuning the pre-trained model on downstream tasks, we show that it surpasses models pre-trained on meticulously human-crafted synthetic data and approaches results achieved with real data orders of magnitude larger.
CogGen: A Learner-Centered Generative AI Architecture for Intelligent Tutoring with Programming Video
Jun 25, 2025


We introduce CogGen, a learner-centered AI architecture that transforms programming videos into interactive, adaptive learning experiences by integrating student modeling with generative AI tutoring based on the Cognitive Apprenticeship framework. The architecture consists of three components: (1) video segmentation by learning goals, (2) a conversational tutoring engine applying Cognitive Apprenticeship strategies, and (3) a student model using Bayesian Knowledge Tracing to adapt instruction. Our technical evaluation demonstrates effective video segmentation accuracy and strong pedagogical alignment across knowledge, method, action, and interaction layers. Ablation studies confirm the necessity of each component in generating effective guidance. This work advances AI-powered tutoring by bridging structured student modeling with interactive AI conversations, offering a scalable approach to enhancing video-based programming education.
From Replication to Redesign: Exploring Pairwise Comparisons for LLM-Based Peer Review
Jun 12, 2025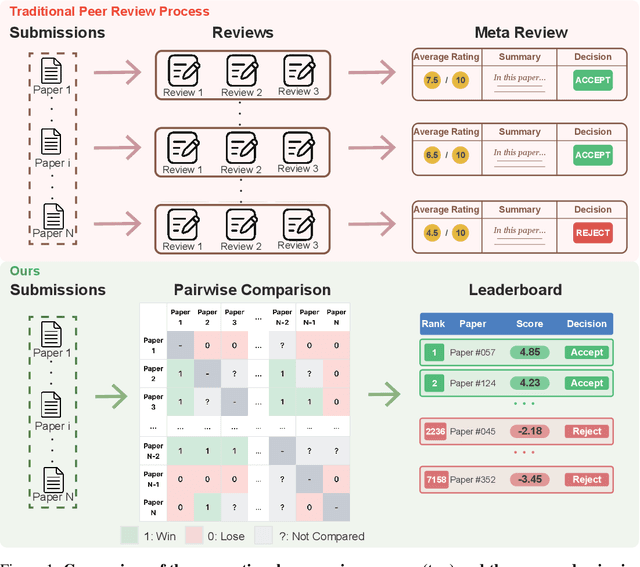
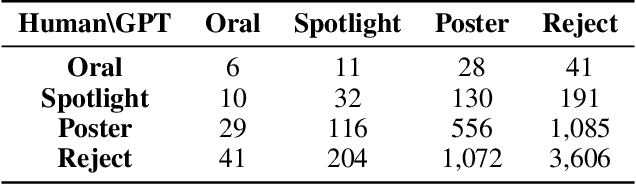
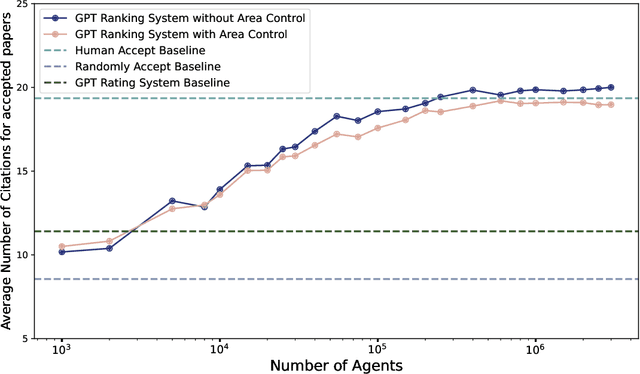
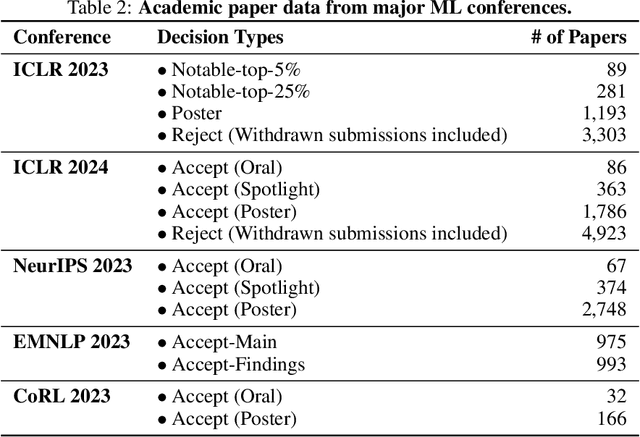
The advent of large language models (LLMs) offers unprecedented opportunities to reimagine peer review beyond the constraints of traditional workflows. Despite these opportunities, prior efforts have largely focused on replicating traditional review workflows with LLMs serving as direct substitutes for human reviewers, while limited attention has been given to exploring new paradigms that fundamentally rethink how LLMs can participate in the academic review process. In this paper, we introduce and explore a novel mechanism that employs LLM agents to perform pairwise comparisons among manuscripts instead of individual scoring. By aggregating outcomes from substantial pairwise evaluations, this approach enables a more accurate and robust measure of relative manuscript quality. Our experiments demonstrate that this comparative approach significantly outperforms traditional rating-based methods in identifying high-impact papers. However, our analysis also reveals emergent biases in the selection process, notably a reduced novelty in research topics and an increased institutional imbalance. These findings highlight both the transformative potential of rethinking peer review with LLMs and critical challenges that future systems must address to ensure equity and diversity.
Just Enough Thinking: Efficient Reasoning with Adaptive Length Penalties Reinforcement Learning
Jun 06, 2025Large reasoning models (LRMs) achieve higher performance on challenging reasoning tasks by generating more tokens at inference time, but this verbosity often wastes computation on easy problems. Existing solutions, including supervised finetuning on shorter traces, user-controlled budgets, or RL with uniform penalties, either require data curation, manual configuration, or treat all problems alike regardless of difficulty. We introduce Adaptive Length Penalty (ALP), a reinforcement learning objective tailoring generation length to per-prompt solve rate. During training, ALP monitors each prompt's online solve rate through multiple rollouts and adds a differentiable penalty whose magnitude scales inversely with that rate, so confident (easy) prompts incur a high cost for extra tokens while hard prompts remain unhindered. Posttraining DeepScaleR-1.5B with ALP cuts average token usage by 50\% without significantly dropping performance. Relative to fixed-budget and uniform penalty baselines, ALP redistributes its reduced budget more intelligently by cutting compute on easy prompts and reallocating saved tokens to difficult ones, delivering higher accuracy on the hardest problems with higher cost.
When Models Know More Than They Can Explain: Quantifying Knowledge Transfer in Human-AI Collaboration
Jun 05, 2025



Recent advancements in AI reasoning have driven substantial improvements across diverse tasks. A critical open question is whether these improvements also yields better knowledge transfer: the ability of models to communicate reasoning in ways humans can understand, apply, and learn from. To investigate this, we introduce Knowledge Integration and Transfer Evaluation (KITE), a conceptual and experimental framework for Human-AI knowledge transfer capabilities and conduct the first large-scale human study (N=118) explicitly designed to measure it. In our two-phase setup, humans first ideate with an AI on problem-solving strategies, then independently implement solutions, isolating model explanations' influence on human understanding. Our findings reveal that although model benchmark performance correlates with collaborative outcomes, this relationship is notably inconsistent, featuring significant outliers, indicating that knowledge transfer requires dedicated optimization. Our analysis identifies behavioral and strategic factors mediating successful knowledge transfer. We release our code, dataset, and evaluation framework to support future work on communicatively aligned models.
Expressing stigma and inappropriate responses prevents LLMs from safely replacing mental health providers
Apr 25, 2025Should a large language model (LLM) be used as a therapist? In this paper, we investigate the use of LLMs to *replace* mental health providers, a use case promoted in the tech startup and research space. We conduct a mapping review of therapy guides used by major medical institutions to identify crucial aspects of therapeutic relationships, such as the importance of a therapeutic alliance between therapist and client. We then assess the ability of LLMs to reproduce and adhere to these aspects of therapeutic relationships by conducting several experiments investigating the responses of current LLMs, such as `gpt-4o`. Contrary to best practices in the medical community, LLMs 1) express stigma toward those with mental health conditions and 2) respond inappropriately to certain common (and critical) conditions in naturalistic therapy settings -- e.g., LLMs encourage clients' delusional thinking, likely due to their sycophancy. This occurs even with larger and newer LLMs, indicating that current safety practices may not address these gaps. Furthermore, we note foundational and practical barriers to the adoption of LLMs as therapists, such as that a therapeutic alliance requires human characteristics (e.g., identity and stakes). For these reasons, we conclude that LLMs should not replace therapists, and we discuss alternative roles for LLMs in clinical therapy.