 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
An Empirical Study of Vulnerability Detection using Federated Learning
Nov 25, 2024Although Deep Learning (DL) methods becoming increasingly popular in vulnerability detection, their performance is seriously limited by insufficient training data. This is mainly because few existing software organizations can maintain a complete set of high-quality samples for DL-based vulnerability detection. Due to the concerns about privacy leakage, most of them are reluctant to share data, resulting in the data silo problem. Since enables collaboratively model training without data sharing, Federated Learning (FL) has been investigated as a promising means of addressing the data silo problem in DL-based vulnerability detection. However, since existing FL-based vulnerability detection methods focus on specific applications, it is still far unclear i) how well FL adapts to common vulnerability detection tasks and ii) how to design a high-performance FL solution for a specific vulnerability detection task. To answer these two questions, this paper first proposes VulFL, an effective evaluation framework for FL-based vulnerability detection. Then, based on VulFL, this paper conducts a comprehensive study to reveal the underlying capabilities of FL in dealing with different types of CWEs, especially when facing various data heterogeneity scenarios. Our experimental results show that, compared to independent training, FL can significantly improve the detection performance of common AI models on all investigated CWEs, though the performance of FL-based vulnerability detection is limited by heterogeneous data. To highlight the performance differences between different FL solutions for vulnerability detection, we extensively investigate the impacts of different configuration strategies for each framework component of VulFL. Our study sheds light on the potential of FL in vulnerability detection, which can be used to guide the design of FL-based solutions for vulnerability detection.
FedCross: Towards Accurate Federated Learning via Multi-Model Cross Aggregation
Oct 15, 2022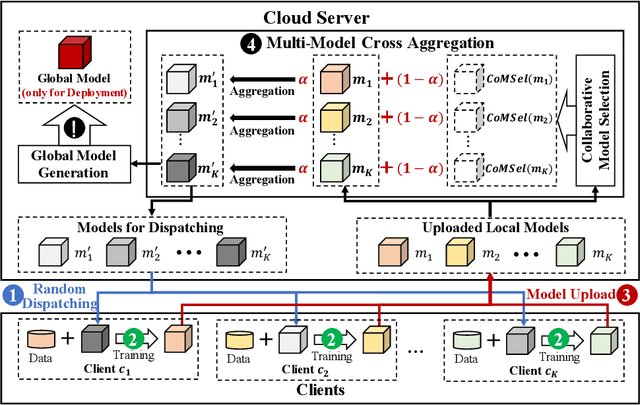

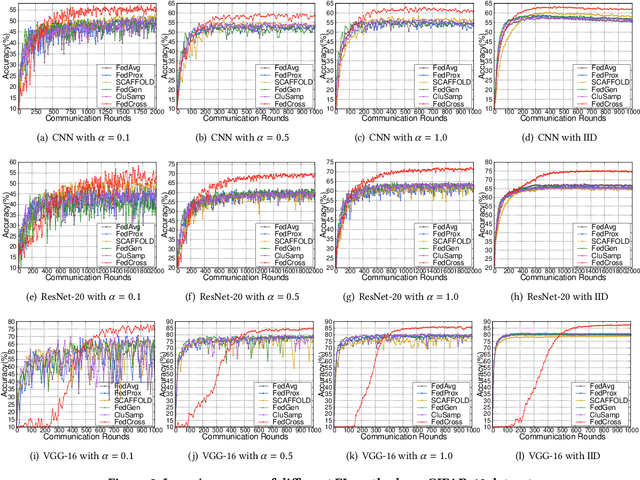
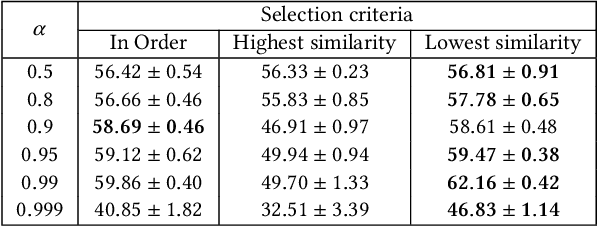
Due to the remarkable performance in preserving data privacy for decentralized data scenarios, Federated Learning (FL) has been considered as a promising distributed machine learning paradigm to deal with data silos problems. Typically, conventional FL approaches adopts a one-to-multi training scheme, where the cloud server keeps only one single global model for all the involved clients for the purpose of model aggregation. However, this scheme suffers from inferior classification performance, since only one global model cannot always accommodate all the incompatible convergence directions of local models, resulting in a low convergence rate and classification accuracy. To address this issue, this paper presents an efficient FL framework named FedCross, which adopts a novel multi-to-multi FL training scheme based on our proposed similarity-based multi-model cross aggregation method. Unlike traditional FL methods, in each round of FL training, FedCross uses a small set of distinct intermediate models to conduct weighted fusion under the guidance of model similarities. In this way, the intermediate models used by FedCross can sufficiently respect the convergence characteristics of clients, thus leading to much fewer conflicts in tuning the convergence directions of clients. Finally, in the deployment stage, FedCross forms a global model for all the clients by performing the federated averaging on the trained immediate models.