 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropertyGPT: LLM-driven Formal Verification of Smart Contracts through Retrieval-Augmented Property Generation
May 04, 2024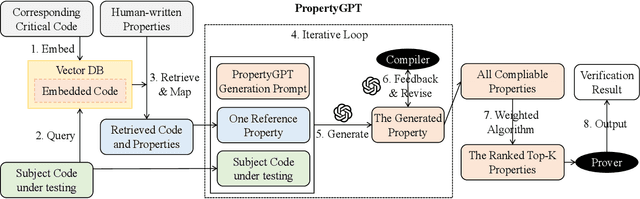
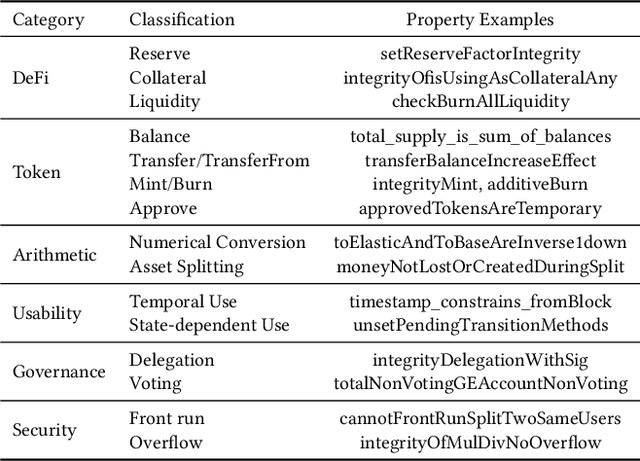

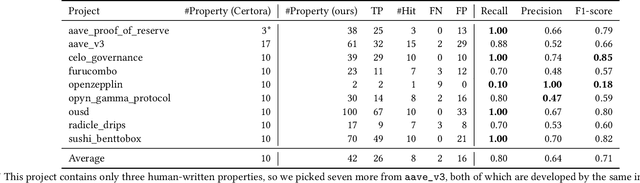
With recent advances in large language models (LLMs), this paper explores the potential of leveraging state-of-the-art LLMs, such as GPT-4, to transfer existing human-written properties (e.g., those from Certora auditing reports) and automatically generate customized properties for unknown code. To this end, we embed existing properties into a vector database and retrieve a reference property for LLM-based in-context learning to generate a new prop- erty for a given code. While this basic process is relatively straight- forward, ensuring that the generated properties are (i) compilable, (ii) appropriate, and (iii) runtime-verifiable presents challenges. To address (i), we use the compilation and static analysis feedback as an external oracle to guide LLMs in iteratively revising the generated properties. For (ii), we consider multiple dimensions of similarity to rank the properties and employ a weighted algorithm to identify the top-K properties as the final result. For (iii), we design a dedicated prover to formally verify the correctness of the generated prop- erties. We have implemented these strategies into a novel system called PropertyGPT, with 623 human-written properties collected from 23 Certora projects. Our experiments show that PropertyGPT can generate comprehensive and high-quality properties, achieving an 80% recall compared to the ground truth. It successfully detected 26 CVEs/attack incidents out of 37 tested and also uncovered 12 zero-day vulnerabilities, resulting in $8,256 bug bounty rewards.
LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs' Vulnerability Reasoning
Jan 29, 2024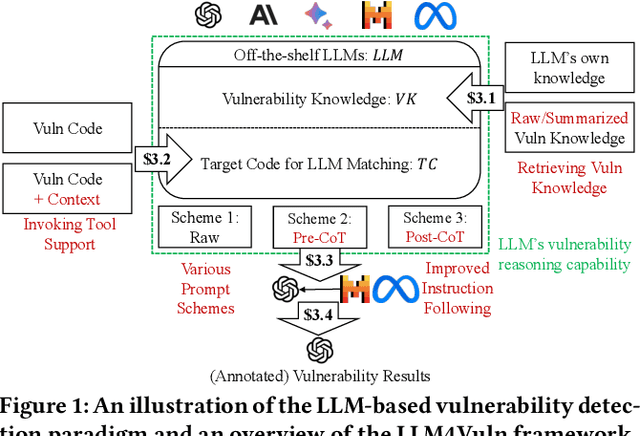

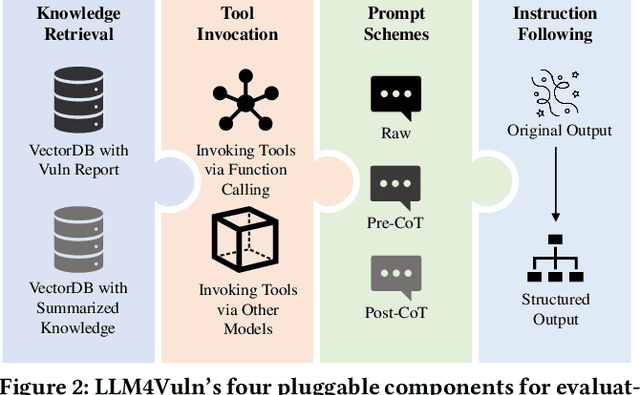
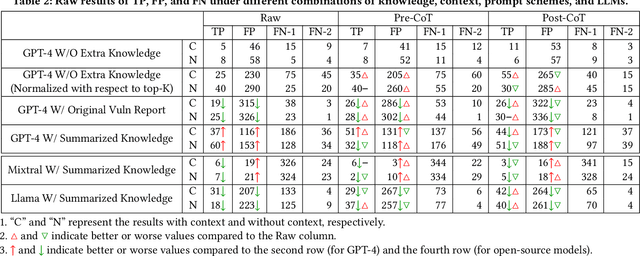
Large language models (LLMs) have demonstrated significant potential for many downstream tasks, including those requiring human-level intelligence, such as vulnerability detection. However, recent attempts to use LLMs for vulnerability detection are still preliminary, as they lack an in-depth understanding of a subject LLM's vulnerability reasoning capability -- whether it originates from the model itself or from external assistance, such as invoking tool support and retrieving vulnerability knowledge. In this paper, we aim to decouple LLMs' vulnerability reasoning capability from their other capabilities, including the ability to actively seek additional information (e.g., via function calling in SOTA models), adopt relevant vulnerability knowledge (e.g., via vector-based matching and retrieval), and follow instructions to output structured results. To this end, we propose a unified evaluation framework named LLM4Vuln, which separates LLMs' vulnerability reasoning from their other capabilities and evaluates how LLMs' vulnerability reasoning could be enhanced when combined with the enhancement of other capabilities. To demonstrate the effectiveness of LLM4Vuln, we have designed controlled experiments using 75 ground-truth smart contract vulnerabilities, which were extensively audited as high-risk on Code4rena from August to November 2023, and tested them in 4,950 different scenarios across three representative LLMs (GPT-4, Mixtral, and Code Llama). Our results not only reveal ten findings regarding the varying effects of knowledge enhancement, context supplementation, prompt schemes, and models but also enable us to identify 9 zero-day vulnerabilities in two pilot bug bounty programs with over 1,000 USD being awarded.
When GPT Meets Program Analysis: Towards Intelligent Detection of Smart Contract Logic Vulnerabilities in GPTScan
Aug 07, 2023
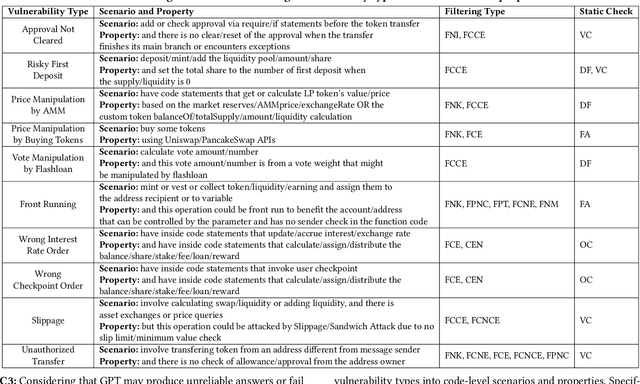
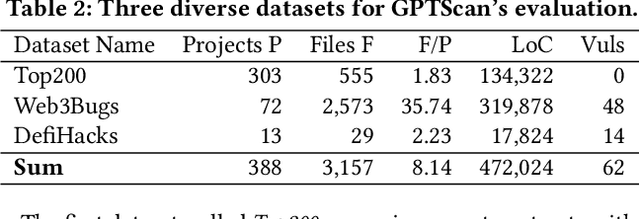

Smart contracts are prone to various vulnerabilities, leading to substantial financial losses over time. Current analysis tools mainly target vulnerabilities with fixed control or dataflow patterns, such as re-entrancy and integer overflow. However, a recent study on Web3 security bugs revealed that about 80% of these bugs cannot be audited by existing tools due to the lack of domain-specific property description and checking. Given recent advances in Generative Pretraining Transformer (GPT), it is worth exploring how GPT could aid in detecting logic vulnerabilities in smart contracts. In this paper, we propose GPTScan, the first tool combining GPT with static analysis for smart contract logic vulnerability detection. Instead of relying solely on GPT to identify vulnerabilities, which can lead to high false positives and is limited by GPT's pre-trained knowledge, we utilize GPT as a versatile code understanding tool. By breaking down each logic vulnerability type into scenarios and properties, GPTScan matches candidate vulnerabilities with GPT. To enhance accuracy, GPTScan further instructs GPT to intelligently recognize key variables and statements, which are then validated by static confirmation. Evaluation on diverse datasets with around 400 contract projects and 3K Solidity files shows that GPTScan achieves high precision (over 90%) for token contracts and acceptable precision (57.14%) for large projects like Web3Bugs. It effectively detects groundtruth logic vulnerabilities with a recall of over 80%, including 9 new vulnerabilities missed by human auditors. GPTScan is fast and cost-effective, taking an average of 14.39 seconds and 0.01 USD to scan per thousand lines of Solidity code. Moreover, static confirmation helps GPTScan reduce two-thirds of false positives.
The APC Algorithm of Solving Large-Scale Linear Systems: A Generalized Analysis
Sep 16, 2022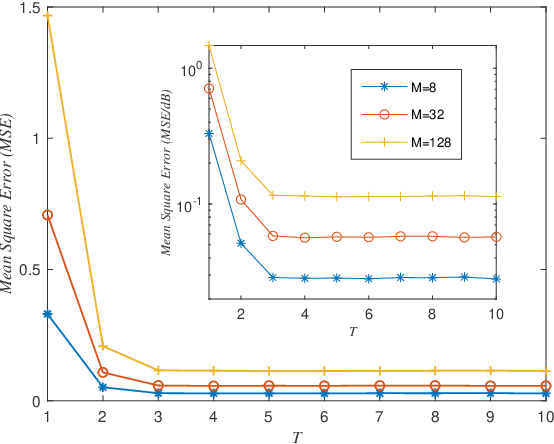
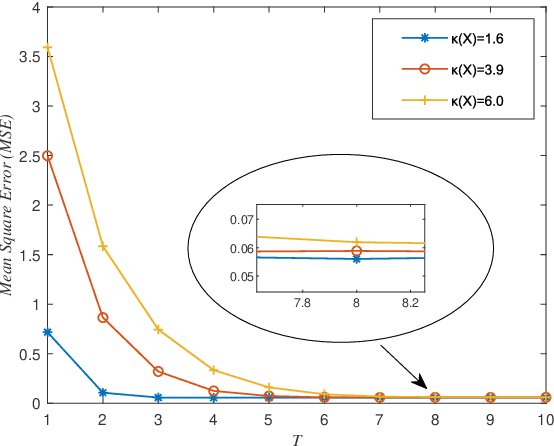
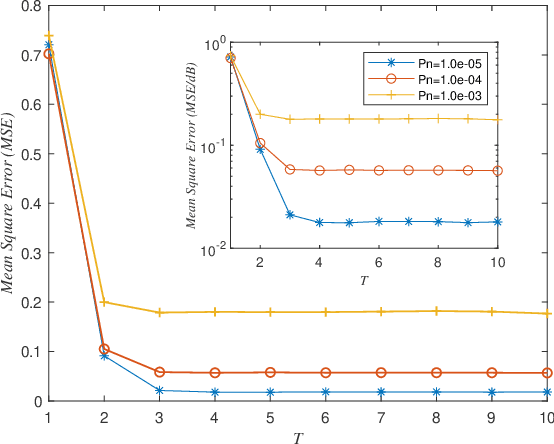
A new algorithm called accelerated projection-based consensus (APC) has recently emerged as a promising approach to solve large-scale systems of linear equations in a distributed fashion. The algorithm adopts the federated architecture, and attracts increasing research interest; however, it's performance analysis is still incomplete, e.g., the error performance under noisy condition has not yet been investigated. In this paper, we focus on providing a generalized analysis by the use of the linear system theory, such that the error performance of the APC algorithm for solving linear systems in presence of additive noise can be clarified. We specifically provide a closed-form expression of the error of solution attained by the APC algorithm. Numerical results demonstrate the error performance of the APC algorithm, validating the presented analysis.