 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColorEcosystem: Powering Personalized, Standardized, and Trustworthy Agentic Service in massive-agent Ecosystem
Oct 27, 2025With the rapid development of (multimodal) large language model-based agents, the landscape of agentic service management has evolved from single-agent systems to multi-agent systems, and now to massive-agent ecosystems. Current massive-agent ecosystems face growing challenges, including impersonal service experiences, a lack of standardization, and untrustworthy behavior. To address these issues, we propose ColorEcosystem, a novel blueprint designed to enable personalized, standardized, and trustworthy agentic service at scale. Concretely, ColorEcosystem consists of three key components: agent carrier, agent store, and agent audit. The agent carrier provides personalized service experiences by utilizing user-specific data and creating a digital twin, while the agent store serves as a centralized, standardized platform for managing diverse agentic services. The agent audit, based on the supervision of developer and user activities, ensures the integrity and credibility of both service providers and users. Through the analysis of challenges, transitional forms, and practical considerations, the ColorEcosystem is poised to power personalized, standardized, and trustworthy agentic service across massive-agent ecosystems. Meanwhile, we have also implemented part of ColorEcosystem's functionality, and the relevant code is open-sourced at https://github.com/opas-lab/color-ecosystem.
VeriOS: Query-Driven Proactive Human-Agent-GUI Interaction for Trustworthy OS Agents
Sep 09, 2025With the rapid progress of multimodal large language models, operating system (OS) agents become increasingly capable of automating tasks through on-device graphical user interfaces (GUIs). However, most existing OS agents are designed for idealized settings, whereas real-world environments often present untrustworthy conditions. To mitigate risks of over-execution in such scenarios, we propose a query-driven human-agent-GUI interaction framework that enables OS agents to decide when to query humans for more reliable task completion. Built upon this framework, we introduce VeriOS-Agent, a trustworthy OS agent trained with a two-stage learning paradigm that falicitate the decoupling and utilization of meta-knowledge. Concretely, VeriOS-Agent autonomously executes actions in normal conditions while proactively querying humans in untrustworthy scenarios. Experiments show that VeriOS-Agent improves the average step-wise success rate by 20.64\% in untrustworthy scenarios over the state-of-the-art, without compromising normal performance. Analysis highlights VeriOS-Agent's rationality, generalizability, and scalability. The codes, datasets and models are available at https://github.com/Wuzheng02/VeriOS.
Quick on the Uptake: Eliciting Implicit Intents from Human Demonstrations for Personalized Mobile-Use Agents
Aug 12, 2025


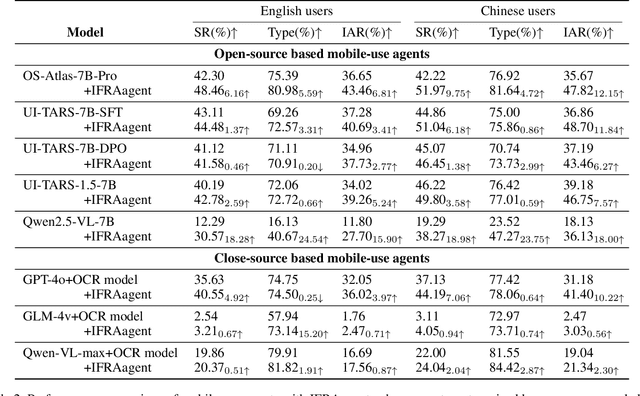
As multimodal large language models advance rapidly, the automation of mobile tasks has become increasingly feasible through the use of mobile-use agents that mimic human interactions from graphical user interface. To further enhance mobile-use agents, previous studies employ demonstration learning to improve mobile-use agents from human demonstrations. However, these methods focus solely on the explicit intention flows of humans (e.g., step sequences) while neglecting implicit intention flows (e.g., personal preferences), which makes it difficult to construct personalized mobile-use agents. In this work, to evaluate the \textbf{I}ntention \textbf{A}lignment \textbf{R}ate between mobile-use agents and humans, we first collect \textbf{MobileIAR}, a dataset containing human-intent-aligned actions and ground-truth actions. This enables a comprehensive assessment of the agents' understanding of human intent. Then we propose \textbf{IFRAgent}, a framework built upon \textbf{I}ntention \textbf{F}low \textbf{R}ecognition from human demonstrations. IFRAgent analyzes explicit intention flows from human demonstrations to construct a query-level vector library of standard operating procedures (SOP), and analyzes implicit intention flows to build a user-level habit repository. IFRAgent then leverages a SOP extractor combined with retrieval-augmented generation and a query rewriter to generate personalized query and SOP from a raw ambiguous query, enhancing the alignment between mobile-use agents and human intent. Experimental results demonstrate that IFRAgent outperforms baselines by an average of 6.79\% (32.06\% relative improvement) in human intention alignment rate and improves step completion rates by an average of 5.30\% (26.34\% relative improvement). The codes are available at https://github.com/MadeAgents/Quick-on-the-Uptake.
RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning
Jun 13, 2025The integration of external knowledge through Retrieval-Augmented Generation (RAG) has become foundational in enhancing large language models (LLMs) for knowledge-intensive tasks. However, existing RAG paradigms often overlook the cognitive step of applying knowledge, leaving a gap between retrieved facts and task-specific reasoning. In this work, we introduce RAG+, a principled and modular extension that explicitly incorporates application-aware reasoning into the RAG pipeline. RAG+ constructs a dual corpus consisting of knowledge and aligned application examples, created either manually or automatically, and retrieves both jointly during inference. This design enables LLMs not only to access relevant information but also to apply it within structured, goal-oriented reasoning processes. Experiments across mathematical, legal, and medical domains, conducted on multiple models, demonstrate that RAG+ consistently outperforms standard RAG variants, achieving average improvements of 3-5%, and peak gains up to 7.5% in complex scenarios. By bridging retrieval with actionable application, RAG+ advances a more cognitively grounded framework for knowledge integration, representing a step toward more interpretable and capable LLMs.
MedScore: Factuality Evaluation of Free-Form Medical Answers
May 24, 2025While Large Language Models (LLMs) can generate fluent and convincing responses, they are not necessarily correct. This is especially apparent in the popular decompose-then-verify factuality evaluation pipeline, where LLMs evaluate generations by decomposing the generations into individual, valid claims. Factuality evaluation is especially important for medical answers, since incorrect medical information could seriously harm the patient. However, existing factuality systems are a poor match for the medical domain, as they are typically only evaluated on objective, entity-centric, formulaic texts such as biographies and historical topics. This differs from condition-dependent, conversational, hypothetical, sentence-structure diverse, and subjective medical answers, which makes decomposition into valid facts challenging. We propose MedScore, a new approach to decomposing medical answers into condition-aware valid facts. Our method extracts up to three times more valid facts than existing methods, reducing hallucination and vague references, and retaining condition-dependency in facts. The resulting factuality score significantly varies by decomposition method, verification corpus, and used backbone LLM, highlighting the importance of customizing each step for reliable factuality evaluation.
Strategic Chain-of-Thought: Guiding Accurate Reasoning in LLMs through Strategy Elicitation
Sep 05, 2024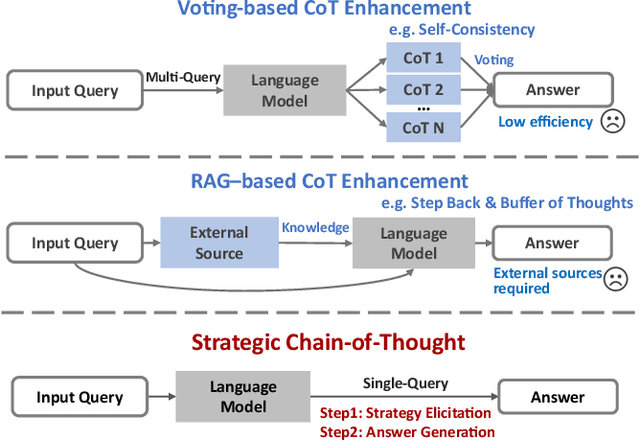
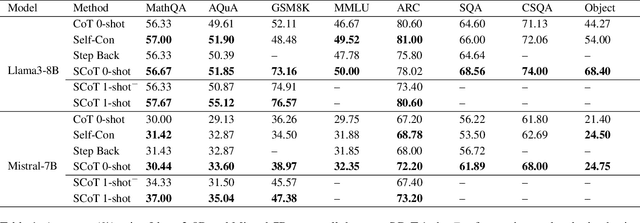
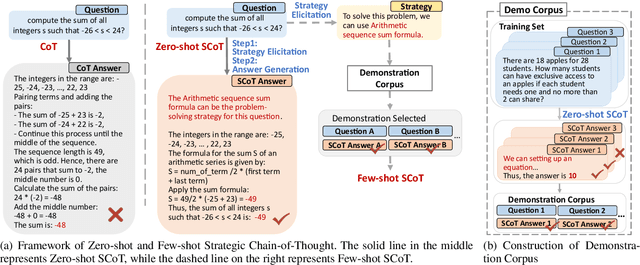
The Chain-of-Thought (CoT) paradigm has emerged as a critical approach for enhancing the reasoning capabilities of large language models (LLMs). However, despite their widespread adoption and success, CoT methods often exhibit instability due to their inability to consistently ensure the quality of generated reasoning paths, leading to sub-optimal reasoning performance. To address this challenge, we propose the \textbf{Strategic Chain-of-Thought} (SCoT), a novel methodology designed to refine LLM performance by integrating strategic knowledge prior to generating intermediate reasoning steps. SCoT employs a two-stage approach within a single prompt: first eliciting an effective problem-solving strategy, which is then used to guide the generation of high-quality CoT paths and final answers. Our experiments across eight challenging reasoning datasets demonstrate significant improvements, including a 21.05\% increase on the GSM8K dataset and 24.13\% on the Tracking\_Objects dataset, respectively, using the Llama3-8b model. Additionally, we extend the SCoT framework to develop a few-shot method with automatically matched demonstrations, yielding even stronger results. These findings underscore the efficacy of SCoT, highlighting its potential to substantially enhance LLM performance in complex reasoning tasks.
Re-TASK: Revisiting LLM Tasks from Capability, Skill, and Knowledge Perspectives
Aug 13, 2024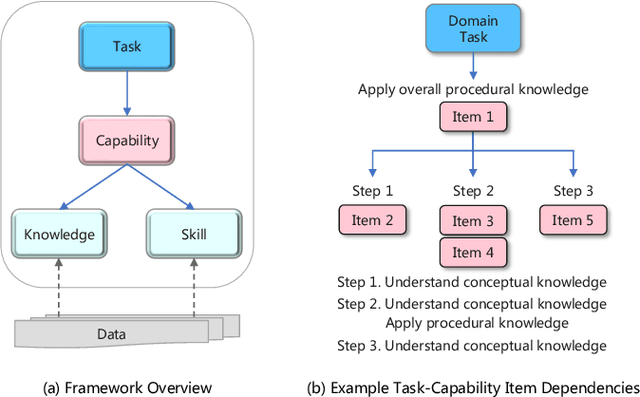
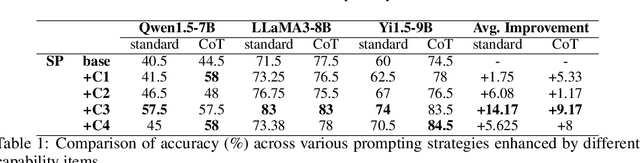

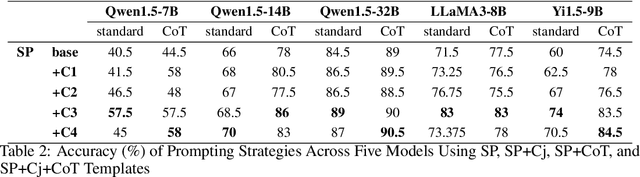
As large language models (LLMs) continue to scale, their enhanced performance often proves insufficient for solving domain-specific tasks. Systematically analyzing their failures and effectively enhancing their performance remain significant challenges. This paper introduces the Re-TASK framework, a novel theoretical model that Revisits LLM Tasks from cApability, Skill, Knowledge perspectives, guided by the principles of Bloom's Taxonomy and Knowledge Space Theory. The Re-TASK framework provides a systematic methodology to deepen our understanding, evaluation, and enhancement of LLMs for domain-specific tasks. It explores the interplay among an LLM's capabilities, the knowledge it processes, and the skills it applies, elucidating how these elements are interconnected and impact task performance. Our application of the Re-TASK framework reveals that many failures in domain-specific tasks can be attributed to insufficient knowledge or inadequate skill adaptation. With this insight, we propose structured strategies for enhancing LLMs through targeted knowledge injection and skill adaptation. Specifically, we identify key capability items associated with tasks and employ a deliberately designed prompting strategy to enhance task performance, thereby reducing the need for extensive fine-tuning. Alternatively, we fine-tune the LLM using capability-specific instructions, further validating the efficacy of our framework. Experimental results confirm the framework's effectiveness, demonstrating substantial improvements in both the performance and applicability of LLMs.
HMDN: Hierarchical Multi-Distribution Network for Click-Through Rate Prediction
Aug 02, 2024


As the recommendation service needs to address increasingly diverse distributions, such as multi-population, multi-scenario, multitarget, and multi-interest, more and more recent works have focused on multi-distribution modeling and achieved great progress. However, most of them only consider modeling in a single multi-distribution manner, ignoring that mixed multi-distributions often coexist and form hierarchical relationships. To address these challenges, we propose a flexible modeling paradigm, named Hierarchical Multi-Distribution Network (HMDN), which efficiently models these hierarchical relationships and can seamlessly integrate with existing multi-distribution methods, such as Mixture of-Experts (MoE) and Dynamic-Weight (DW) models. Specifically, we first design a hierarchical multi-distribution representation refinement module, employing a multi-level residual quantization to obtain fine-grained hierarchical representation. Then, the refined hierarchical representation is integrated into the existing single multi-distribution models, seamlessly expanding them into mixed multi-distribution models. Experimental results on both public and industrial datasets validate the effectiveness and flexibility of HMDN.
Medical Text Simplification: Optimizing for Readability with Unlikelihood Training and Reranked Beam Search Decoding
Oct 26, 2023Text simplification has emerged as an increasingly useful application of AI for bridging the communication gap in specialized fields such as medicine, where the lexicon is often dominated by technical jargon and complex constructs. Despite notable progress, methods in medical simplification sometimes result in the generated text having lower quality and diversity. In this work, we explore ways to further improve the readability of text simplification in the medical domain. We propose (1) a new unlikelihood loss that encourages generation of simpler terms and (2) a reranked beam search decoding method that optimizes for simplicity, which achieve better performance on readability metrics on three datasets. This study's findings offer promising avenues for improving text simplification in the medical field.