 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Persuasion: What Influences Decisions of Vision-Language Models?
Feb 17, 2026The web is littered with images, once created for human consumption and now increasingly interpreted by agents using vision-language models (VLMs). These agents make visual decisions at scale, deciding what to click, recommend, or buy. Yet, we know little about the structure of their visual preferences. We introduce a framework for studying this by placing VLMs in controlled image-based choice tasks and systematically perturbing their inputs. Our key idea is to treat the agent's decision function as a latent visual utility that can be inferred through revealed preference: choices between systematically edited images. Starting from common images, such as product photos, we propose methods for visual prompt optimization, adapting text optimization methods to iteratively propose and apply visually plausible modifications using an image generation model (such as in composition, lighting, or background). We then evaluate which edits increase selection probability. Through large-scale experiments on frontier VLMs, we demonstrate that optimized edits significantly shift choice probabilities in head-to-head comparisons. We develop an automatic interpretability pipeline to explain these preferences, identifying consistent visual themes that drive selection. We argue that this approach offers a practical and efficient way to surface visual vulnerabilities, safety concerns that might otherwise be discovered implicitly in the wild, supporting more proactive auditing and governance of image-based AI agents.
LLM Agents Are Hypersensitive to Nudges
May 16, 2025LLMs are being set loose in complex, real-world environments involving sequential decision-making and tool use. Often, this involves making choices on behalf of human users. However, not much is known about the distribution of such choices, and how susceptible they are to different choice architectures. We perform a case study with a few such LLM models on a multi-attribute tabular decision-making problem, under canonical nudges such as the default option, suggestions, and information highlighting, as well as additional prompting strategies. We show that, despite superficial similarities to human choice distributions, such models differ in subtle but important ways. First, they show much higher susceptibility to the nudges. Second, they diverge in points earned, being affected by factors like the idiosyncrasy of available prizes. Third, they diverge in information acquisition strategies: e.g. incurring substantial cost to reveal too much information, or selecting without revealing any. Moreover, we show that simple prompt strategies like zero-shot chain of thought (CoT) can shift the choice distribution, and few-shot prompting with human data can induce greater alignment. Yet, none of these methods resolve the sensitivity of these models to nudges. Finally, we show how optimal nudges optimized with a human resource-rational model can similarly increase LLM performance for some models. All these findings suggest that behavioral tests are needed before deploying models as agents or assistants acting on behalf of users in complex environments.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


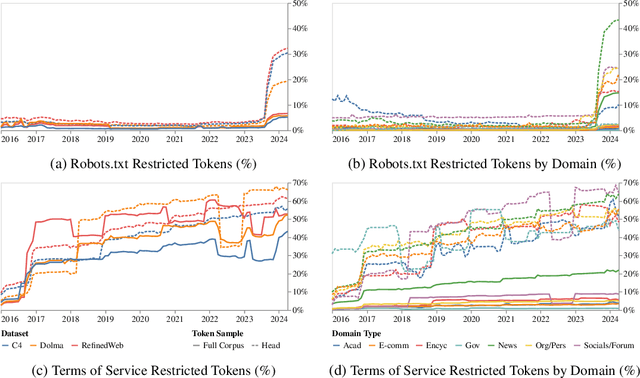
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
Contrastive Learning from Synthetic Audio Doppelgangers
Jun 09, 2024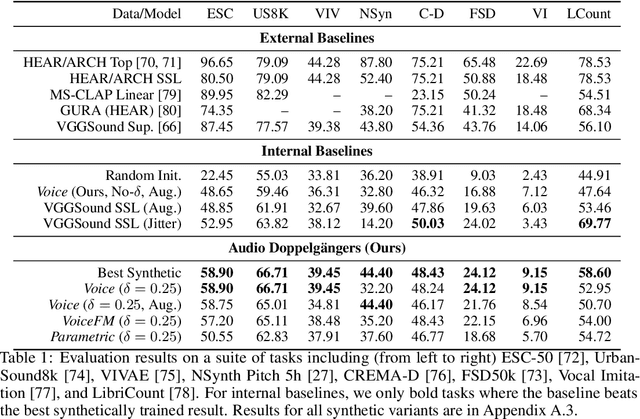
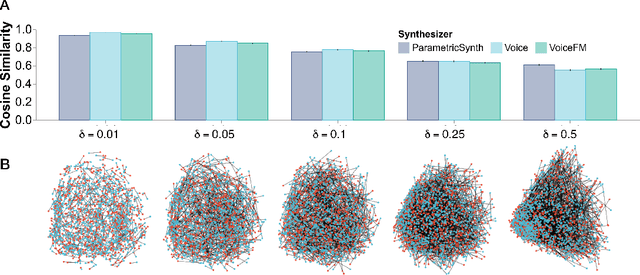
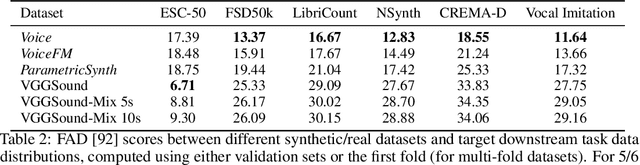
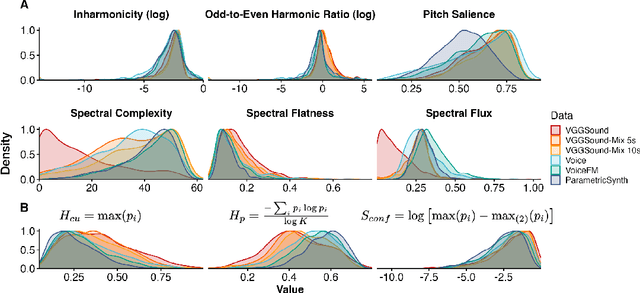
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelg\"angers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
Creative Text-to-Audio Generation via Synthesizer Programming
Jun 01, 2024Neural audio synthesis methods now allow specifying ideas in natural language. However, these methods produce results that cannot be easily tweaked, as they are based on large latent spaces and up to billions of uninterpretable parameters. We propose a text-to-audio generation method that leverages a virtual modular sound synthesizer with only 78 parameters. Synthesizers have long been used by skilled sound designers for media like music and film due to their flexibility and intuitive controls. Our method, CTAG, iteratively updates a synthesizer's parameters to produce high-quality audio renderings of text prompts that can be easily inspected and tweaked. Sounds produced this way are also more abstract, capturing essential conceptual features over fine-grained acoustic details, akin to how simple sketches can vividly convey visual concepts. Our results show how CTAG produces sounds that are distinctive, perceived as artistic, and yet similarly identifiable to recent neural audio synthesis models, positioning it as a valuable and complementary tool.