 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Cards: An Interpretive Layer for AI Evaluation Reporting
Jun 09, 2026AI evaluation results are produced at scale but reported inconsistently across leaderboards, model cards, benchmark papers, and company blogs. The cost is interpretive: readers cannot reliably compare results across sources, identify what a report omits, or trace an aggregate claim to its underlying evidence. Recent efforts address isolated components but leave three gaps: they cover only narrow slices of the evaluation lifecycle and do not compose into a single interpretable record; they specify static representations that do not differentiate the questions different stakeholders bring to the same evidence; and they remain proposals on paper, lacking the extraction infrastructure required for adoption at scale. We present \EvalCards{}, an operational reporting layer that composes benchmark metadata, evaluation run data, and model metadata into a unified record. We (1) derive a reporting schema from a structured review of 52 papers and 10 stakeholder interviews, (2) implement four interpretive signals (reproducibility, documentation completeness, provenance and risk, and score comparability), rendered through reader modes calibrated to research and non-research audiences, and (3) deploy a monitoring tool that applies \EvalCards{} across 5,816 models, 635 benchmarks, and 101,843 results, surfacing systematic gaps in current reporting practice.
Characterizing Delusional Spirals through Human-LLM Chat Logs
Mar 17, 2026As large language models (LLMs) have proliferated, disturbing anecdotal reports of negative psychological effects, such as delusions, self-harm, and ``AI psychosis,'' have emerged in global media and legal discourse. However, it remains unclear how users and chatbots interact over the course of lengthy delusional ``spirals,'' limiting our ability to understand and mitigate the harm. In our work, we analyze logs of conversations with LLM chatbots from 19 users who report having experienced psychological harms from chatbot use. Many of our participants come from a support group for such chatbot users. We also include chat logs from participants covered by media outlets in widely-distributed stories about chatbot-reinforced delusions. In contrast to prior work that speculates on potential AI harms to mental health, to our knowledge we present the first in-depth study of such high-profile and veridically harmful cases. We develop an inventory of 28 codes and apply it to the $391,562$ messages in the logs. Codes include whether a user demonstrates delusional thinking (15.5% of user messages), a user expresses suicidal thoughts (69 validated user messages), or a chatbot misrepresents itself as sentient (21.2% of chatbot messages). We analyze the co-occurrence of message codes. We find, for example, that messages that declare romantic interest and messages where the chatbot describes itself as sentient occur much more often in longer conversations, suggesting that these topics could promote or result from user over-engagement and that safeguards in these areas may degrade in multi-turn settings. We conclude with concrete recommendations for how policymakers, LLM chatbot developers, and users can use our inventory and conversation analysis tool to understand and mitigate harm from LLM chatbots. Warning: This paper discusses self-harm, trauma, and violence.
The Limits of AI Data Transparency Policy: Three Disclosure Fallacies
Jan 26, 2026Data transparency has emerged as a rallying cry for addressing concerns about AI: data quality, privacy, and copyright chief among them. Yet while these calls are crucial for accountability, current transparency policies often fall short of their intended aims. Similar to nutrition facts for food, policies aimed at nutrition facts for AI currently suffer from a limited consideration of research on effective disclosures. We offer an institutional perspective and identify three common fallacies in policy implementations of data disclosures for AI. First, many data transparency proposals exhibit a specification gap between the stated goals of data transparency and the actual disclosures necessary to achieve such goals. Second, reform attempts exhibit an enforcement gap between required disclosures on paper and enforcement to ensure compliance in fact. Third, policy proposals manifest an impact gap between disclosed information and meaningful changes in developer practices and public understanding. Informed by the social science on transparency, our analysis identifies affirmative paths for transparency that are effective rather than merely symbolic.
CoPE: A Small Language Model for Steerable and Scalable Content Labeling
Dec 19, 2025



This paper details the methodology behind CoPE, a policy-steerable small language model capable of fast and accurate content labeling. We present a novel training curricula called Contradictory Example Training that enables the model to learn policy interpretation rather than mere policy memorization. We also present a novel method for generating content policies, called Binocular Labeling, which enables rapid construction of unambiguous training datasets. When evaluated across seven different harm areas, CoPE exhibits equal or superior accuracy to frontier models at only 1% of their size. We openly release a 9 billion parameter version of the model that can be run on a single consumer-grade GPU. Models like CoPE represent a paradigm shift for classifier systems. By turning an ML task into a policy writing task, CoPE opens up new design possibilities for the governance of online platforms.
The 2025 Foundation Model Transparency Index
Dec 11, 2025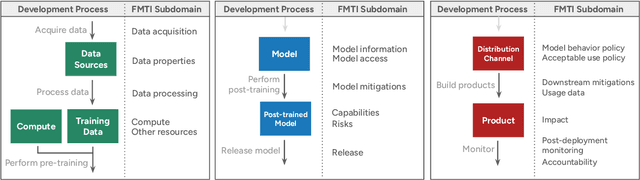
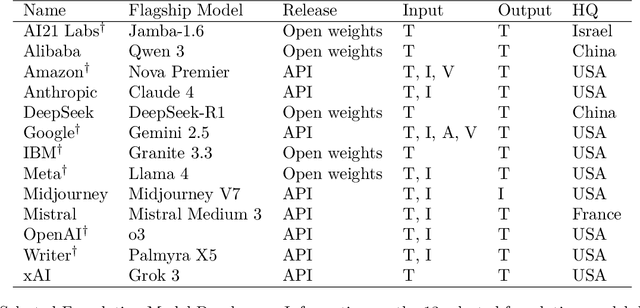
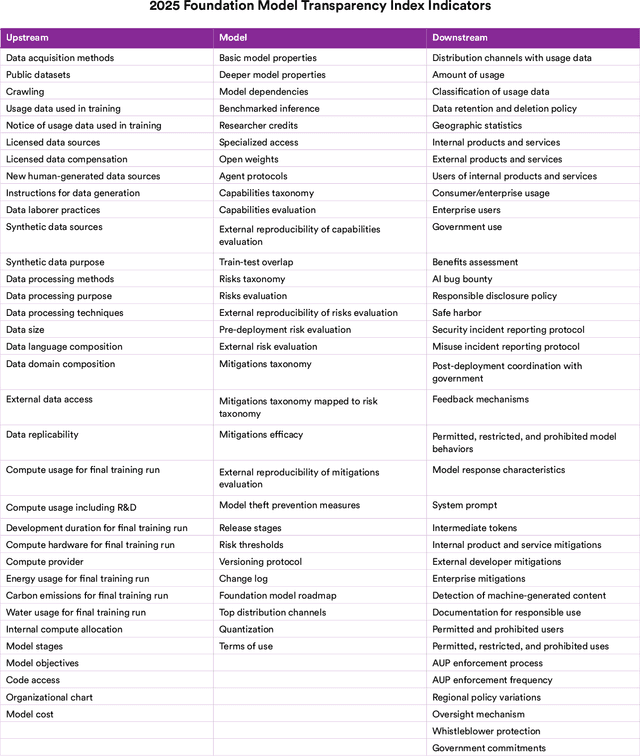
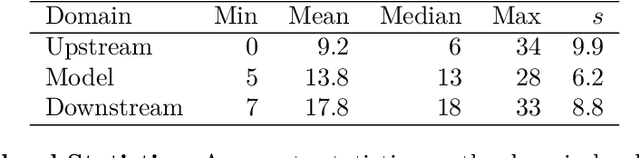
Foundation model developers are among the world's most important companies. As these companies become increasingly consequential, how do their transparency practices evolve? The 2025 Foundation Model Transparency Index is the third edition of an annual effort to characterize and quantify the transparency of foundation model developers. The 2025 FMTI introduces new indicators related to data acquisition, usage data, and monitoring and evaluates companies like Alibaba, DeepSeek, and xAI for the first time. The 2024 FMTI reported that transparency was improving, but the 2025 FMTI finds this progress has deteriorated: the average score out of 100 fell from 58 in 2024 to 40 in 2025. Companies are most opaque about their training data and training compute as well as the post-deployment usage and impact of their flagship models. In spite of this general trend, IBM stands out as a positive outlier, scoring 95, in contrast to the lowest scorers, xAI and Midjourney, at just 14. The five members of the Frontier Model Forum we score end up in the middle of the Index: we posit that these companies avoid reputational harms from low scores but lack incentives to be transparency leaders. As policymakers around the world increasingly mandate certain types of transparency, this work reveals the current state of transparency for foundation model developers, how it may change given newly enacted policy, and where more aggressive policy interventions are necessary to address critical information deficits.
Who Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
Do AI Companies Make Good on Voluntary Commitments to the White House?
Aug 11, 2025Voluntary commitments are central to international AI governance, as demonstrated by recent voluntary guidelines from the White House to the G7, from Bletchley Park to Seoul. How do major AI companies make good on their commitments? We score companies based on their publicly disclosed behavior by developing a detailed rubric based on their eight voluntary commitments to the White House in 2023. We find significant heterogeneity: while the highest-scoring company (OpenAI) scores a 83% overall on our rubric, the average score across all companies is just 52%. The companies demonstrate systemically poor performance for their commitment to model weight security with an average score of 17%: 11 of the 16 companies receive 0% for this commitment. Our analysis highlights a clear structural shortcoming that future AI governance initiatives should correct: when companies make public commitments, they should proactively disclose how they meet their commitments to provide accountability, and these disclosures should be verifiable. To advance policymaking on corporate AI governance, we provide three directed recommendations that address underspecified commitments, the role of complex AI supply chains, and public transparency that could be applied towards AI governance initiatives worldwide.
New Tools are Needed for Tracking Adherence to AI Model Behavioral Use Clauses
May 28, 2025



Foundation models have had a transformative impact on AI. A combination of large investments in research and development, growing sources of digital data for training, and architectures that scale with data and compute has led to models with powerful capabilities. Releasing assets is fundamental to scientific advancement and commercial enterprise. However, concerns over negligent or malicious uses of AI have led to the design of mechanisms to limit the risks of the technology. The result has been a proliferation of licenses with behavioral-use clauses and acceptable-use-policies that are increasingly being adopted by commonly used families of models (Llama, Gemma, Deepseek) and a myriad of smaller projects. We created and deployed a custom AI licenses generator to facilitate license creation and have quantitatively and qualitatively analyzed over 300 customized licenses created with this tool. Alongside this we analyzed 1.7 million models licenses on the HuggingFace model hub. Our results show increasing adoption of these licenses, interest in tools that support their creation and a convergence on common clause configurations. In this paper we take the position that tools for tracking adoption of, and adherence to, these licenses is the natural next step and urgently needed in order to ensure they have the desired impact of ensuring responsible use.
Expressing stigma and inappropriate responses prevents LLMs from safely replacing mental health providers
Apr 25, 2025Should a large language model (LLM) be used as a therapist? In this paper, we investigate the use of LLMs to *replace* mental health providers, a use case promoted in the tech startup and research space. We conduct a mapping review of therapy guides used by major medical institutions to identify crucial aspects of therapeutic relationships, such as the importance of a therapeutic alliance between therapist and client. We then assess the ability of LLMs to reproduce and adhere to these aspects of therapeutic relationships by conducting several experiments investigating the responses of current LLMs, such as `gpt-4o`. Contrary to best practices in the medical community, LLMs 1) express stigma toward those with mental health conditions and 2) respond inappropriately to certain common (and critical) conditions in naturalistic therapy settings -- e.g., LLMs encourage clients' delusional thinking, likely due to their sycophancy. This occurs even with larger and newer LLMs, indicating that current safety practices may not address these gaps. Furthermore, we note foundational and practical barriers to the adoption of LLMs as therapists, such as that a therapeutic alliance requires human characteristics (e.g., identity and stakes). For these reasons, we conclude that LLMs should not replace therapists, and we discuss alternative roles for LLMs in clinical therapy.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.