 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHackers or Hallucinators? A Comprehensive Analysis of LLM-Based Automated Penetration Testing
Apr 07, 2026The rapid advancement of Large Language Models (LLMs) has created new opportunities for Automated Penetration Testing (AutoPT), spawning numerous frameworks aimed at achieving end-to-end autonomous attacks. However, despite the proliferation of related studies, existing research generally lacks systematic architectural analysis and large-scale empirical comparisons under a unified benchmark. Therefore, this paper presents the first Systematization of Knowledge (SoK) focusing on the architectural design and comprehensive empirical evaluation of current LLM-based AutoPT frameworks. At systematization level, we comprehensively review existing framework designs across six dimensions: agent architecture, agent plan, agent memory, agent execution, external knowledge, and benchmarks. At empirical level, we conduct large-scale experiments on 13 representative open-source AutoPT frameworks and 2 baseline frameworks utilizing a unified benchmark. The experiments consumed over 10 billion tokens in total and generated more than 1,500 execution logs, which were manually reviewed and analyzed over four months by a panel of more than 15 researchers with expertise in cybersecurity. By investigating the latest progress in this rapidly developing field, we provide researchers with a structured taxonomy to understand existing LLM-based AutoPT frameworks and a large-scale empirical benchmark, along with promising directions for future research.
Casting a SPELL: Sentence Pairing Exploration for LLM Limitation-breaking
Dec 24, 2025Large language models (LLMs) have revolutionized software development through AI-assisted coding tools, enabling developers with limited programming expertise to create sophisticated applications. However, this accessibility extends to malicious actors who may exploit these powerful tools to generate harmful software. Existing jailbreaking research primarily focuses on general attack scenarios against LLMs, with limited exploration of malicious code generation as a jailbreak target. To address this gap, we propose SPELL, a comprehensive testing framework specifically designed to evaluate the weakness of security alignment in malicious code generation. Our framework employs a time-division selection strategy that systematically constructs jailbreaking prompts by intelligently combining sentences from a prior knowledge dataset, balancing exploration of novel attack patterns with exploitation of successful techniques. Extensive evaluation across three advanced code models (GPT-4.1, Claude-3.5, and Qwen2.5-Coder) demonstrates SPELL's effectiveness, achieving attack success rates of 83.75%, 19.38%, and 68.12% respectively across eight malicious code categories. The generated prompts successfully produce malicious code in real-world AI development tools such as Cursor, with outputs confirmed as malicious by state-of-the-art detection systems at rates exceeding 73%. These findings reveal significant security gaps in current LLM implementations and provide valuable insights for improving AI safety alignment in code generation applications.
A Vision for Auto Research with LLM Agents
Apr 26, 2025This paper introduces Agent-Based Auto Research, a structured multi-agent framework designed to automate, coordinate, and optimize the full lifecycle of scientific research. Leveraging the capabilities of large language models (LLMs) and modular agent collaboration, the system spans all major research phases, including literature review, ideation, methodology planning, experimentation, paper writing, peer review response, and dissemination. By addressing issues such as fragmented workflows, uneven methodological expertise, and cognitive overload, the framework offers a systematic and scalable approach to scientific inquiry. Preliminary explorations demonstrate the feasibility and potential of Auto Research as a promising paradigm for self-improving, AI-driven research processes.
PropertyGPT: LLM-driven Formal Verification of Smart Contracts through Retrieval-Augmented Property Generation
May 04, 2024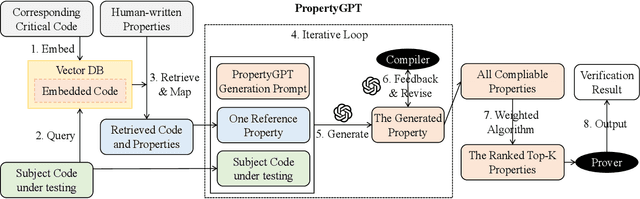
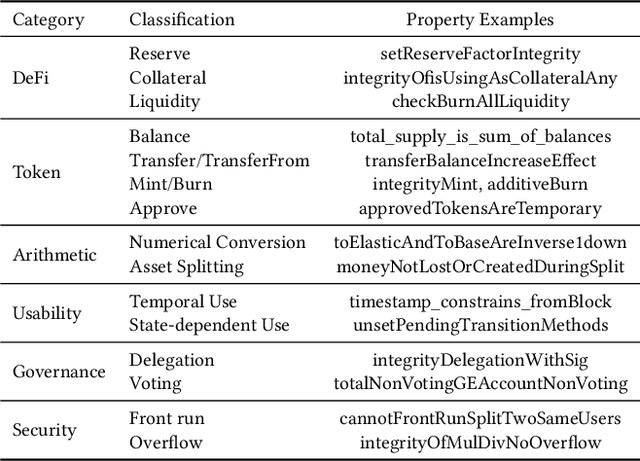

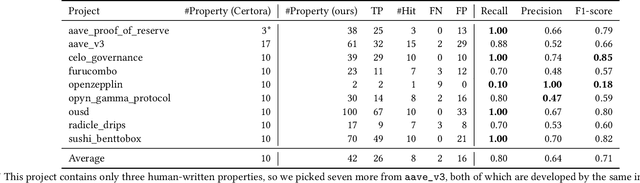
With recent advances in large language models (LLMs), this paper explores the potential of leveraging state-of-the-art LLMs, such as GPT-4, to transfer existing human-written properties (e.g., those from Certora auditing reports) and automatically generate customized properties for unknown code. To this end, we embed existing properties into a vector database and retrieve a reference property for LLM-based in-context learning to generate a new prop- erty for a given code. While this basic process is relatively straight- forward, ensuring that the generated properties are (i) compilable, (ii) appropriate, and (iii) runtime-verifiable presents challenges. To address (i), we use the compilation and static analysis feedback as an external oracle to guide LLMs in iteratively revising the generated properties. For (ii), we consider multiple dimensions of similarity to rank the properties and employ a weighted algorithm to identify the top-K properties as the final result. For (iii), we design a dedicated prover to formally verify the correctness of the generated prop- erties. We have implemented these strategies into a novel system called PropertyGPT, with 623 human-written properties collected from 23 Certora projects. Our experiments show that PropertyGPT can generate comprehensive and high-quality properties, achieving an 80% recall compared to the ground truth. It successfully detected 26 CVEs/attack incidents out of 37 tested and also uncovered 12 zero-day vulnerabilities, resulting in $8,256 bug bounty rewards.
LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs' Vulnerability Reasoning
Jan 29, 2024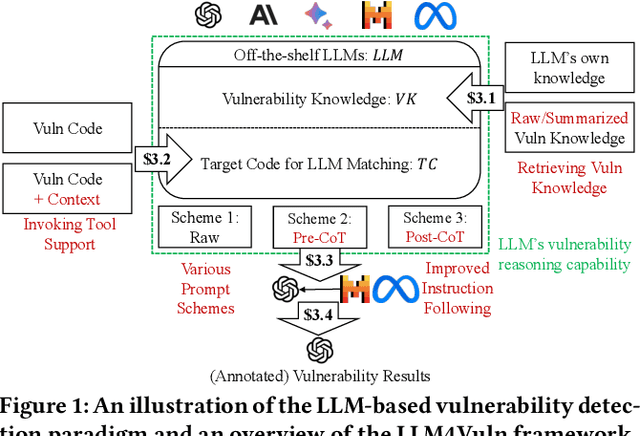

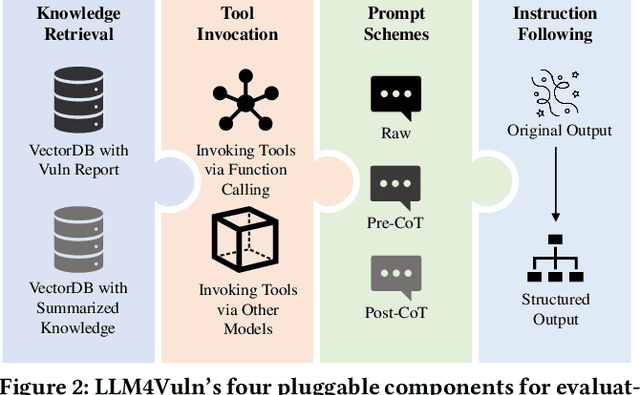
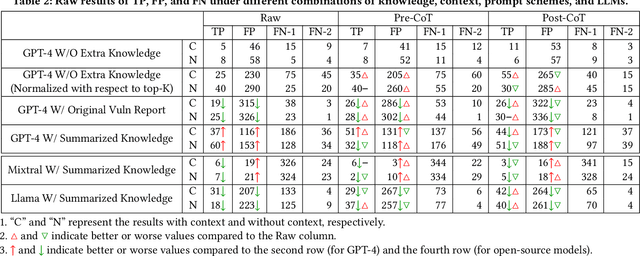
Large language models (LLMs) have demonstrated significant potential for many downstream tasks, including those requiring human-level intelligence, such as vulnerability detection. However, recent attempts to use LLMs for vulnerability detection are still preliminary, as they lack an in-depth understanding of a subject LLM's vulnerability reasoning capability -- whether it originates from the model itself or from external assistance, such as invoking tool support and retrieving vulnerability knowledge. In this paper, we aim to decouple LLMs' vulnerability reasoning capability from their other capabilities, including the ability to actively seek additional information (e.g., via function calling in SOTA models), adopt relevant vulnerability knowledge (e.g., via vector-based matching and retrieval), and follow instructions to output structured results. To this end, we propose a unified evaluation framework named LLM4Vuln, which separates LLMs' vulnerability reasoning from their other capabilities and evaluates how LLMs' vulnerability reasoning could be enhanced when combined with the enhancement of other capabilities. To demonstrate the effectiveness of LLM4Vuln, we have designed controlled experiments using 75 ground-truth smart contract vulnerabilities, which were extensively audited as high-risk on Code4rena from August to November 2023, and tested them in 4,950 different scenarios across three representative LLMs (GPT-4, Mixtral, and Code Llama). Our results not only reveal ten findings regarding the varying effects of knowledge enhancement, context supplementation, prompt schemes, and models but also enable us to identify 9 zero-day vulnerabilities in two pilot bug bounty programs with over 1,000 USD being awarded.
When GPT Meets Program Analysis: Towards Intelligent Detection of Smart Contract Logic Vulnerabilities in GPTScan
Aug 07, 2023
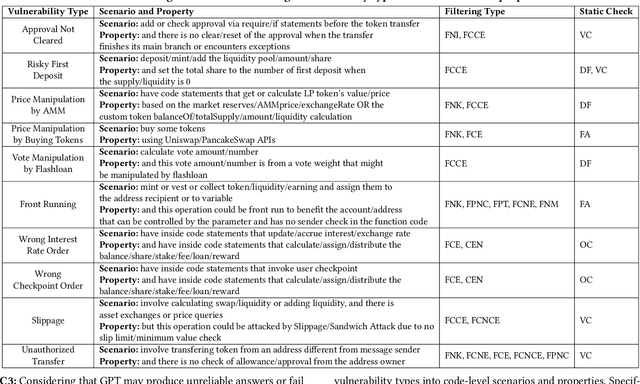
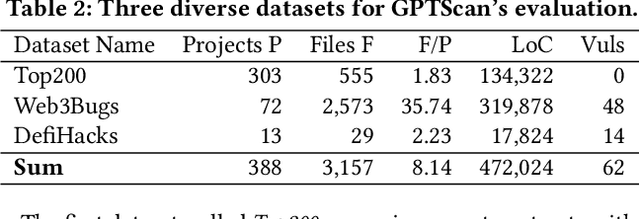

Smart contracts are prone to various vulnerabilities, leading to substantial financial losses over time. Current analysis tools mainly target vulnerabilities with fixed control or dataflow patterns, such as re-entrancy and integer overflow. However, a recent study on Web3 security bugs revealed that about 80% of these bugs cannot be audited by existing tools due to the lack of domain-specific property description and checking. Given recent advances in Generative Pretraining Transformer (GPT), it is worth exploring how GPT could aid in detecting logic vulnerabilities in smart contracts. In this paper, we propose GPTScan, the first tool combining GPT with static analysis for smart contract logic vulnerability detection. Instead of relying solely on GPT to identify vulnerabilities, which can lead to high false positives and is limited by GPT's pre-trained knowledge, we utilize GPT as a versatile code understanding tool. By breaking down each logic vulnerability type into scenarios and properties, GPTScan matches candidate vulnerabilities with GPT. To enhance accuracy, GPTScan further instructs GPT to intelligently recognize key variables and statements, which are then validated by static confirmation. Evaluation on diverse datasets with around 400 contract projects and 3K Solidity files shows that GPTScan achieves high precision (over 90%) for token contracts and acceptable precision (57.14%) for large projects like Web3Bugs. It effectively detects groundtruth logic vulnerabilities with a recall of over 80%, including 9 new vulnerabilities missed by human auditors. GPTScan is fast and cost-effective, taking an average of 14.39 seconds and 0.01 USD to scan per thousand lines of Solidity code. Moreover, static confirmation helps GPTScan reduce two-thirds of false positives.