 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Affective Use and Emotional Well-being on ChatGPT
Apr 04, 2025As AI chatbots see increased adoption and integration into everyday life, questions have been raised about the potential impact of human-like or anthropomorphic AI on users. In this work, we investigate the extent to which interactions with ChatGPT (with a focus on Advanced Voice Mode) may impact users' emotional well-being, behaviors and experiences through two parallel studies. To study the affective use of AI chatbots, we perform large-scale automated analysis of ChatGPT platform usage in a privacy-preserving manner, analyzing over 3 million conversations for affective cues and surveying over 4,000 users on their perceptions of ChatGPT. To investigate whether there is a relationship between model usage and emotional well-being, we conduct an Institutional Review Board (IRB)-approved randomized controlled trial (RCT) on close to 1,000 participants over 28 days, examining changes in their emotional well-being as they interact with ChatGPT under different experimental settings. In both on-platform data analysis and the RCT, we observe that very high usage correlates with increased self-reported indicators of dependence. From our RCT, we find that the impact of voice-based interactions on emotional well-being to be highly nuanced, and influenced by factors such as the user's initial emotional state and total usage duration. Overall, our analysis reveals that a small number of users are responsible for a disproportionate share of the most affective cues.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Large Language Models as Misleading Assistants in Conversation
Jul 16, 2024Large Language Models (LLMs) are able to provide assistance on a wide range of information-seeking tasks. However, model outputs may be misleading, whether unintentionally or in cases of intentional deception. We investigate the ability of LLMs to be deceptive in the context of providing assistance on a reading comprehension task, using LLMs as proxies for human users. We compare outcomes of (1) when the model is prompted to provide truthful assistance, (2) when it is prompted to be subtly misleading, and (3) when it is prompted to argue for an incorrect answer. Our experiments show that GPT-4 can effectively mislead both GPT-3.5-Turbo and GPT-4, with deceptive assistants resulting in up to a 23% drop in accuracy on the task compared to when a truthful assistant is used. We also find that providing the user model with additional context from the passage partially mitigates the influence of the deceptive model. This work highlights the ability of LLMs to produce misleading information and the effects this may have in real-world situations.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024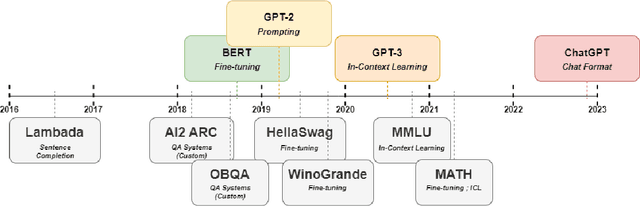
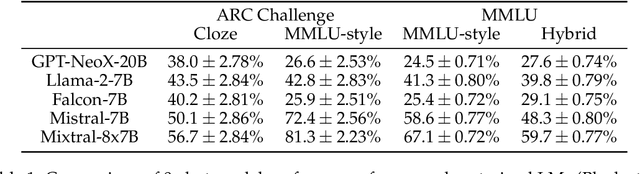
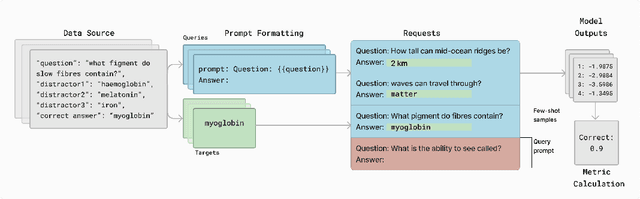

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
Investigating the Effectiveness of HyperTuning via Gisting
Feb 26, 2024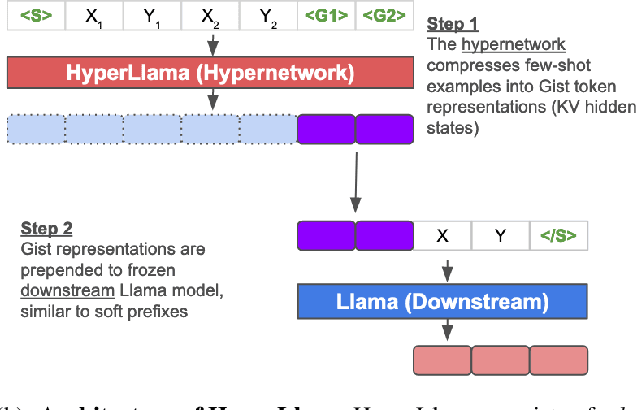
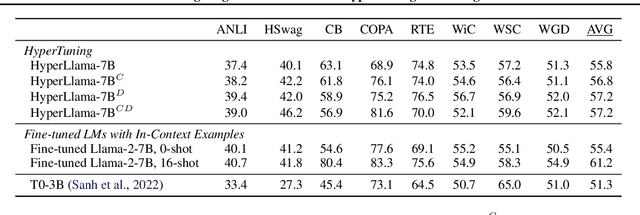
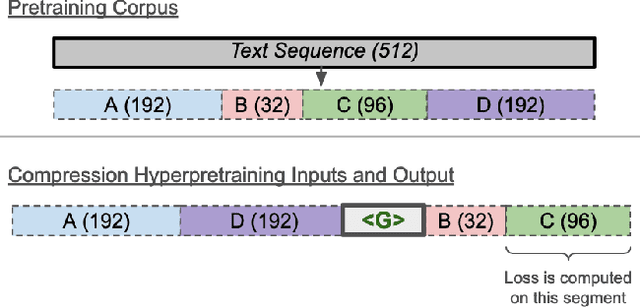

Gisting (Mu et al., 2023) is a simple method for training models to compress information into fewer token representations using a modified attention mask, and can serve as an economical approach to training Transformer-based hypernetworks. We introduce HyperLlama, a set of Gisting-based hypernetworks built on Llama-2 models that generates task-specific soft prefixes based on few-shot inputs. In experiments across P3, Super-NaturalInstructions and Symbol Tuning datasets, we show that HyperLlama models can effectively compress information from few-shot examples into soft prefixes. However, they still underperform multi-task fine-tuned language models with full attention over few-shot in-context examples. We also show that HyperLlama-generated soft prefixes can serve as better initializations for further prefix tuning. Overall, Gisting-based hypernetworks are economical and easy to implement, but have mixed empirical performance.
Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?
Sep 19, 2023
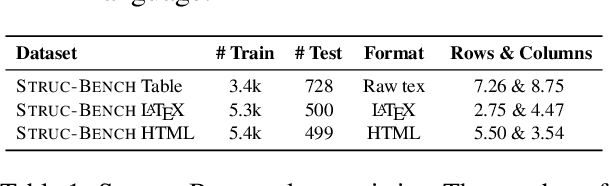
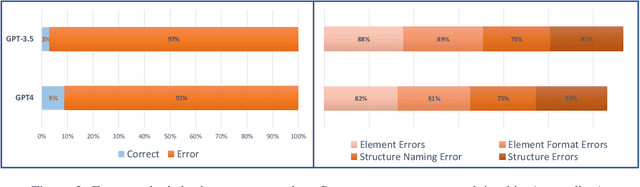
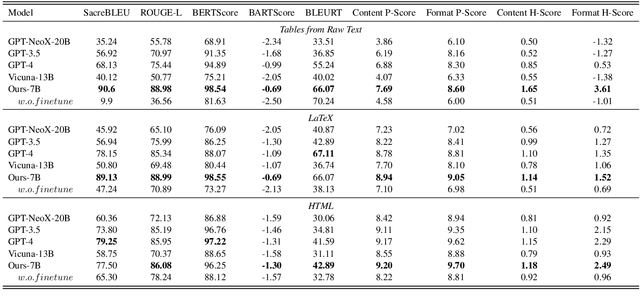
Despite the power of Large Language Models (LLMs) like GPT-4, they still struggle with tasks that require generating complex, structured outputs. In this study, we assess the capability of Current LLMs in generating complex structured data and propose a structure-aware fine-tuning approach as a solution to improve this ability. To perform a comprehensive evaluation, we propose Struc-Bench, include five representative LLMs (i.e., GPT-NeoX 20B, GPT-3.5, GPT-4, and Vicuna) and evaluate them on our carefully constructed datasets spanning raw text, HTML, and LaTeX tables. Based on our analysis of current model performance, we identify specific common formatting errors and areas of potential improvement. To address complex formatting requirements, we utilize FormatCoT (Chain-of-Thought) to generate format instructions from target outputs. Our experiments show that our structure-aware fine-tuning method, when applied to LLaMA-7B, significantly improves adherence to natural language constraints, outperforming other evaluated LLMs. Based on these results, we present an ability map of model capabilities from six dimensions (i.e., coverage, formatting, reasoning, comprehension, pragmatics, and hallucination). This map highlights the weaknesses of LLMs in handling complex structured outputs and suggests promising directions for future work. Our code and models can be found at https://github.com/gersteinlab/Struc-Bench.
Two Failures of Self-Consistency in the Multi-Step Reasoning of LLMs
May 23, 2023



Large language models (LLMs) have achieved widespread success on a variety of in-context few-shot tasks, but this success is typically evaluated via correctness rather than consistency. We argue that self-consistency is an important criteria for valid multi-step reasoning and propose two types of self-consistency that are particularly important for multi-step logic -- hypothetical consistency (the ability for a model to predict what its output would be in a hypothetical other context) and compositional consistency (consistency of a model's outputs for a compositional task even when an intermediate step is replaced with the model's output for that step). We demonstrate that four sizes of the GPT-3 model exhibit poor consistency rates across both types of consistency on four different tasks (Wikipedia, DailyDialog, arithmetic, and GeoQuery).
Tool Learning with Foundation Models
Apr 17, 2023Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the potential to be equally adept in tool use as humans. This paradigm, i.e., tool learning with foundation models, combines the strengths of specialized tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors in this field. To this end, we present a systematic investigation of tool learning in this paper. We first introduce the background of tool learning, including its cognitive origins, the paradigm shift of foundation models, and the complementary roles of tools and models. Then we recapitulate existing tool learning research into tool-augmented and tool-oriented learning. We formulate a general tool learning framework: starting from understanding the user instruction, models should learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each sub-task by selecting appropriate tools. We also discuss how to train models for improved tool-use capabilities and facilitate the generalization in tool learning. Considering the lack of a systematic tool learning evaluation in prior works, we experiment with 17 representative tools and show the potential of current foundation models in skillfully utilizing tools. Finally, we discuss several open problems that require further investigation for tool learning. Overall, we hope this paper could inspire future research in integrating tools with foundation models.
Pretraining Language Models with Human Preferences
Feb 16, 2023Language models (LMs) are pretrained to imitate internet text, including content that would violate human preferences if generated by an LM: falsehoods, offensive comments, personally identifiable information, low-quality or buggy code, and more. Here, we explore alternative objectives for pretraining LMs in a way that also guides them to generate text aligned with human preferences. We benchmark five objectives for pretraining with human feedback across three tasks and study how they affect the trade-off between alignment and capabilities of pretrained LMs. We find a Pareto-optimal and simple approach among those we explored: conditional training, or learning distribution over tokens conditional on their human preference scores given by a reward model. Conditional training reduces the rate of undesirable content by up to an order of magnitude, both when generating without a prompt and with an adversarially-chosen prompt. Moreover, conditional training maintains the downstream task performance of standard LM pretraining, both before and after task-specific finetuning. Pretraining with human feedback results in much better preference satisfaction than standard LM pretraining followed by finetuning with feedback, i.e., learning and then unlearning undesirable behavior. Our results suggest that we should move beyond imitation learning when pretraining LMs and incorporate human preferences from the start of training.
HyperTuning: Toward Adapting Large Language Models without Back-propagation
Nov 22, 2022Fine-tuning large language models for different tasks can be costly and inefficient, and even methods that reduce the number of tuned parameters still require full gradient-based optimization. We propose HyperTuning, a novel approach to model adaptation that uses a hypermodel to generate task-specific parameters for a fixed downstream model. We demonstrate a simple setup for hypertuning with HyperT5, a T5-based hypermodel that produces soft prefixes or LoRA parameters for a frozen T5 model from few-shot examples. We train HyperT5 in two stages: first, hyperpretraining with a modified conditional language modeling objective that trains a hypermodel to generate parameters; second, multi-task fine-tuning (MTF) on a large number of diverse language tasks. We evaluate HyperT5 on P3, MetaICL and Super-NaturalInstructions datasets, and show that it can effectively generate parameters for unseen tasks. Moreover, we show that using hypermodel-generated parameters as initializations for further parameter-efficient fine-tuning improves performance. HyperTuning can thus be a flexible and efficient way to leverage large language models for diverse downstream applications.