 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveAttack: Asymmetric Frequency Obfuscation-based Backdoor Attacks Against Deep Neural Networks
Oct 19, 2023


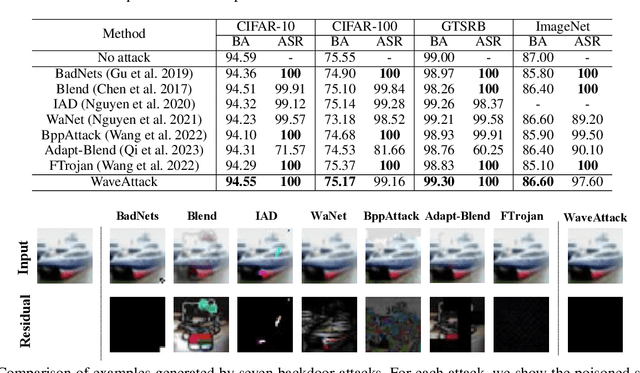
Due to the popularity of Artificial Intelligence (AI) technology, numerous backdoor attacks are designed by adversaries to mislead deep neural network predictions by manipulating training samples and training processes. Although backdoor attacks are effective in various real scenarios, they still suffer from the problems of both low fidelity of poisoned samples and non-negligible transfer in latent space, which make them easily detectable by existing backdoor detection algorithms. To overcome the weakness, this paper proposes a novel frequency-based backdoor attack method named WaveAttack, which obtains image high-frequency features through Discrete Wavelet Transform (DWT) to generate backdoor triggers. Furthermore, we introduce an asymmetric frequency obfuscation method, which can add an adaptive residual in the training and inference stage to improve the impact of triggers and further enhance the effectiveness of WaveAttack. Comprehensive experimental results show that WaveAttack not only achieves higher stealthiness and effectiveness, but also outperforms state-of-the-art (SOTA) backdoor attack methods in the fidelity of images by up to 28.27\% improvement in PSNR, 1.61\% improvement in SSIM, and 70.59\% reduction in IS.
EqGAN: Feature Equalization Fusion for Few-shot Image Generation
Jul 27, 2023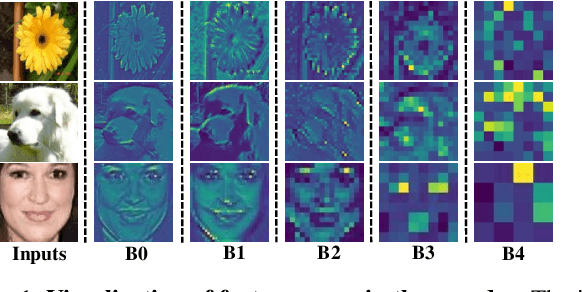
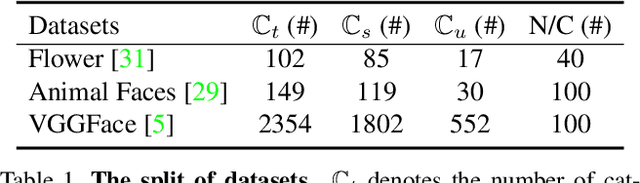
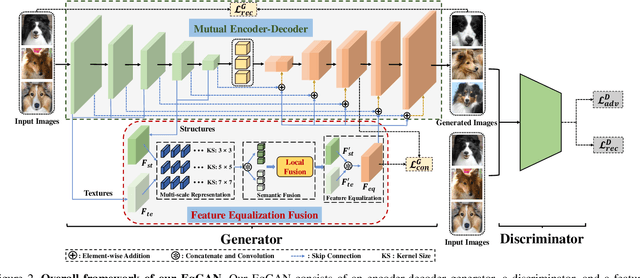
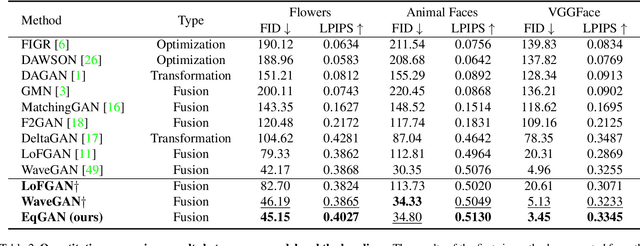
Due to the absence of fine structure and texture information, existing fusion-based few-shot image generation methods suffer from unsatisfactory generation quality and diversity. To address this problem, we propose a novel feature Equalization fusion Generative Adversarial Network (EqGAN) for few-shot image generation. Unlike existing fusion strategies that rely on either deep features or local representations, we design two separate branches to fuse structures and textures by disentangling encoded features into shallow and deep contents. To refine image contents at all feature levels, we equalize the fused structure and texture semantics at different scales and supplement the decoder with richer information by skip connections. Since the fused structures and textures may be inconsistent with each other, we devise a consistent equalization loss between the equalized features and the intermediate output of the decoder to further align the semantics. Comprehensive experiments on three public datasets demonstrate that, EqGAN not only significantly improves generation performance with FID score (by up to 32.7%) and LPIPS score (by up to 4.19%), but also outperforms the state-of-the-arts in terms of accuracy (by up to 1.97%) for downstream classification tasks.
FedMR: Federated Learning via Model Recombination
May 18, 2023Although Federated Learning (FL) enables global model training across clients without compromising their raw data, existing Federated Averaging (FedAvg)-based methods suffer from the problem of low inference performance, especially for unevenly distributed data among clients. This is mainly because i) FedAvg initializes client models with the same global models, which makes the local training hard to escape from the local search for optimal solutions; and ii) by averaging model parameters in a coarse manner, FedAvg eclipses the individual characteristics of local models. To address such issues that strongly limit the inference capability of FL, we propose a novel and effective FL paradigm named FedMR (Federated Model Recombination). Unlike conventional FedAvg-based methods, the cloud server of FedMR shuffles each layer of collected local models and recombines them to achieve new models for local training on clients. Due to the diversified initialization models for clients coupled with fine-grained model recombination, FedMR can converge to a well-generalized global model for all the clients, leading to a superior inference performance. Experimental results show that, compared with state-of-the-art FL methods, FedMR can significantly improve inference accuracy in a quicker manner without exposing client privacy.
HierarchyFL: Heterogeneous Federated Learning via Hierarchical Self-Distillation
Dec 05, 2022Federated learning (FL) has been recognized as a privacy-preserving distributed machine learning paradigm that enables knowledge sharing among various heterogeneous artificial intelligence (AIoT) devices through centralized global model aggregation. FL suffers from model inaccuracy and slow convergence due to the model heterogeneity of the AIoT devices involved. Although various existing methods try to solve the bottleneck of the model heterogeneity problem, most of them improve the accuracy of heterogeneous models in a coarse-grained manner, which makes it still a great challenge to deploy large-scale AIoT devices. To alleviate the negative impact of this problem and take full advantage of the diversity of each heterogeneous model, we propose an efficient framework named HierarchyFL, which uses a small amount of public data for efficient and scalable knowledge across a variety of differently structured models. By using self-distillation and our proposed ensemble library, each hierarchical model can intelligently learn from each other on cloud servers. Experimental results on various well-known datasets show that HierarchyFL can not only maximize the knowledge sharing among various heterogeneous models in large-scale AIoT systems, but also greatly improve the model performance of each involved heterogeneous AIoT device.
GitFL: Adaptive Asynchronous Federated Learning using Version Control
Nov 22, 2022



As a promising distributed machine learning paradigm that enables collaborative training without compromising data privacy, Federated Learning (FL) has been increasingly used in AIoT (Artificial Intelligence of Things) design. However, due to the lack of efficient management of straggling devices, existing FL methods greatly suffer from the problems of low inference accuracy and long training time. Things become even worse when taking various uncertain factors (e.g., network delays, performance variances caused by process variation) existing in AIoT scenarios into account. To address this issue, this paper proposes a novel asynchronous FL framework named GitFL, whose implementation is inspired by the famous version control system Git. Unlike traditional FL, the cloud server of GitFL maintains a master model (i.e., the global model) together with a set of branch models indicating the trained local models committed by selected devices, where the master model is updated based on both all the pushed branch models and their version information, and only the branch models after the pull operation are dispatched to devices. By using our proposed Reinforcement Learning (RL)-based device selection mechanism, a pulled branch model with an older version will be more likely to be dispatched to a faster and less frequently selected device for the next round of local training. In this way, GitFL enables both effective control of model staleness and adaptive load balance of versioned models among straggling devices, thus avoiding the performance deterioration. Comprehensive experimental results on well-known models and datasets show that, compared with state-of-the-art asynchronous FL methods, GitFL can achieve up to 2.64X training acceleration and 7.88% inference accuracy improvements in various uncertain scenarios.
FedCross: Towards Accurate Federated Learning via Multi-Model Cross Aggregation
Oct 15, 2022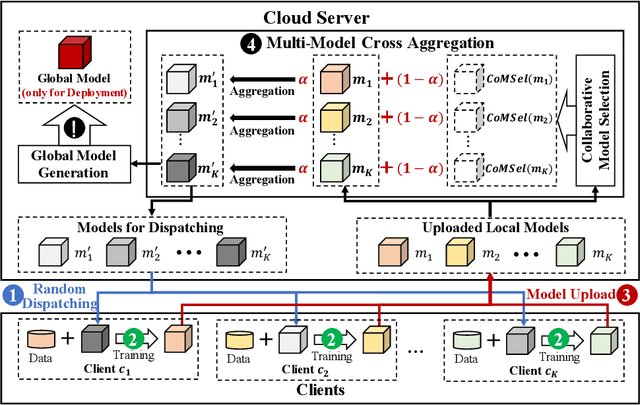

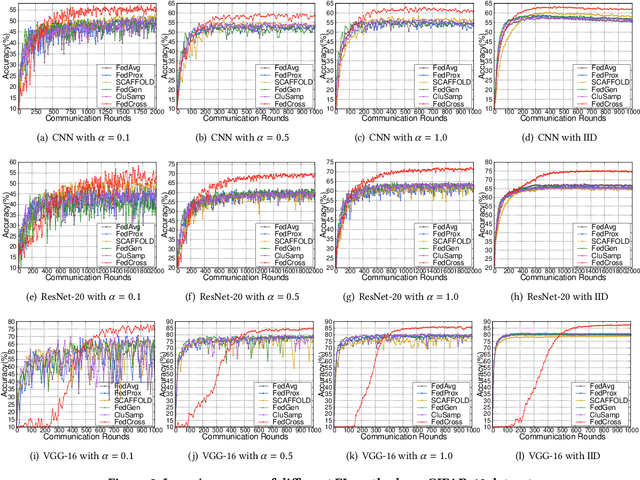
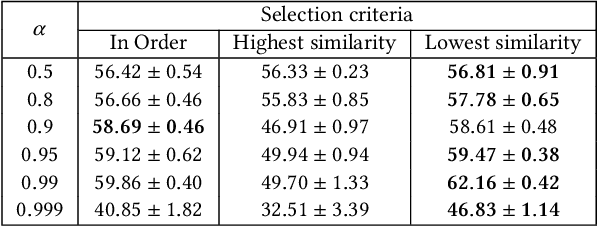
Due to the remarkable performance in preserving data privacy for decentralized data scenarios, Federated Learning (FL) has been considered as a promising distributed machine learning paradigm to deal with data silos problems. Typically, conventional FL approaches adopts a one-to-multi training scheme, where the cloud server keeps only one single global model for all the involved clients for the purpose of model aggregation. However, this scheme suffers from inferior classification performance, since only one global model cannot always accommodate all the incompatible convergence directions of local models, resulting in a low convergence rate and classification accuracy. To address this issue, this paper presents an efficient FL framework named FedCross, which adopts a novel multi-to-multi FL training scheme based on our proposed similarity-based multi-model cross aggregation method. Unlike traditional FL methods, in each round of FL training, FedCross uses a small set of distinct intermediate models to conduct weighted fusion under the guidance of model similarities. In this way, the intermediate models used by FedCross can sufficiently respect the convergence characteristics of clients, thus leading to much fewer conflicts in tuning the convergence directions of clients. Finally, in the deployment stage, FedCross forms a global model for all the clients by performing the federated averaging on the trained immediate models.
FedMR: Fedreated Learning via Model Recombination
Aug 20, 2022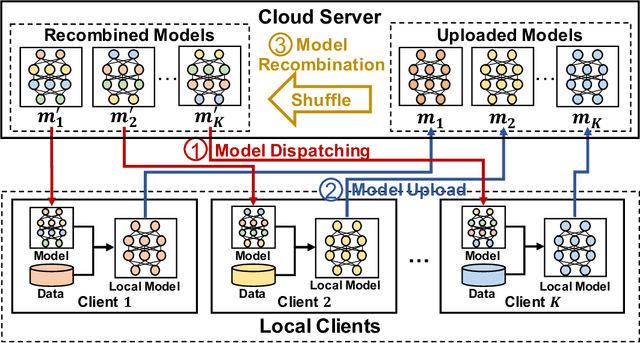
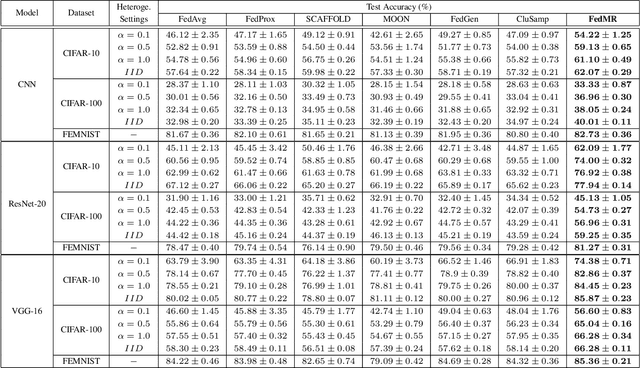
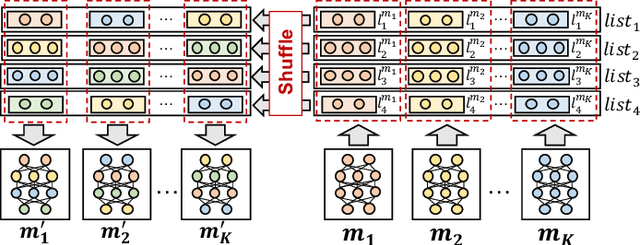
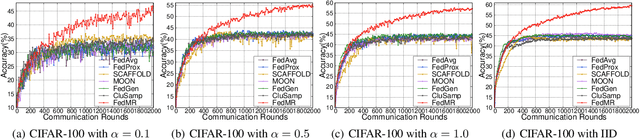
As a promising privacy-preserving machine learning method, Federated Learning (FL) enables global model training across clients without compromising their confidential local data. However, existing FL methods suffer from the problem of low inference performance for unevenly distributed data, since most of them rely on Federated Averaging (FedAvg)-based aggregation. By averaging model parameters in a coarse manner, FedAvg eclipses the individual characteristics of local models, which strongly limits the inference capability of FL. Worse still, in each round of FL training, FedAvg dispatches the same initial local models to clients, which can easily result in stuck-at-local-search for optimal global models. To address the above issues, this paper proposes a novel and effective FL paradigm named FedMR (Federating Model Recombination). Unlike conventional FedAvg-based methods, the cloud server of FedMR shuffles each layer of collected local models and recombines them to achieve new models for local training on clients. Due to the fine-grained model recombination and local training in each FL round, FedMR can quickly figure out one globally optimal model for all the clients. Comprehensive experimental results demonstrate that, compared with state-of-the-art FL methods, FedMR can significantly improve the inference accuracy without causing extra communication overhead.
FedEntropy: Efficient Device Grouping for Federated Learning Using Maximum Entropy Judgment
May 24, 2022

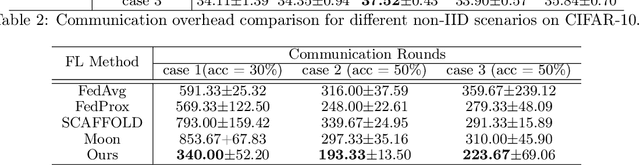
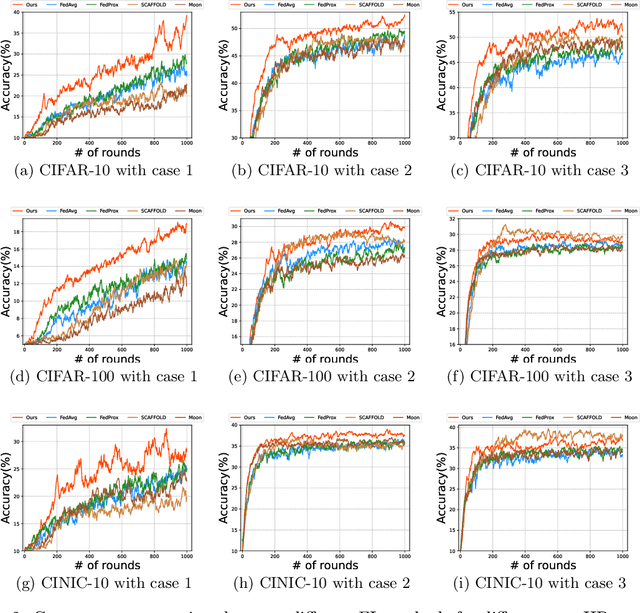
Along with the popularity of Artificial Intelligence (AI) and Internet-of-Things (IoT), Federated Learning (FL) has attracted steadily increasing attentions as a promising distributed machine learning paradigm, which enables the training of a central model on for numerous decentralized devices without exposing their privacy. However, due to the biased data distributions on involved devices, FL inherently suffers from low classification accuracy in non-IID scenarios. Although various device grouping method have been proposed to address this problem, most of them neglect both i) distinct data distribution characteristics of heterogeneous devices, and ii) contributions and hazards of local models, which are extremely important in determining the quality of global model aggregation. In this paper, we present an effective FL method named FedEntropy with a novel dynamic device grouping scheme, which makes full use of the above two factors based on our proposed maximum entropy judgement heuristic.Unlike existing FL methods that directly aggregate local models returned from all the selected devices, in one FL round FedEntropy firstly makes a judgement based on the pre-collected soft labels of selected devices and then only aggregates the local models that can maximize the overall entropy of these soft labels. Without collecting local models that are harmful for aggregation, FedEntropy can effectively improve global model accuracy while reducing the overall communication overhead. Comprehensive experimental results on well-known benchmarks show that, FedEntropy not only outperforms state-of-the-art FL methods in terms of model accuracy and communication overhead, but also can be integrated into them to enhance their classification performance.
Model-Contrastive Learning for Backdoor Defense
May 17, 2022
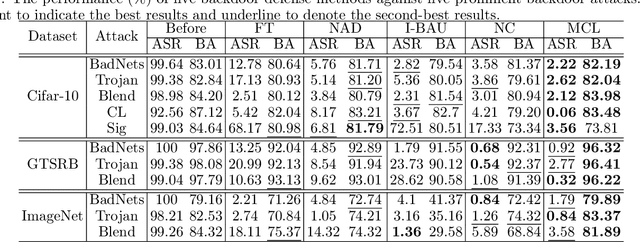

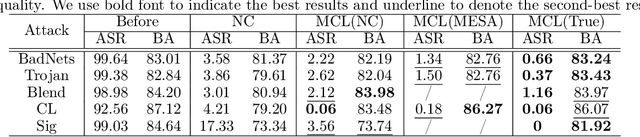
Due to the popularity of Artificial Intelligence (AI) techniques, we are witnessing an increasing number of backdoor injection attacks that are designed to maliciously threaten Deep Neural Networks (DNNs) causing misclassification. Although there exist various defense methods that can effectively erase backdoors from DNNs, they greatly suffer from both high Attack Success Rate (ASR) and a non-negligible loss in Benign Accuracy (BA). Inspired by the observation that a backdoored DNN tends to form a new cluster in its feature spaces for poisoned data, in this paper we propose a novel two-stage backdoor defense method, named MCLDef, based on Model-Contrastive Learning (MCL). In the first stage, our approach performs trigger inversion based on trigger synthesis, where the resultant trigger can be used to generate poisoned data. In the second stage, under the guidance of MCL and our defined positive and negative pairs, MCLDef can purify the backdoored model by pulling the feature representations of poisoned data towards those of their clean data counterparts. Due to the shrunken cluster of poisoned data, the backdoor formed by end-to-end supervised learning is eliminated. Comprehensive experimental results show that, with only 5% of clean data, MCLDef significantly outperforms state-of-the-art defense methods by up to 95.79% reduction in ASR, while in most cases the BA degradation can be controlled within less than 2%. Our code is available at https://github.com/WeCanShow/MCL.
FedCAT: Towards Accurate Federated Learning via Device Concatenation
Feb 23, 2022


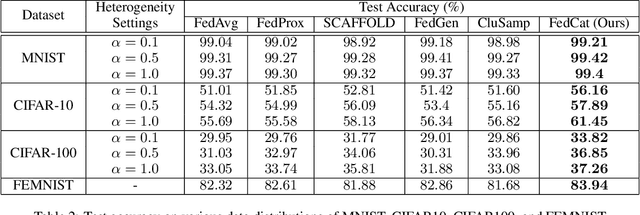
As a promising distributed machine learning paradigm, Federated Learning (FL) enables all the involved devices to train a global model collaboratively without exposing their local data privacy. However, for non-IID scenarios, the classification accuracy of FL models decreases drastically due to the weight divergence caused by data heterogeneity. Although various FL variants have been studied to improve model accuracy, most of them still suffer from the problem of non-negligible communication and computation overhead. In this paper, we introduce a novel FL approach named Fed-Cat that can achieve high model accuracy based on our proposed device selection strategy and device concatenation-based local training method. Unlike conventional FL methods that aggregate local models trained on individual devices, FedCat periodically aggregates local models after their traversals through a series of logically concatenated devices, which can effectively alleviate the model weight divergence problem. Comprehensive experimental results on four well-known benchmarks show that our approach can significantly improve the model accuracy of state-of-the-art FL methods without causing extra communication overhead.