 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Vulnerability Detection using Federated Learning
Nov 25, 2024Although Deep Learning (DL) methods becoming increasingly popular in vulnerability detection, their performance is seriously limited by insufficient training data. This is mainly because few existing software organizations can maintain a complete set of high-quality samples for DL-based vulnerability detection. Due to the concerns about privacy leakage, most of them are reluctant to share data, resulting in the data silo problem. Since enables collaboratively model training without data sharing, Federated Learning (FL) has been investigated as a promising means of addressing the data silo problem in DL-based vulnerability detection. However, since existing FL-based vulnerability detection methods focus on specific applications, it is still far unclear i) how well FL adapts to common vulnerability detection tasks and ii) how to design a high-performance FL solution for a specific vulnerability detection task. To answer these two questions, this paper first proposes VulFL, an effective evaluation framework for FL-based vulnerability detection. Then, based on VulFL, this paper conducts a comprehensive study to reveal the underlying capabilities of FL in dealing with different types of CWEs, especially when facing various data heterogeneity scenarios. Our experimental results show that, compared to independent training, FL can significantly improve the detection performance of common AI models on all investigated CWEs, though the performance of FL-based vulnerability detection is limited by heterogeneous data. To highlight the performance differences between different FL solutions for vulnerability detection, we extensively investigate the impacts of different configuration strategies for each framework component of VulFL. Our study sheds light on the potential of FL in vulnerability detection, which can be used to guide the design of FL-based solutions for vulnerability detection.
AdaptiveFL: Adaptive Heterogeneous Federated Learning for Resource-Constrained AIoT Systems
Nov 22, 2023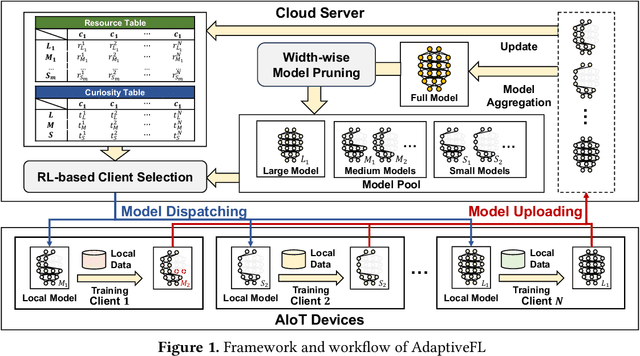
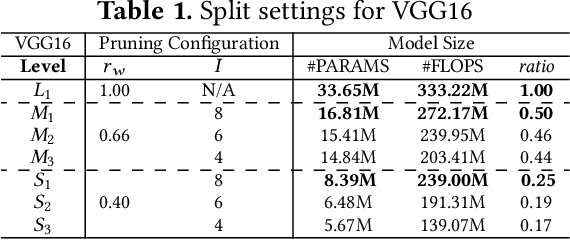
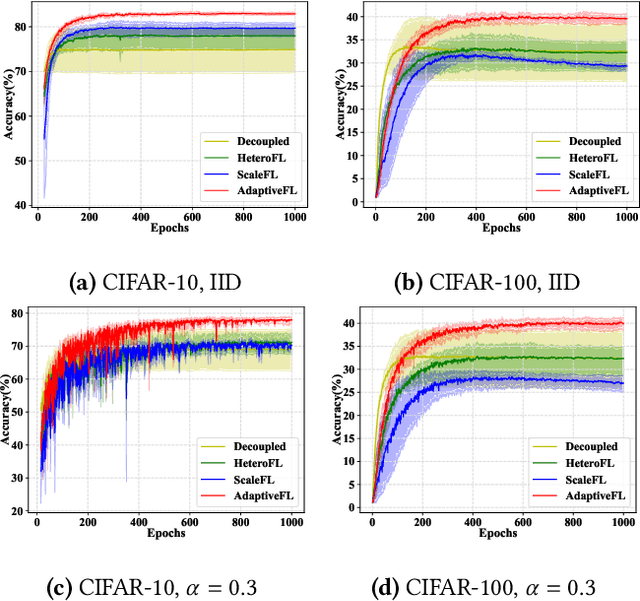
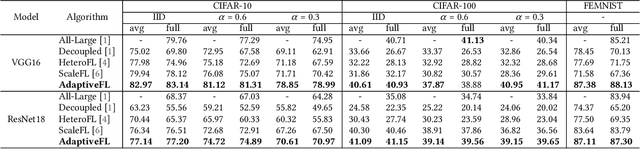
Although Federated Learning (FL) is promising to enable collaborative learning among Artificial Intelligence of Things (AIoT) devices, it suffers from the problem of low classification performance due to various heterogeneity factors (e.g., computing capacity, memory size) of devices and uncertain operating environments. To address these issues, this paper introduces an effective FL approach named AdaptiveFL based on a novel fine-grained width-wise model pruning strategy, which can generate various heterogeneous local models for heterogeneous AIoT devices. By using our proposed reinforcement learning-based device selection mechanism, AdaptiveFL can adaptively dispatch suitable heterogeneous models to corresponding AIoT devices on the fly based on their available resources for local training. Experimental results show that, compared to state-of-the-art methods, AdaptiveFL can achieve up to 16.83% inference improvements for both IID and non-IID scenarios.
Have Your Cake and Eat It Too: Toward Efficient and Accurate Split Federated Learning
Nov 22, 2023



Due to its advantages in resource constraint scenarios, Split Federated Learning (SFL) is promising in AIoT systems. However, due to data heterogeneity and stragglers, SFL suffers from the challenges of low inference accuracy and low efficiency. To address these issues, this paper presents a novel SFL approach, named Sliding Split Federated Learning (S$^2$FL), which adopts an adaptive sliding model split strategy and a data balance-based training mechanism. By dynamically dispatching different model portions to AIoT devices according to their computing capability, S$^2$FL can alleviate the low training efficiency caused by stragglers. By combining features uploaded by devices with different data distributions to generate multiple larger batches with a uniform distribution for back-propagation, S$^2$FL can alleviate the performance degradation caused by data heterogeneity. Experimental results demonstrate that, compared to conventional SFL, S$^2$FL can achieve up to 16.5\% inference accuracy improvement and 3.54X training acceleration.
Protect Federated Learning Against Backdoor Attacks via Data-Free Trigger Generation
Aug 22, 2023
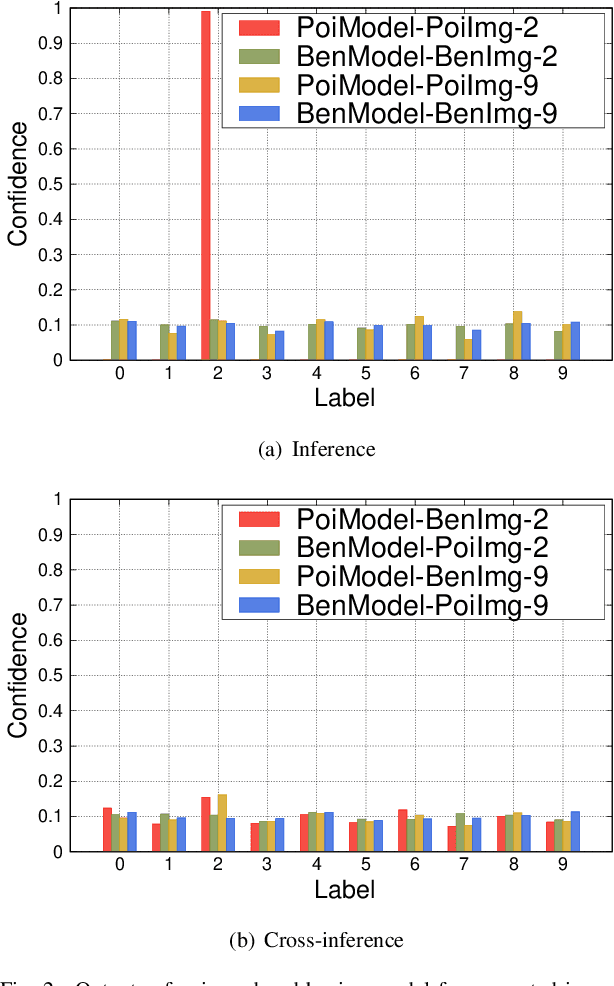
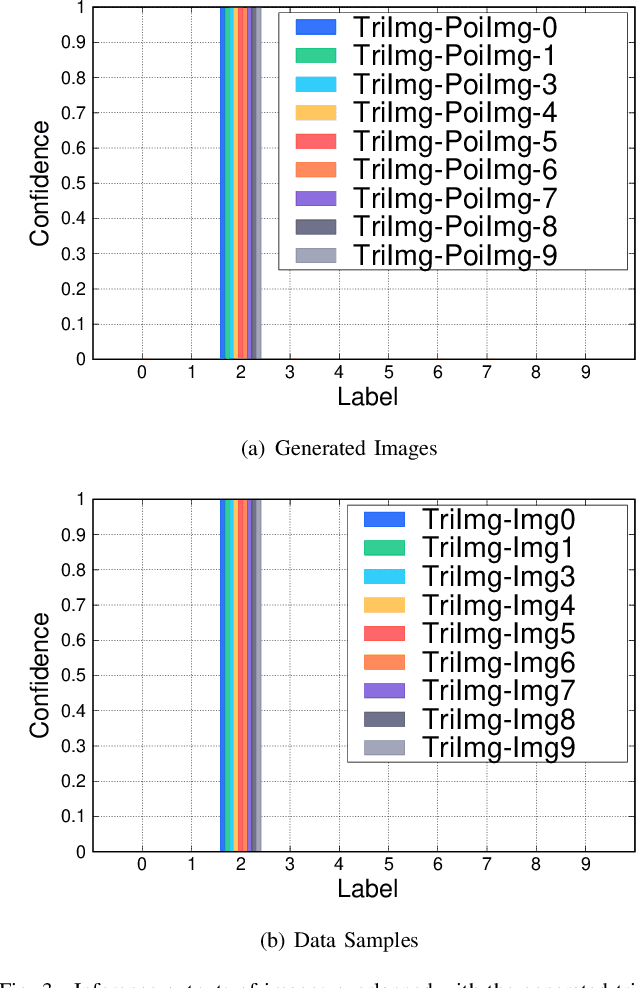
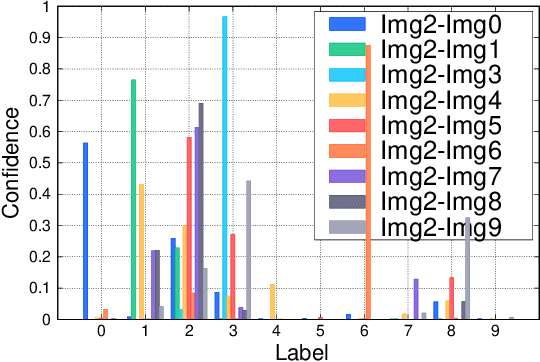
As a distributed machine learning paradigm, Federated Learning (FL) enables large-scale clients to collaboratively train a model without sharing their raw data. However, due to the lack of data auditing for untrusted clients, FL is vulnerable to poisoning attacks, especially backdoor attacks. By using poisoned data for local training or directly changing the model parameters, attackers can easily inject backdoors into the model, which can trigger the model to make misclassification of targeted patterns in images. To address these issues, we propose a novel data-free trigger-generation-based defense approach based on the two characteristics of backdoor attacks: i) triggers are learned faster than normal knowledge, and ii) trigger patterns have a greater effect on image classification than normal class patterns. Our approach generates the images with newly learned knowledge by identifying the differences between the old and new global models, and filters trigger images by evaluating the effect of these generated images. By using these trigger images, our approach eliminates poisoned models to ensure the updated global model is benign. Comprehensive experiments demonstrate that our approach can defend against almost all the existing types of backdoor attacks and outperform all the seven state-of-the-art defense methods with both IID and non-IID scenarios. Especially, our approach can successfully defend against the backdoor attack even when 80\% of the clients are malicious.