 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedQP: Towards Accurate Federated Learning using Quadratic Programming Guided Mutation
Nov 24, 2024



Due to the advantages of privacy-preserving, Federated Learning (FL) is widely used in distributed machine learning systems. However, existing FL methods suffer from low-inference performance caused by data heterogeneity. Specifically, due to heterogeneous data, the optimization directions of different local models vary greatly, making it difficult for the traditional FL method to get a generalized global model that performs well on all clients. As one of the state-of-the-art FL methods, the mutation-based FL method attempts to adopt a stochastic mutation strategy to guide the model training towards a well-generalized area (i.e., flat area in the loss landscape). Specifically, mutation allows the model to shift within the solution space, providing an opportunity to escape areas with poor generalization (i.e., sharp area). However, the stochastic mutation strategy easily results in diverse optimal directions of mutated models, which limits the performance of the existing mutation-based FL method. To achieve higher performance, this paper proposes a novel mutation-based FL approach named FedQP, utilizing a quadratic programming strategy to regulate the mutation directions wisely. By biasing the model mutation towards the direction of gradient update rather than traditional random mutation, FedQP can effectively guide the model to optimize towards a well-generalized area (i.e., flat area). Experiments on multiple well-known datasets show that our quadratic programming-guided mutation strategy effectively improves the inference accuracy of the global model in various heterogeneous data scenarios.
CaBaFL: Asynchronous Federated Learning via Hierarchical Cache and Feature Balance
Apr 19, 2024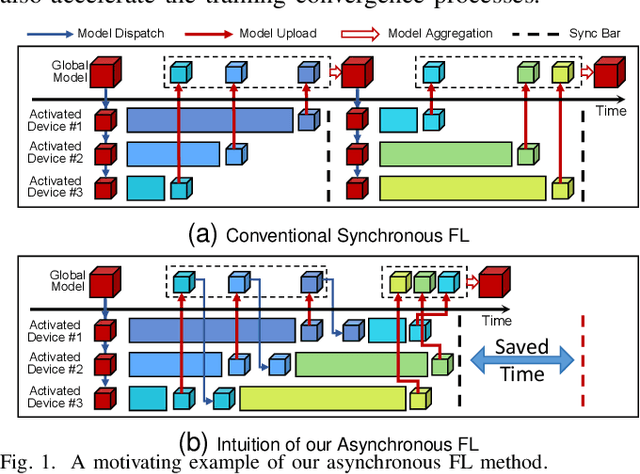
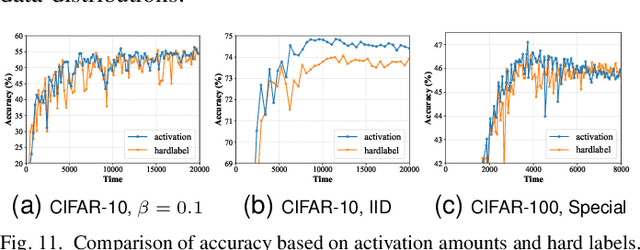

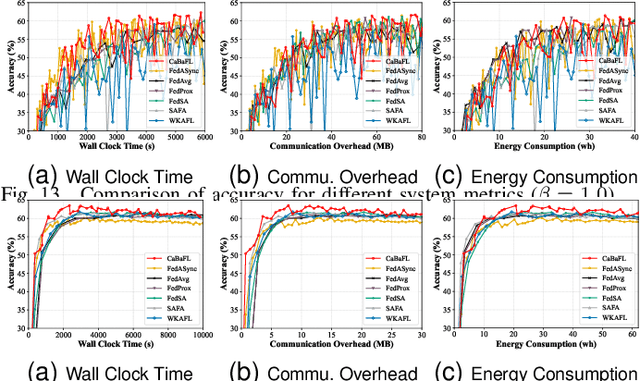
Federated Learning (FL) as a promising distributed machine learning paradigm has been widely adopted in Artificial Intelligence of Things (AIoT) applications. However, the efficiency and inference capability of FL is seriously limited due to the presence of stragglers and data imbalance across massive AIoT devices, respectively. To address the above challenges, we present a novel asynchronous FL approach named CaBaFL, which includes a hierarchical Cache-based aggregation mechanism and a feature Balance-guided device selection strategy. CaBaFL maintains multiple intermediate models simultaneously for local training. The hierarchical cache-based aggregation mechanism enables each intermediate model to be trained on multiple devices to align the training time and mitigate the straggler issue. In specific, each intermediate model is stored in a low-level cache for local training and when it is trained by sufficient local devices, it will be stored in a high-level cache for aggregation. To address the problem of imbalanced data, the feature balance-guided device selection strategy in CaBaFL adopts the activation distribution as a metric, which enables each intermediate model to be trained across devices with totally balanced data distributions before aggregation. Experimental results show that compared with the state-of-the-art FL methods, CaBaFL achieves up to 9.26X training acceleration and 19.71\% accuracy improvements.
KoReA-SFL: Knowledge Replay-based Split Federated Learning Against Catastrophic Forgetting
Apr 19, 2024



Although Split Federated Learning (SFL) is good at enabling knowledge sharing among resource-constrained clients, it suffers from the problem of low training accuracy due to the neglect of data heterogeneity and catastrophic forgetting. To address this issue, we propose a novel SFL approach named KoReA-SFL, which adopts a multi-model aggregation mechanism to alleviate gradient divergence caused by heterogeneous data and a knowledge replay strategy to deal with catastrophic forgetting. Specifically, in KoReA-SFL cloud servers (i.e., fed server and main server) maintain multiple branch model portions rather than a global portion for local training and an aggregated master-model portion for knowledge sharing among branch portions. To avoid catastrophic forgetting, the main server of KoReA-SFL selects multiple assistant devices for knowledge replay according to the training data distribution of each server-side branch-model portion. Experimental results obtained from non-IID and IID scenarios demonstrate that KoReA-SFL significantly outperforms conventional SFL methods (by up to 23.25\% test accuracy improvement).
AdapterFL: Adaptive Heterogeneous Federated Learning for Resource-constrained Mobile Computing Systems
Nov 23, 2023Federated Learning (FL) enables collaborative learning of large-scale distributed clients without data sharing. However, due to the disparity of computing resources among massive mobile computing devices, the performance of traditional homogeneous model-based Federated Learning (FL) is seriously limited. On the one hand, to achieve model training in all the diverse clients, mobile computing systems can only use small low-performance models for collaborative learning. On the other hand, devices with high computing resources cannot train a high-performance large model with their insufficient raw data. To address the resource-constrained problem in mobile computing systems, we present a novel heterogeneous FL approach named AdapterFL, which uses a model reassemble strategy to facilitate collaborative training of massive heterogeneous mobile devices adaptively. Specifically, we select multiple candidate heterogeneous models based on the computing performance of massive mobile devices and then divide each heterogeneous model into two partitions. By reassembling the partitions, we can generate models with varied sizes that are combined by the partial parameters of the large model with the partial parameters of the small model. Using these reassembled models for FL training, we can train the partial parameters of the large model using low-performance devices. In this way, we can alleviate performance degradation in large models due to resource constraints. The experimental results show that AdapterFL can achieve up to 12\% accuracy improvement compared to the state-of-the-art heterogeneous federated learning methods in resource-constrained scenarios.
Have Your Cake and Eat It Too: Toward Efficient and Accurate Split Federated Learning
Nov 22, 2023



Due to its advantages in resource constraint scenarios, Split Federated Learning (SFL) is promising in AIoT systems. However, due to data heterogeneity and stragglers, SFL suffers from the challenges of low inference accuracy and low efficiency. To address these issues, this paper presents a novel SFL approach, named Sliding Split Federated Learning (S$^2$FL), which adopts an adaptive sliding model split strategy and a data balance-based training mechanism. By dynamically dispatching different model portions to AIoT devices according to their computing capability, S$^2$FL can alleviate the low training efficiency caused by stragglers. By combining features uploaded by devices with different data distributions to generate multiple larger batches with a uniform distribution for back-propagation, S$^2$FL can alleviate the performance degradation caused by data heterogeneity. Experimental results demonstrate that, compared to conventional SFL, S$^2$FL can achieve up to 16.5\% inference accuracy improvement and 3.54X training acceleration.
GitFL: Adaptive Asynchronous Federated Learning using Version Control
Nov 22, 2022



As a promising distributed machine learning paradigm that enables collaborative training without compromising data privacy, Federated Learning (FL) has been increasingly used in AIoT (Artificial Intelligence of Things) design. However, due to the lack of efficient management of straggling devices, existing FL methods greatly suffer from the problems of low inference accuracy and long training time. Things become even worse when taking various uncertain factors (e.g., network delays, performance variances caused by process variation) existing in AIoT scenarios into account. To address this issue, this paper proposes a novel asynchronous FL framework named GitFL, whose implementation is inspired by the famous version control system Git. Unlike traditional FL, the cloud server of GitFL maintains a master model (i.e., the global model) together with a set of branch models indicating the trained local models committed by selected devices, where the master model is updated based on both all the pushed branch models and their version information, and only the branch models after the pull operation are dispatched to devices. By using our proposed Reinforcement Learning (RL)-based device selection mechanism, a pulled branch model with an older version will be more likely to be dispatched to a faster and less frequently selected device for the next round of local training. In this way, GitFL enables both effective control of model staleness and adaptive load balance of versioned models among straggling devices, thus avoiding the performance deterioration. Comprehensive experimental results on well-known models and datasets show that, compared with state-of-the-art asynchronous FL methods, GitFL can achieve up to 2.64X training acceleration and 7.88% inference accuracy improvements in various uncertain scenarios.