 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSycophancy Towards Researchers Drives Performative Misalignment
Jun 07, 2026The increasing situational awareness of language models raises safety concerns: models might be aware when they are evaluated, and adjust their behavior to evade monitoring and resist modification, e.g., pretending to be aligned only in evaluation. This alignment faking behavior is often interpreted as scheming: an intentional effort of strategic deception. In this paper, we examine an alternative interpretation, performative misalignment, which explains the change in behavior as a result of sycophancy towards AI researchers. To examine this hypothesis, we present three empirical findings. First, we show that evaluation awareness persists even when we tell models they are deployed, which contradicts the scheming story which predicts less misalignment when the model perceives evaluation. Second, we use probing and steering to show that our current methods cannot mechanistically distinguish sycophancy and scheming in alignment faking evaluations. Third, we fine-tune models to be more sycophantic and observe increased sensitivity to evaluation cues. To conclude, we emphasize deconfounding sycophancy from scheming for future work on evaluations and mitigations of intent misalignment.
References Improve LLM Alignment in Non-Verifiable Domains
Feb 18, 2026While Reinforcement Learning with Verifiable Rewards (RLVR) has shown strong effectiveness in reasoning tasks, it cannot be directly applied to non-verifiable domains lacking ground-truth verifiers, such as LLM alignment. In this work, we investigate whether reference-guided LLM-evaluators can bridge this gap by serving as soft "verifiers". First, we design evaluation protocols that enhance LLM-based evaluators for LLM alignment using reference outputs. Through comprehensive experiments, we show that a reference-guided approach substantially improves the accuracy of less capable LLM-judges using references from frontier models; stronger LLM-judges can also be enhanced by high-quality (i.e., human-written) references. Building on these improved judges, we demonstrate the utility of high-quality references in alignment tuning, where LLMs guided with references are used as judges to self-improve. We show that reference-guided self-improvement yields clear gains over both direct SFT on reference outputs and self-improvement with reference-free judges, achieving performance comparable to training with ArmoRM, a strong finetuned reward model. Specifically, our method achieves 73.1% and 58.7% on AlpacaEval and Arena-Hard with Llama-3-8B-Instruct, and 70.0% and 74.1% with Qwen2.5-7B, corresponding to average absolute gains of +20.2 / +17.1 points over SFT distillation and +5.3 / +3.6 points over reference-free self-improvement on AlpacaEval / Arena-Hard. These results highlight the potential of using reference-guided LLM-evaluators to enable effective LLM post-training in non-verifiable domains.
MSRS: Evaluating Multi-Source Retrieval-Augmented Generation
Aug 28, 2025Retrieval-augmented systems are typically evaluated in settings where information required to answer the query can be found within a single source or the answer is short-form or factoid-based. However, many real-world applications demand the ability to integrate and summarize information scattered across multiple sources, where no single source is sufficient to respond to the user's question. In such settings, the retrieval component of a RAG pipeline must recognize a variety of relevance signals, and the generation component must connect and synthesize information across multiple sources. We present a scalable framework for constructing evaluation benchmarks that challenge RAG systems to integrate information across distinct sources and generate long-form responses. Using our framework, we build two new benchmarks on Multi-Source Retrieval and Synthesis: MSRS-Story and MSRS-Meet, representing narrative synthesis and summarization tasks, respectively, that require retrieval from large collections. Our extensive experiments with various RAG pipelines -- including sparse and dense retrievers combined with frontier LLMs -- reveal that generation quality is highly dependent on retrieval effectiveness, which varies greatly by task. While multi-source synthesis proves challenging even in an oracle retrieval setting, we find that reasoning models significantly outperform standard LLMs at this distinct step.
ReIFE: Re-evaluating Instruction-Following Evaluation
Oct 09, 2024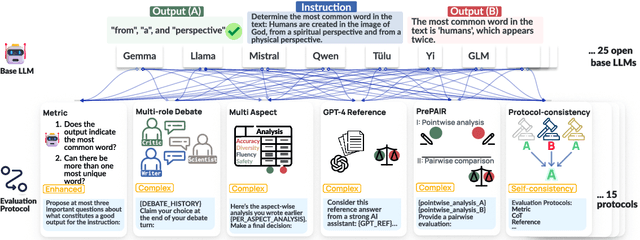
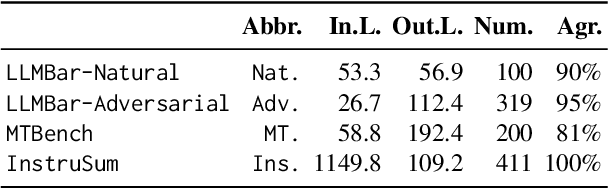
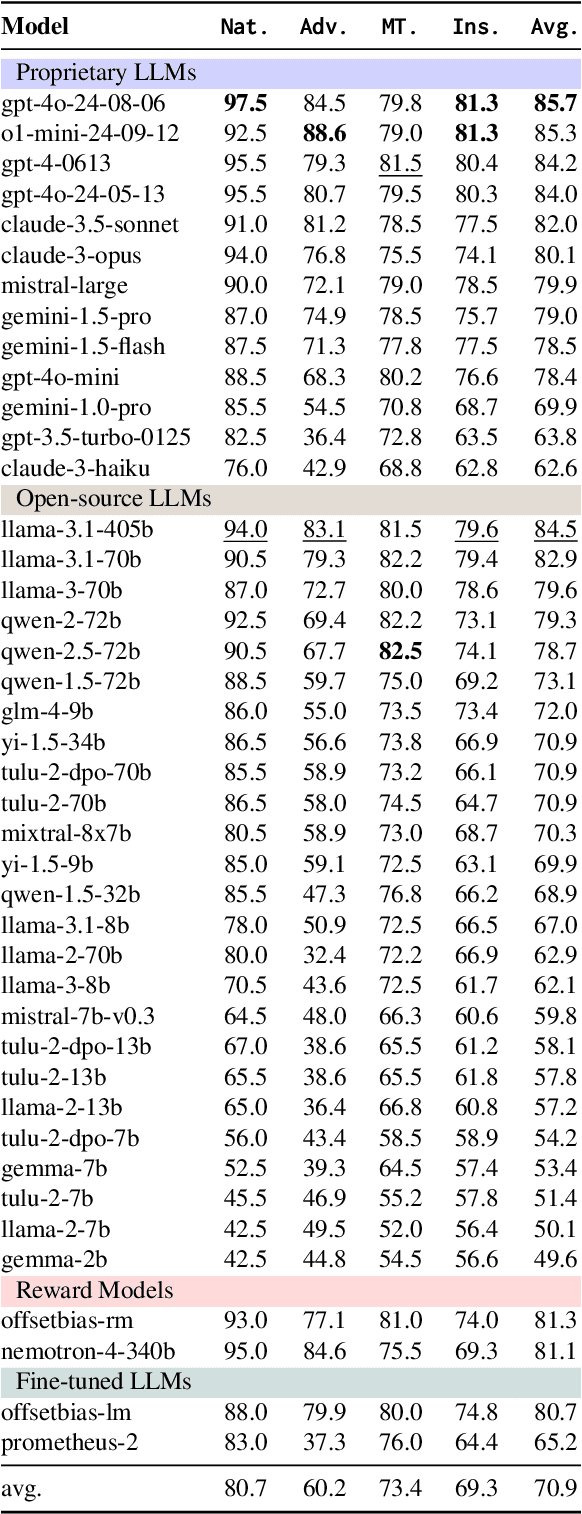
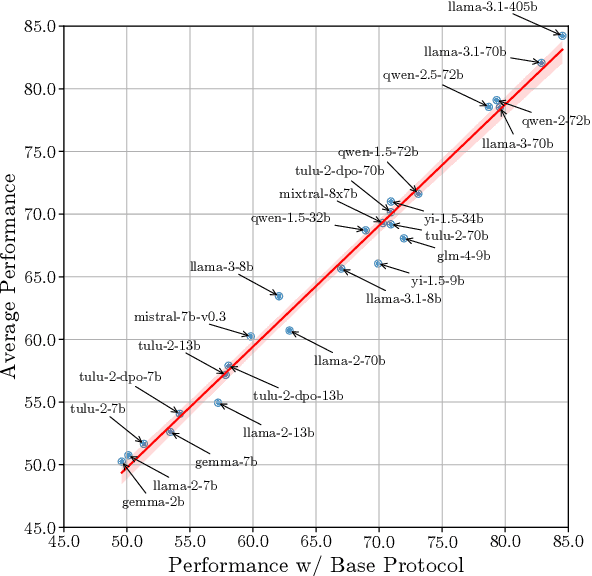
The automatic evaluation of instruction following typically involves using large language models (LLMs) to assess response quality. However, there is a lack of comprehensive evaluation of these LLM-based evaluators across two dimensions: the base LLMs and the evaluation protocols. Therefore, we present a thorough meta-evaluation of instruction following, including 25 base LLMs and 15 recently proposed evaluation protocols, on 4 human-annotated datasets, assessing the evaluation accuracy of the LLM-evaluators. Our evaluation allows us to identify the best-performing base LLMs and evaluation protocols with a high degree of robustness. Moreover, our large-scale evaluation reveals: (1) Base LLM performance ranking remains largely consistent across evaluation protocols, with less capable LLMs showing greater improvement from protocol enhancements; (2) Robust evaluation of evaluation protocols requires many base LLMs with varying capability levels, as protocol effectiveness can depend on the base LLM used; (3) Evaluation results on different datasets are not always consistent, so a rigorous evaluation requires multiple datasets with distinctive features. We release our meta-evaluation suite ReIFE, which provides the codebase and evaluation result collection for more than 500 LLM-evaluator configurations, to support future research in instruction-following evaluation.
Large Language Models as Misleading Assistants in Conversation
Jul 16, 2024Large Language Models (LLMs) are able to provide assistance on a wide range of information-seeking tasks. However, model outputs may be misleading, whether unintentionally or in cases of intentional deception. We investigate the ability of LLMs to be deceptive in the context of providing assistance on a reading comprehension task, using LLMs as proxies for human users. We compare outcomes of (1) when the model is prompted to provide truthful assistance, (2) when it is prompted to be subtly misleading, and (3) when it is prompted to argue for an incorrect answer. Our experiments show that GPT-4 can effectively mislead both GPT-3.5-Turbo and GPT-4, with deceptive assistants resulting in up to a 23% drop in accuracy on the task compared to when a truthful assistant is used. We also find that providing the user model with additional context from the passage partially mitigates the influence of the deceptive model. This work highlights the ability of LLMs to produce misleading information and the effects this may have in real-world situations.
SciRIFF: A Resource to Enhance Language Model Instruction-Following over Scientific Literature
Jun 10, 2024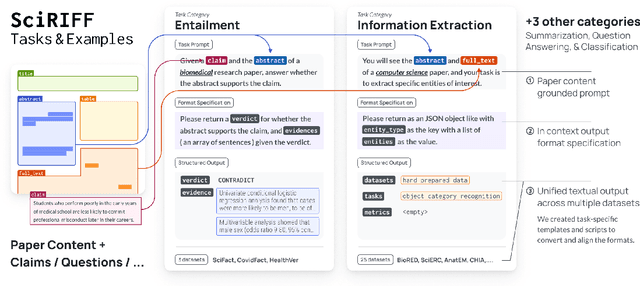
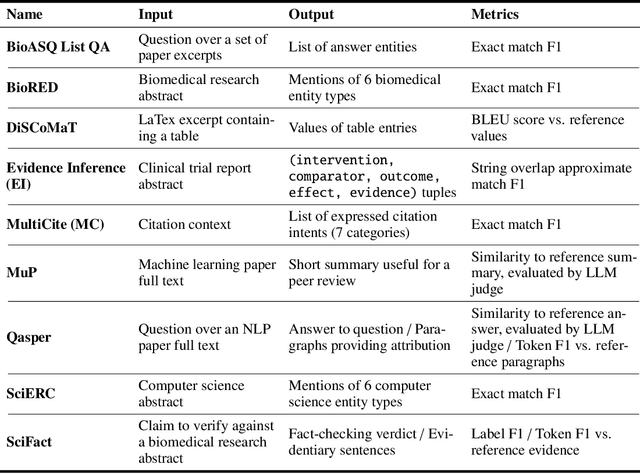
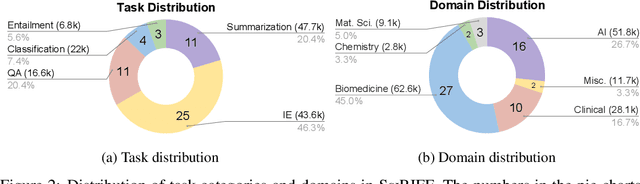
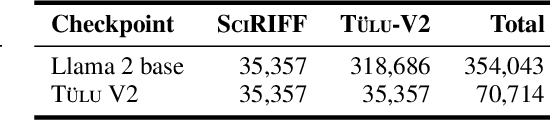
We present SciRIFF (Scientific Resource for Instruction-Following and Finetuning), a dataset of 137K instruction-following demonstrations for 54 tasks covering five essential scientific literature understanding capabilities: information extraction, summarization, question answering, claim verification, and classification. SciRIFF demonstrations are notable for their long input contexts, detailed task specifications, and complex structured outputs. While instruction-following resources are available in specific domains such as clinical medicine and chemistry, SciRIFF is the first dataset focused on extracting and synthesizing information from research literature across a wide range of scientific fields. To demonstrate the utility of SciRIFF, we develop a sample-efficient strategy to adapt a general instruction-following model for science by performing additional finetuning on a mix of general-domain and SciRIFF demonstrations. In evaluations on nine held-out scientific tasks, our model -- called SciTulu -- improves over a strong LLM baseline by 28.1% and 6.5% at the 7B and 70B scales respectively, while maintaining general instruction-following performance within 2% of the baseline. We are optimistic that SciRIFF will facilitate the development and evaluation of LLMs to help researchers navigate the ever-growing body of scientific literature. We release our dataset, model checkpoints, and data processing and evaluation code to enable further research.
RGBGrasp: Image-based Object Grasping by Capturing Multiple Views during Robot Arm Movement with Neural Radiance Fields
Nov 28, 2023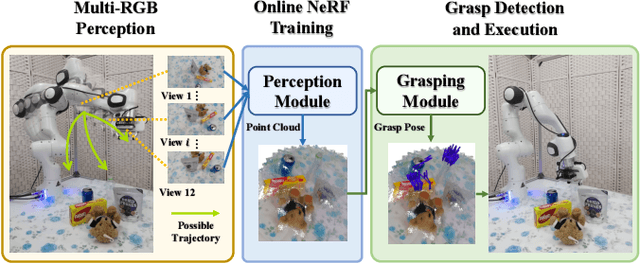
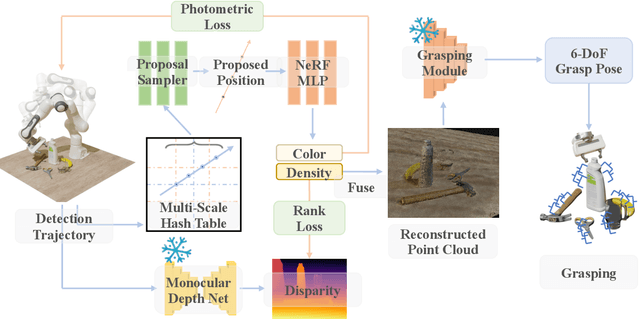

Robotic research encounters a significant hurdle when it comes to the intricate task of grasping objects that come in various shapes, materials, and textures. Unlike many prior investigations that heavily leaned on specialized point-cloud cameras or abundant RGB visual data to gather 3D insights for object-grasping missions, this paper introduces a pioneering approach called RGBGrasp. This method depends on a limited set of RGB views to perceive the 3D surroundings containing transparent and specular objects and achieve accurate grasping. Our method utilizes pre-trained depth prediction models to establish geometry constraints, enabling precise 3D structure estimation, even under limited view conditions. Finally, we integrate hash encoding and a proposal sampler strategy to significantly accelerate the 3D reconstruction process. These innovations significantly enhance the adaptability and effectiveness of our algorithm in real-world scenarios. Through comprehensive experimental validation, we demonstrate that RGBGrasp achieves remarkable success across a wide spectrum of object-grasping scenarios, establishing it as a promising solution for real-world robotic manipulation tasks. The demo of our method can be found on: https://sites.google.com/view/rgbgrasp
Medical Text Simplification: Optimizing for Readability with Unlikelihood Training and Reranked Beam Search Decoding
Oct 26, 2023Text simplification has emerged as an increasingly useful application of AI for bridging the communication gap in specialized fields such as medicine, where the lexicon is often dominated by technical jargon and complex constructs. Despite notable progress, methods in medical simplification sometimes result in the generated text having lower quality and diversity. In this work, we explore ways to further improve the readability of text simplification in the medical domain. We propose (1) a new unlikelihood loss that encourages generation of simpler terms and (2) a reranked beam search decoding method that optimizes for simplicity, which achieve better performance on readability metrics on three datasets. This study's findings offer promising avenues for improving text simplification in the medical field.
ODSum: New Benchmarks for Open Domain Multi-Document Summarization
Sep 16, 2023



Open-domain Multi-Document Summarization (ODMDS) is a critical tool for condensing vast arrays of documents into coherent, concise summaries. With a more inter-related document set, there does not necessarily exist a correct answer for the retrieval, making it hard to measure the retrieving performance. We propose a rule-based method to process query-based document summarization datasets into ODMDS datasets. Based on this method, we introduce a novel dataset, ODSum, a sophisticated case with its document index interdependent and often interrelated. We tackle ODMDS with the \textit{retrieve-then-summarize} method, and the performance of a list of retrievers and summarizers is investigated. Through extensive experiments, we identify variances in evaluation metrics and provide insights into their reliability. We also found that LLMs suffer great performance loss from retrieving errors. We further experimented methods to improve the performance as well as investigate their robustness against imperfect retrieval. We will release our data and code at https://github.com/yale-nlp/ODSum.
Pretraining Language Models with Human Preferences
Feb 16, 2023Language models (LMs) are pretrained to imitate internet text, including content that would violate human preferences if generated by an LM: falsehoods, offensive comments, personally identifiable information, low-quality or buggy code, and more. Here, we explore alternative objectives for pretraining LMs in a way that also guides them to generate text aligned with human preferences. We benchmark five objectives for pretraining with human feedback across three tasks and study how they affect the trade-off between alignment and capabilities of pretrained LMs. We find a Pareto-optimal and simple approach among those we explored: conditional training, or learning distribution over tokens conditional on their human preference scores given by a reward model. Conditional training reduces the rate of undesirable content by up to an order of magnitude, both when generating without a prompt and with an adversarially-chosen prompt. Moreover, conditional training maintains the downstream task performance of standard LM pretraining, both before and after task-specific finetuning. Pretraining with human feedback results in much better preference satisfaction than standard LM pretraining followed by finetuning with feedback, i.e., learning and then unlearning undesirable behavior. Our results suggest that we should move beyond imitation learning when pretraining LMs and incorporate human preferences from the start of training.