 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePentestEval: Benchmarking LLM-based Penetration Testing with Modular and Stage-Level Design
Dec 16, 2025Penetration testing is essential for assessing and strengthening system security against real-world threats, yet traditional workflows remain highly manual, expertise-intensive, and difficult to scale. Although recent advances in Large Language Models (LLMs) offer promising opportunities for automation, existing applications rely on simplistic prompting without task decomposition or domain adaptation, resulting in unreliable black-box behavior and limited insight into model capabilities across penetration testing stages. To address this gap, we introduce PentestEval, the first comprehensive benchmark for evaluating LLMs across six decomposed penetration testing stages: Information Collection, Weakness Gathering and Filtering, Attack Decision-Making, Exploit Generation and Revision. PentestEval integrates expert-annotated ground truth with a fully automated evaluation pipeline across 346 tasks covering all stages in 12 realistic vulnerable scenarios. Our stage-level evaluation of 9 widely used LLMs reveals generally weak performance and distinct limitations across the stages of penetration-testing workflow. End-to-end pipelines reach only 31% success rate, and existing LLM-powered systems such as PentestGPT, PentestAgent, and VulnBot exhibit similar limitations, with autonomous agents failing almost entirely. These findings highlight that autonomous penetration testing demands stronger structured reasoning, where modularization enhances each individual stage and improves overall performance. PentestEval provides the foundational benchmark needed for future research on fine-grained, stage-level evaluation, paving the way toward more reliable LLM-based automation.
AutoEmpirical: LLM-Based Automated Research for Empirical Software Fault Analysis
Oct 06, 2025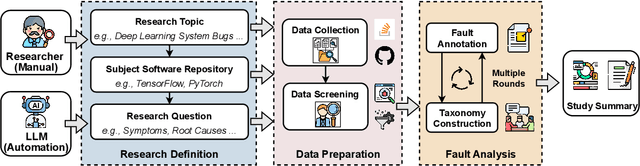

Understanding software faults is essential for empirical research in software development and maintenance. However, traditional fault analysis, while valuable, typically involves multiple expert-driven steps such as collecting potential faults, filtering, and manual investigation. These processes are both labor-intensive and time-consuming, creating bottlenecks that hinder large-scale fault studies in complex yet critical software systems and slow the pace of iterative empirical research. In this paper, we decompose the process of empirical software fault study into three key phases: (1) research objective definition, (2) data preparation, and (3) fault analysis, and we conduct an initial exploration study of applying Large Language Models (LLMs) for fault analysis of open-source software. Specifically, we perform the evaluation on 3,829 software faults drawn from a high-quality empirical study. Our results show that LLMs can substantially improve efficiency in fault analysis, with an average processing time of about two hours, compared to the weeks of manual effort typically required. We conclude by outlining a detailed research plan that highlights both the potential of LLMs for advancing empirical fault studies and the open challenges that required be addressed to achieve fully automated, end-to-end software fault analysis.
Chimera: Harnessing Multi-Agent LLMs for Automatic Insider Threat Simulation
Aug 12, 2025Insider threats, which can lead to severe losses, remain a major security concern. While machine learning-based insider threat detection (ITD) methods have shown promising results, their progress is hindered by the scarcity of high-quality data. Enterprise data is sensitive and rarely accessible, while publicly available datasets, when limited in scale due to cost, lack sufficient real-world coverage; and when purely synthetic, they fail to capture rich semantics and realistic user behavior. To address this, we propose Chimera, the first large language model (LLM)-based multi-agent framework that automatically simulates both benign and malicious insider activities and collects diverse logs across diverse enterprise environments. Chimera models each employee with agents that have role-specific behavior and integrates modules for group meetings, pairwise interactions, and autonomous scheduling, capturing realistic organizational dynamics. It incorporates 15 types of insider attacks (e.g., IP theft, system sabotage) and has been deployed to simulate activities in three sensitive domains: technology company, finance corporation, and medical institution, producing a new dataset, ChimeraLog. We assess ChimeraLog via human studies and quantitative analysis, confirming its diversity, realism, and presence of explainable threat patterns. Evaluations of existing ITD methods show an average F1-score of 0.83, which is significantly lower than 0.99 on the CERT dataset, demonstrating ChimeraLog's higher difficulty and utility for advancing ITD research.
The Foundation Cracks: A Comprehensive Study on Bugs and Testing Practices in LLM Libraries
Jun 14, 2025Large Language Model (LLM) libraries have emerged as the foundational infrastructure powering today's AI revolution, serving as the backbone for LLM deployment, inference optimization, fine-tuning, and production serving across diverse applications. Despite their critical role in the LLM ecosystem, these libraries face frequent quality issues and bugs that threaten the reliability of AI systems built upon them. To address this knowledge gap, we present the first comprehensive empirical investigation into bug characteristics and testing practices in modern LLM libraries. We examine 313 bug-fixing commits extracted across two widely-adopted LLM libraries: HuggingFace Transformers and vLLM.Through rigorous manual analysis, we establish comprehensive taxonomies categorizing bug symptoms into 5 types and root causes into 14 distinct categories.Our primary discovery shows that API misuse has emerged as the predominant root cause (32.17%-48.19%), representing a notable transition from algorithm-focused defects in conventional deep learning frameworks toward interface-oriented problems. Additionally, we examine 7,748 test functions to identify 7 distinct test oracle categories employed in current testing approaches, with predefined expected outputs (such as specific tensors and text strings) being the most common strategy. Our assessment of existing testing effectiveness demonstrates that the majority of bugs escape detection due to inadequate test cases (41.73%), lack of test drivers (32.37%), and weak test oracles (25.90%). Drawing from these findings, we offer some recommendations for enhancing LLM library quality assurance.
TokenProber: Jailbreaking Text-to-image Models via Fine-grained Word Impact Analysis
May 11, 2025Text-to-image (T2I) models have significantly advanced in producing high-quality images. However, such models have the ability to generate images containing not-safe-for-work (NSFW) content, such as pornography, violence, political content, and discrimination. To mitigate the risk of generating NSFW content, refusal mechanisms, i.e., safety checkers, have been developed to check potential NSFW content. Adversarial prompting techniques have been developed to evaluate the robustness of the refusal mechanisms. The key challenge remains to subtly modify the prompt in a way that preserves its sensitive nature while bypassing the refusal mechanisms. In this paper, we introduce TokenProber, a method designed for sensitivity-aware differential testing, aimed at evaluating the robustness of the refusal mechanisms in T2I models by generating adversarial prompts. Our approach is based on the key observation that adversarial prompts often succeed by exploiting discrepancies in how T2I models and safety checkers interpret sensitive content. Thus, we conduct a fine-grained analysis of the impact of specific words within prompts, distinguishing between dirty words that are essential for NSFW content generation and discrepant words that highlight the different sensitivity assessments between T2I models and safety checkers. Through the sensitivity-aware mutation, TokenProber generates adversarial prompts, striking a balance between maintaining NSFW content generation and evading detection. Our evaluation of TokenProber against 5 safety checkers on 3 popular T2I models, using 324 NSFW prompts, demonstrates its superior effectiveness in bypassing safety filters compared to existing methods (e.g., 54%+ increase on average), highlighting TokenProber's ability to uncover robustness issues in the existing refusal mechanisms.
Holistic Audit Dataset Generation for LLM Unlearning via Knowledge Graph Traversal and Redundancy Removal
Feb 26, 2025In recent years, Large Language Models (LLMs) have faced increasing demands to selectively remove sensitive information, protect privacy, and comply with copyright regulations through unlearning, by Machine Unlearning. While evaluating unlearning effectiveness is crucial, existing benchmarks are limited in scale and comprehensiveness, typically containing only a few hundred test cases. We identify two critical challenges in generating holistic audit datasets: ensuring audit adequacy and handling knowledge redundancy between forget and retain dataset. To address these challenges, we propose HANKER, an automated framework for holistic audit dataset generation leveraging knowledge graphs to achieve fine-grained coverage and eliminate redundant knowledge. Applying HANKER to the popular MUSE benchmark, we successfully generated over 69,000 and 111,000 audit cases for the News and Books datasets respectively, identifying thousands of knowledge memorization instances that the previous benchmark failed to detect. Our empirical analysis uncovers how knowledge redundancy significantly skews unlearning effectiveness metrics, with redundant instances artificially inflating the observed memorization measurements ROUGE from 19.7% to 26.1% and Entailment Scores from 32.4% to 35.2%, highlighting the necessity of systematic deduplication for accurate assessment.
Understanding Individual Agent Importance in Multi-Agent System via Counterfactual Reasoning
Dec 23, 2024Explaining multi-agent systems (MAS) is urgent as these systems become increasingly prevalent in various applications. Previous work has proveided explanations for the actions or states of agents, yet falls short in understanding the black-boxed agent's importance within a MAS and the overall team strategy. To bridge this gap, we propose EMAI, a novel agent-level explanation approach that evaluates the individual agent's importance. Inspired by counterfactual reasoning, a larger change in reward caused by the randomized action of agent indicates its higher importance. We model it as a MARL problem to capture interactions across agents. Utilizing counterfactual reasoning, EMAI learns the masking agents to identify important agents. Specifically, we define the optimization function to minimize the reward difference before and after action randomization and introduce sparsity constraints to encourage the exploration of more action randomization of agents during training. The experimental results in seven multi-agent tasks demonstratee that EMAI achieves higher fidelity in explanations than baselines and provides more effective guidance in practical applications concerning understanding policies, launching attacks, and patching policies.
DriveTester: A Unified Platform for Simulation-Based Autonomous Driving Testing
Dec 17, 2024



Simulation-based testing plays a critical role in evaluating the safety and reliability of autonomous driving systems (ADSs). However, one of the key challenges in ADS testing is the complexity of preparing and configuring simulation environments, particularly in terms of compatibility and stability between the simulator and the ADS. This complexity often results in researchers dedicating significant effort to customize their own environments, leading to disparities in development platforms and underlying systems. Consequently, reproducing and comparing these methodologies on a unified ADS testing platform becomes difficult. To address these challenges, we introduce DriveTester, a unified simulation-based testing platform built on Apollo, one of the most widely used open-source, industrial-level ADS platforms. DriveTester provides a consistent and reliable environment, integrates a lightweight traffic simulator, and incorporates various state-of-the-art ADS testing techniques. This enables researchers to efficiently develop, test, and compare their methods within a standardized platform, fostering reproducibility and comparison across different ADS testing approaches. The code is available: https://github.com/MingfeiCheng/DriveTester.
NebulaFL: Effective Asynchronous Federated Learning for JointCloud Computing
Dec 06, 2024With advancements in AI infrastructure and Trusted Execution Environment (TEE) technology, Federated Learning as a Service (FLaaS) through JointCloud Computing (JCC) is promising to break through the resource constraints caused by heterogeneous edge devices in the traditional Federated Learning (FL) paradigm. Specifically, with the protection from TEE, data owners can achieve efficient model training with high-performance AI services in the cloud. By providing additional FL services, cloud service providers can achieve collaborative learning among data owners. However, FLaaS still faces three challenges, i.e., i) low training performance caused by heterogeneous data among data owners, ii) high communication overhead among different clouds (i.e., data centers), and iii) lack of efficient resource scheduling strategies to balance training time and cost. To address these challenges, this paper presents a novel asynchronous FL approach named NebulaFL for collaborative model training among multiple clouds. To address data heterogeneity issues, NebulaFL adopts a version control-based asynchronous FL training scheme in each data center to balance training time among data owners. To reduce communication overhead, NebulaFL adopts a decentralized model rotation mechanism to achieve effective knowledge sharing among data centers. To balance training time and cost, NebulaFL integrates a reward-guided strategy for data owners selection and resource scheduling. The experimental results demonstrate that, compared to the state-of-the-art FL methods, NebulaFL can achieve up to 5.71\% accuracy improvement. In addition, NebulaFL can reduce up to 50% communication overhead and 61.94% costs under a target accuracy.
An Empirical Study of Vulnerability Detection using Federated Learning
Nov 25, 2024Although Deep Learning (DL) methods becoming increasingly popular in vulnerability detection, their performance is seriously limited by insufficient training data. This is mainly because few existing software organizations can maintain a complete set of high-quality samples for DL-based vulnerability detection. Due to the concerns about privacy leakage, most of them are reluctant to share data, resulting in the data silo problem. Since enables collaboratively model training without data sharing, Federated Learning (FL) has been investigated as a promising means of addressing the data silo problem in DL-based vulnerability detection. However, since existing FL-based vulnerability detection methods focus on specific applications, it is still far unclear i) how well FL adapts to common vulnerability detection tasks and ii) how to design a high-performance FL solution for a specific vulnerability detection task. To answer these two questions, this paper first proposes VulFL, an effective evaluation framework for FL-based vulnerability detection. Then, based on VulFL, this paper conducts a comprehensive study to reveal the underlying capabilities of FL in dealing with different types of CWEs, especially when facing various data heterogeneity scenarios. Our experimental results show that, compared to independent training, FL can significantly improve the detection performance of common AI models on all investigated CWEs, though the performance of FL-based vulnerability detection is limited by heterogeneous data. To highlight the performance differences between different FL solutions for vulnerability detection, we extensively investigate the impacts of different configuration strategies for each framework component of VulFL. Our study sheds light on the potential of FL in vulnerability detection, which can be used to guide the design of FL-based solutions for vulnerability detection.