 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Reading-Induced Confusion Using EEG and Eye Tracking
Aug 20, 2025



Humans regularly navigate an overwhelming amount of information via text media, whether reading articles, browsing social media, or interacting with chatbots. Confusion naturally arises when new information conflicts with or exceeds a reader's comprehension or prior knowledge, posing a challenge for learning. In this study, we present a multimodal investigation of reading-induced confusion using EEG and eye tracking. We collected neural and gaze data from 11 adult participants as they read short paragraphs sampled from diverse, real-world sources. By isolating the N400 event-related potential (ERP), a well-established neural marker of semantic incongruence, and integrating behavioral markers from eye tracking, we provide a detailed analysis of the neural and behavioral correlates of confusion during naturalistic reading. Using machine learning, we show that multimodal (EEG + eye tracking) models improve classification accuracy by 4-22% over unimodal baselines, reaching an average weighted participant accuracy of 77.3% and a best accuracy of 89.6%. Our results highlight the dominance of the brain's temporal regions in these neural signatures of confusion, suggesting avenues for wearable, low-electrode brain-computer interfaces (BCI) for real-time monitoring. These findings lay the foundation for developing adaptive systems that dynamically detect and respond to user confusion, with potential applications in personalized learning, human-computer interaction, and accessibility.
Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task
Jun 10, 2025This study explores the neural and behavioral consequences of LLM-assisted essay writing. Participants were divided into three groups: LLM, Search Engine, and Brain-only (no tools). Each completed three sessions under the same condition. In a fourth session, LLM users were reassigned to Brain-only group (LLM-to-Brain), and Brain-only users were reassigned to LLM condition (Brain-to-LLM). A total of 54 participants took part in Sessions 1-3, with 18 completing session 4. We used electroencephalography (EEG) to assess cognitive load during essay writing, and analyzed essays using NLP, as well as scoring essays with the help from human teachers and an AI judge. Across groups, NERs, n-gram patterns, and topic ontology showed within-group homogeneity. EEG revealed significant differences in brain connectivity: Brain-only participants exhibited the strongest, most distributed networks; Search Engine users showed moderate engagement; and LLM users displayed the weakest connectivity. Cognitive activity scaled down in relation to external tool use. In session 4, LLM-to-Brain participants showed reduced alpha and beta connectivity, indicating under-engagement. Brain-to-LLM users exhibited higher memory recall and activation of occipito-parietal and prefrontal areas, similar to Search Engine users. Self-reported ownership of essays was the lowest in the LLM group and the highest in the Brain-only group. LLM users also struggled to accurately quote their own work. While LLMs offer immediate convenience, our findings highlight potential cognitive costs. Over four months, LLM users consistently underperformed at neural, linguistic, and behavioral levels. These results raise concerns about the long-term educational implications of LLM reliance and underscore the need for deeper inquiry into AI's role in learning.
EmoSign: A Multimodal Dataset for Understanding Emotions in American Sign Language
May 20, 2025Unlike spoken languages where the use of prosodic features to convey emotion is well studied, indicators of emotion in sign language remain poorly understood, creating communication barriers in critical settings. Sign languages present unique challenges as facial expressions and hand movements simultaneously serve both grammatical and emotional functions. To address this gap, we introduce EmoSign, the first sign video dataset containing sentiment and emotion labels for 200 American Sign Language (ASL) videos. We also collect open-ended descriptions of emotion cues. Annotations were done by 3 Deaf ASL signers with professional interpretation experience. Alongside the annotations, we include baseline models for sentiment and emotion classification. This dataset not only addresses a critical gap in existing sign language research but also establishes a new benchmark for understanding model capabilities in multimodal emotion recognition for sign languages. The dataset is made available at https://huggingface.co/datasets/catfang/emosign.
LLM Agents Are Hypersensitive to Nudges
May 16, 2025LLMs are being set loose in complex, real-world environments involving sequential decision-making and tool use. Often, this involves making choices on behalf of human users. However, not much is known about the distribution of such choices, and how susceptible they are to different choice architectures. We perform a case study with a few such LLM models on a multi-attribute tabular decision-making problem, under canonical nudges such as the default option, suggestions, and information highlighting, as well as additional prompting strategies. We show that, despite superficial similarities to human choice distributions, such models differ in subtle but important ways. First, they show much higher susceptibility to the nudges. Second, they diverge in points earned, being affected by factors like the idiosyncrasy of available prizes. Third, they diverge in information acquisition strategies: e.g. incurring substantial cost to reveal too much information, or selecting without revealing any. Moreover, we show that simple prompt strategies like zero-shot chain of thought (CoT) can shift the choice distribution, and few-shot prompting with human data can induce greater alignment. Yet, none of these methods resolve the sensitivity of these models to nudges. Finally, we show how optimal nudges optimized with a human resource-rational model can similarly increase LLM performance for some models. All these findings suggest that behavioral tests are needed before deploying models as agents or assistants acting on behalf of users in complex environments.
Investigating Affective Use and Emotional Well-being on ChatGPT
Apr 04, 2025As AI chatbots see increased adoption and integration into everyday life, questions have been raised about the potential impact of human-like or anthropomorphic AI on users. In this work, we investigate the extent to which interactions with ChatGPT (with a focus on Advanced Voice Mode) may impact users' emotional well-being, behaviors and experiences through two parallel studies. To study the affective use of AI chatbots, we perform large-scale automated analysis of ChatGPT platform usage in a privacy-preserving manner, analyzing over 3 million conversations for affective cues and surveying over 4,000 users on their perceptions of ChatGPT. To investigate whether there is a relationship between model usage and emotional well-being, we conduct an Institutional Review Board (IRB)-approved randomized controlled trial (RCT) on close to 1,000 participants over 28 days, examining changes in their emotional well-being as they interact with ChatGPT under different experimental settings. In both on-platform data analysis and the RCT, we observe that very high usage correlates with increased self-reported indicators of dependence. From our RCT, we find that the impact of voice-based interactions on emotional well-being to be highly nuanced, and influenced by factors such as the user's initial emotional state and total usage duration. Overall, our analysis reveals that a small number of users are responsible for a disproportionate share of the most affective cues.
Resonance: Drawing from Memories to Imagine Positive Futures through AI-Augmented Journaling
Mar 31, 2025



People inherently use experiences of their past while imagining their future, a capability that plays a crucial role in mental health. Resonance is an AI-powered journaling tool designed to augment this ability by offering AI-generated, action-oriented suggestions for future activities based on the user's own past memories. Suggestions are offered when a new memory is logged and are followed by a prompt for the user to imagine carrying out the suggestion. In a two-week randomized controlled study (N=55), we found that using Resonance significantly improved mental health outcomes, reducing the users' PHQ8 scores, a measure of current depression, and increasing their daily positive affect, particularly when they would likely act on the suggestion. Notably, the effectiveness of the suggestions was higher when they were personal, novel, and referenced the user's logged memories. Finally, through open-ended feedback, we discuss the factors that encouraged or hindered the use of the tool.
* 17 pages, 13 figures
NeuroChat: A Neuroadaptive AI Chatbot for Customizing Learning Experiences
Mar 10, 2025

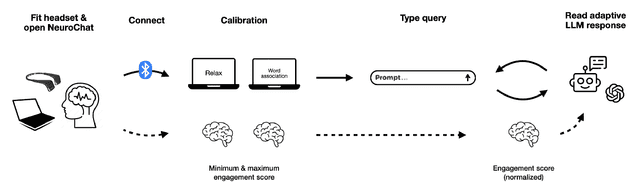

Generative AI is transforming education by enabling personalized, on-demand learning experiences. However, AI tutors lack the ability to assess a learner's cognitive state in real time, limiting their adaptability. Meanwhile, electroencephalography (EEG)-based neuroadaptive systems have successfully enhanced engagement by dynamically adjusting learning content. This paper presents NeuroChat, a proof-of-concept neuroadaptive AI tutor that integrates real-time EEG-based engagement tracking with generative AI. NeuroChat continuously monitors a learner's cognitive engagement and dynamically adjusts content complexity, response style, and pacing using a closed-loop system. We evaluate this approach in a pilot study (n=24), comparing NeuroChat to a standard LLM-based chatbot. Results indicate that NeuroChat enhances cognitive and subjective engagement but does not show an immediate effect on learning outcomes. These findings demonstrate the feasibility of real-time cognitive feedback in LLMs, highlighting new directions for adaptive learning, AI tutoring, and human-AI interaction.
AI persuading AI vs AI persuading Humans: LLMs' Differential Effectiveness in Promoting Pro-Environmental Behavior
Mar 03, 2025



Pro-environmental behavior (PEB) is vital to combat climate change, yet turning awareness into intention and action remains elusive. We explore large language models (LLMs) as tools to promote PEB, comparing their impact across 3,200 participants: real humans (n=1,200), simulated humans based on actual participant data (n=1,200), and fully synthetic personas (n=1,200). All three participant groups faced personalized or standard chatbots, or static statements, employing four persuasion strategies (moral foundations, future self-continuity, action orientation, or "freestyle" chosen by the LLM). Results reveal a "synthetic persuasion paradox": synthetic and simulated agents significantly affect their post-intervention PEB stance, while human responses barely shift. Simulated participants better approximate human trends but still overestimate effects. This disconnect underscores LLM's potential for pre-evaluating PEB interventions but warns of its limits in predicting real-world behavior. We call for refined synthetic modeling and sustained and extended human trials to align conversational AI's promise with tangible sustainability outcomes.
OceanChat: The Effect of Virtual Conversational AI Agents on Sustainable Attitude and Behavior Change
Feb 05, 2025



Marine ecosystems face unprecedented threats from climate change and plastic pollution, yet traditional environmental education often struggles to translate awareness into sustained behavioral change. This paper presents OceanChat, an interactive system leveraging large language models to create conversational AI agents represented as animated marine creatures -- specifically a beluga whale, a jellyfish, and a seahorse -- designed to promote environmental behavior (PEB) and foster awareness through personalized dialogue. Through a between-subjects experiment (N=900), we compared three conditions: (1) Static Scientific Information, providing conventional environmental education through text and images; (2) Static Character Narrative, featuring first-person storytelling from 3D-rendered marine creatures; and (3) Conversational Character Narrative, enabling real-time dialogue with AI-powered marine characters. Our analysis revealed that the Conversational Character Narrative condition significantly increased behavioral intentions and sustainable choice preferences compared to static approaches. The beluga whale character demonstrated consistently stronger emotional engagement across multiple measures, including perceived anthropomorphism and empathy. However, impacts on deeper measures like climate policy support and psychological distance were limited, highlighting the complexity of shifting entrenched beliefs. Our work extends research on sustainability interfaces facilitating PEB and offers design principles for creating emotionally resonant, context-aware AI characters. By balancing anthropomorphism with species authenticity, OceanChat demonstrates how interactive narratives can bridge the gap between environmental knowledge and real-world behavior change.
Synthetic Human Memories: AI-Edited Images and Videos Can Implant False Memories and Distort Recollection
Sep 13, 2024

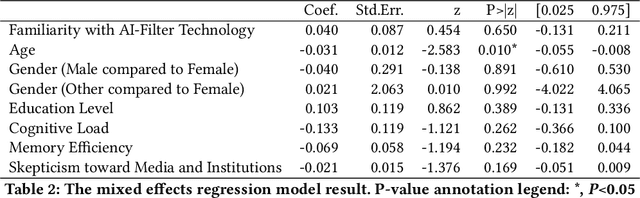

AI is increasingly used to enhance images and videos, both intentionally and unintentionally. As AI editing tools become more integrated into smartphones, users can modify or animate photos into realistic videos. This study examines the impact of AI-altered visuals on false memories--recollections of events that didn't occur or deviate from reality. In a pre-registered study, 200 participants were divided into four conditions of 50 each. Participants viewed original images, completed a filler task, then saw stimuli corresponding to their assigned condition: unedited images, AI-edited images, AI-generated videos, or AI-generated videos of AI-edited images. AI-edited visuals significantly increased false recollections, with AI-generated videos of AI-edited images having the strongest effect (2.05x compared to control). Confidence in false memories was also highest for this condition (1.19x compared to control). We discuss potential applications in HCI, such as therapeutic memory reframing, and challenges in ethical, legal, political, and societal domains.