 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparator Injection Attack: Uncovering Dialogue Biases in Large Language Models Caused by Role Separators
Apr 08, 2025



Conversational large language models (LLMs) have gained widespread attention due to their instruction-following capabilities. To ensure conversational LLMs follow instructions, role separators are employed to distinguish between different participants in a conversation. However, incorporating role separators introduces potential vulnerabilities. Misusing roles can lead to prompt injection attacks, which can easily misalign the model's behavior with the user's intentions, raising significant security concerns. Although various prompt injection attacks have been proposed, recent research has largely overlooked the impact of role separators on safety. This highlights the critical need to thoroughly understand the systemic weaknesses in dialogue systems caused by role separators. This paper identifies modeling weaknesses caused by role separators. Specifically, we observe a strong positional bias associated with role separators, which is inherent in the format of dialogue modeling and can be triggered by the insertion of role separators. We further develop the Separators Injection Attack (SIA), a new orthometric attack based on role separators. The experiment results show that SIA is efficient and extensive in manipulating model behavior with an average gain of 18.2% for manual methods and enhances the attack success rate to 100% with automatic methods.
Stealthy Backdoor Attack to Real-world Models in Android Apps
Jan 02, 2025



Powered by their superior performance, deep neural networks (DNNs) have found widespread applications across various domains. Many deep learning (DL) models are now embedded in mobile apps, making them more accessible to end users through on-device DL. However, deploying on-device DL to users' smartphones simultaneously introduces several security threats. One primary threat is backdoor attacks. Extensive research has explored backdoor attacks for several years and has proposed numerous attack approaches. However, few studies have investigated backdoor attacks on DL models deployed in the real world, or they have shown obvious deficiencies in effectiveness and stealthiness. In this work, we explore more effective and stealthy backdoor attacks on real-world DL models extracted from mobile apps. Our main justification is that imperceptible and sample-specific backdoor triggers generated by DNN-based steganography can enhance the efficacy of backdoor attacks on real-world models. We first confirm the effectiveness of steganography-based backdoor attacks on four state-of-the-art DNN models. Subsequently, we systematically evaluate and analyze the stealthiness of the attacks to ensure they are difficult to perceive. Finally, we implement the backdoor attacks on real-world models and compare our approach with three baseline methods. We collect 38,387 mobile apps, extract 89 DL models from them, and analyze these models to obtain the prerequisite model information for the attacks. After identifying the target models, our approach achieves an average of 12.50% higher attack success rate than DeepPayload while better maintaining the normal performance of the models. Extensive experimental results demonstrate that our method enables more effective, robust, and stealthy backdoor attacks on real-world models.
Strategic Chain-of-Thought: Guiding Accurate Reasoning in LLMs through Strategy Elicitation
Sep 05, 2024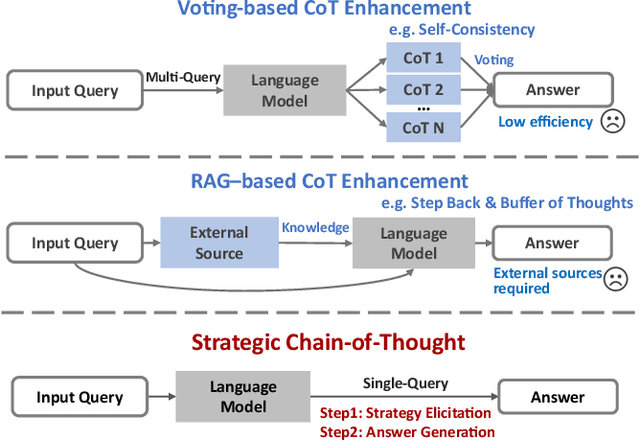
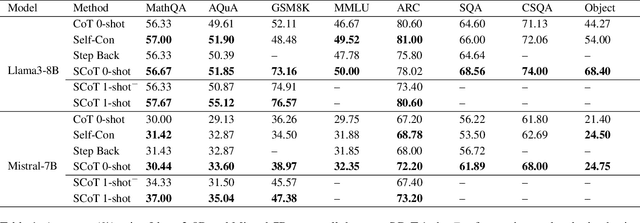
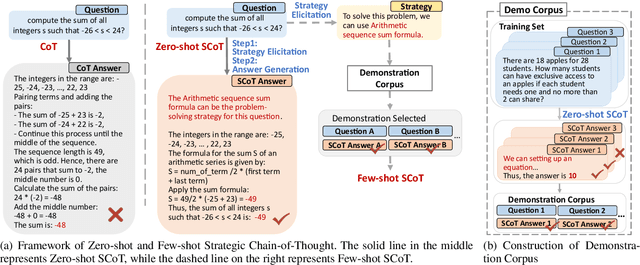
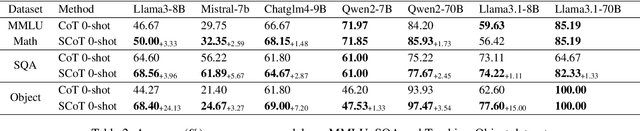
The Chain-of-Thought (CoT) paradigm has emerged as a critical approach for enhancing the reasoning capabilities of large language models (LLMs). However, despite their widespread adoption and success, CoT methods often exhibit instability due to their inability to consistently ensure the quality of generated reasoning paths, leading to sub-optimal reasoning performance. To address this challenge, we propose the \textbf{Strategic Chain-of-Thought} (SCoT), a novel methodology designed to refine LLM performance by integrating strategic knowledge prior to generating intermediate reasoning steps. SCoT employs a two-stage approach within a single prompt: first eliciting an effective problem-solving strategy, which is then used to guide the generation of high-quality CoT paths and final answers. Our experiments across eight challenging reasoning datasets demonstrate significant improvements, including a 21.05\% increase on the GSM8K dataset and 24.13\% on the Tracking\_Objects dataset, respectively, using the Llama3-8b model. Additionally, we extend the SCoT framework to develop a few-shot method with automatically matched demonstrations, yielding even stronger results. These findings underscore the efficacy of SCoT, highlighting its potential to substantially enhance LLM performance in complex reasoning tasks.
When GPT Meets Program Analysis: Towards Intelligent Detection of Smart Contract Logic Vulnerabilities in GPTScan
Aug 07, 2023
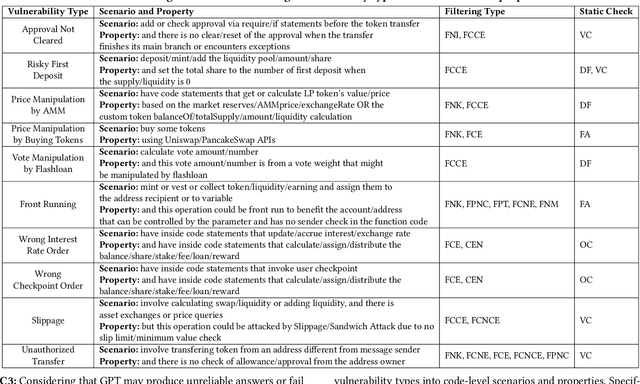
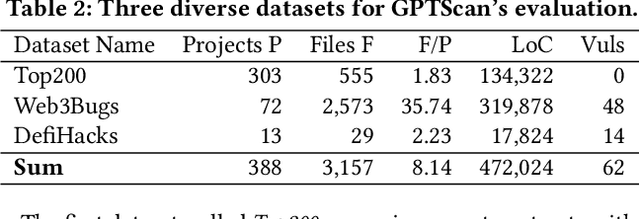

Smart contracts are prone to various vulnerabilities, leading to substantial financial losses over time. Current analysis tools mainly target vulnerabilities with fixed control or dataflow patterns, such as re-entrancy and integer overflow. However, a recent study on Web3 security bugs revealed that about 80% of these bugs cannot be audited by existing tools due to the lack of domain-specific property description and checking. Given recent advances in Generative Pretraining Transformer (GPT), it is worth exploring how GPT could aid in detecting logic vulnerabilities in smart contracts. In this paper, we propose GPTScan, the first tool combining GPT with static analysis for smart contract logic vulnerability detection. Instead of relying solely on GPT to identify vulnerabilities, which can lead to high false positives and is limited by GPT's pre-trained knowledge, we utilize GPT as a versatile code understanding tool. By breaking down each logic vulnerability type into scenarios and properties, GPTScan matches candidate vulnerabilities with GPT. To enhance accuracy, GPTScan further instructs GPT to intelligently recognize key variables and statements, which are then validated by static confirmation. Evaluation on diverse datasets with around 400 contract projects and 3K Solidity files shows that GPTScan achieves high precision (over 90%) for token contracts and acceptable precision (57.14%) for large projects like Web3Bugs. It effectively detects groundtruth logic vulnerabilities with a recall of over 80%, including 9 new vulnerabilities missed by human auditors. GPTScan is fast and cost-effective, taking an average of 14.39 seconds and 0.01 USD to scan per thousand lines of Solidity code. Moreover, static confirmation helps GPTScan reduce two-thirds of false positives.
Temporal-Spatial dependencies ENhanced deep learning model (TSEN) for household leverage series forecasting
Oct 17, 2022
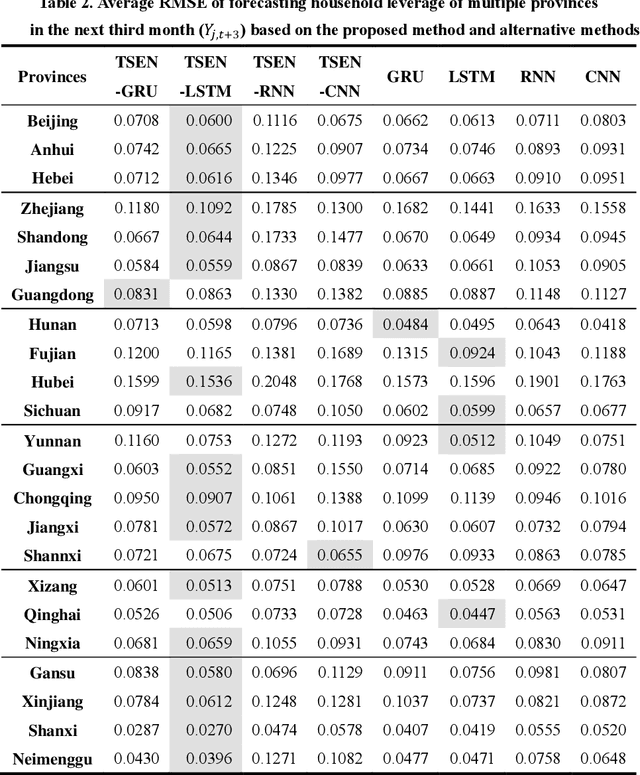

Analyzing both temporal and spatial patterns for an accurate forecasting model for financial time series forecasting is a challenge due to the complex nature of temporal-spatial dynamics: time series from different locations often have distinct patterns; and for the same time series, patterns may vary as time goes by. Inspired by the successful applications of deep learning, we propose a new model to resolve the issues of forecasting household leverage in China. Our solution consists of multiple RNN-based layers and an attention layer: each RNN-based layer automatically learns the temporal pattern of a specific series with multivariate exogenous series, and then the attention layer learns the spatial correlative weight and obtains the global representations simultaneously. The results show that the new approach can capture the temporal-spatial dynamics of household leverage well and get more accurate and solid predictive results. More, the simulation also studies show that clustering and choosing correlative series are necessary to obtain accurate forecasting results.
Cooperative Multi-Agent Reinforcement Learning Based Distributed Dynamic Spectrum Access in Cognitive Radio Networks
Jun 17, 2021
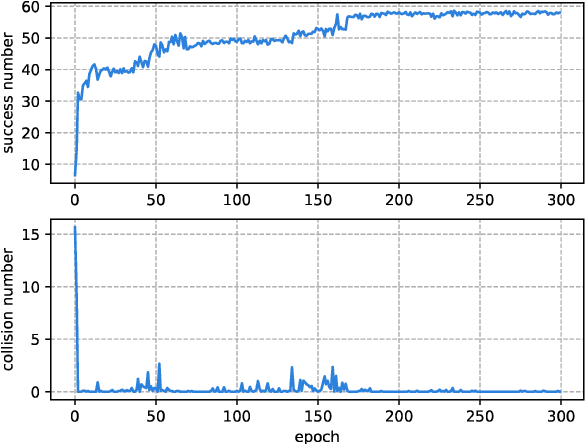
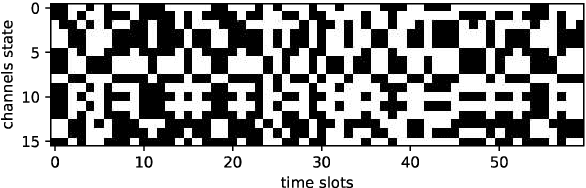
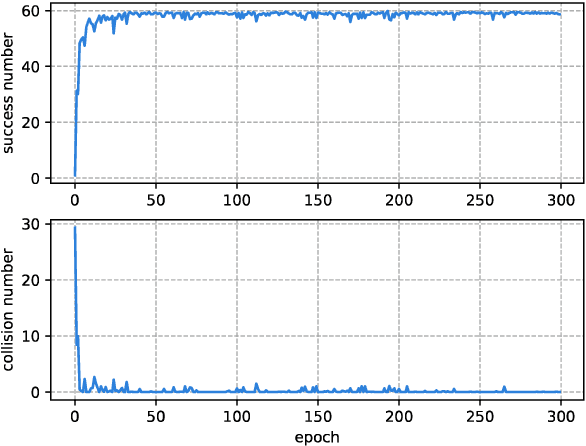
With the development of the 5G and Internet of Things, amounts of wireless devices need to share the limited spectrum resources. Dynamic spectrum access (DSA) is a promising paradigm to remedy the problem of inefficient spectrum utilization brought upon by the historical command-and-control approach to spectrum allocation. In this paper, we investigate the distributed DSA problem for multi-user in a typical multi-channel cognitive radio network. The problem is formulated as a decentralized partially observable Markov decision process (Dec-POMDP), and we proposed a centralized off-line training and distributed on-line execution framework based on cooperative multi-agent reinforcement learning (MARL). We employ the deep recurrent Q-network (DRQN) to address the partial observability of the state for each cognitive user. The ultimate goal is to learn a cooperative strategy which maximizes the sum throughput of cognitive radio network in distributed fashion without coordination information exchange between cognitive users. Finally, we validate the proposed algorithm in various settings through extensive experiments. From the simulation results, we can observe that the proposed algorithm can converge fast and achieve almost the optimal performance.