 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerify Claimed Text-to-Image Models via Boundary-Aware Prompt Optimization
Mar 27, 2026As Text-to-Image (T2I) generation becomes widespread, third-party platforms increasingly integrate multiple model APIs for convenient image creation. However, false claims of using official models can mislead users and harm model owners' reputations, making model verification essential to confirm whether an API's underlying model matches its claim. Existing methods address this by using verification prompts generated by official model owners, but the generation relies on multiple reference models for optimization, leading to high computational cost and sensitivity to model selection. To address this problem, we propose a reference-free T2I model verification method called Boundary-aware Prompt Optimization (BPO). It directly explores the intrinsic characteristics of the target model. The key insight is that although different T2I models produce similar outputs for normal prompts, their semantic boundaries in the embedding space (transition zones between two concepts such as "corgi" and "bagel") are distinct. Prompts near these boundaries generate unstable outputs (e.g., sometimes a corgi and sometimes a bagel) on the target model but remain stable on other models. By identifying such boundary-adjacent prompts, BPO captures model-specific behaviors that serve as reliable verification cues for distinguishing T2I models. Experiments on five T2I models and four baselines demonstrate that BPO achieves superior verification accuracy.
Casting a SPELL: Sentence Pairing Exploration for LLM Limitation-breaking
Dec 24, 2025Large language models (LLMs) have revolutionized software development through AI-assisted coding tools, enabling developers with limited programming expertise to create sophisticated applications. However, this accessibility extends to malicious actors who may exploit these powerful tools to generate harmful software. Existing jailbreaking research primarily focuses on general attack scenarios against LLMs, with limited exploration of malicious code generation as a jailbreak target. To address this gap, we propose SPELL, a comprehensive testing framework specifically designed to evaluate the weakness of security alignment in malicious code generation. Our framework employs a time-division selection strategy that systematically constructs jailbreaking prompts by intelligently combining sentences from a prior knowledge dataset, balancing exploration of novel attack patterns with exploitation of successful techniques. Extensive evaluation across three advanced code models (GPT-4.1, Claude-3.5, and Qwen2.5-Coder) demonstrates SPELL's effectiveness, achieving attack success rates of 83.75%, 19.38%, and 68.12% respectively across eight malicious code categories. The generated prompts successfully produce malicious code in real-world AI development tools such as Cursor, with outputs confirmed as malicious by state-of-the-art detection systems at rates exceeding 73%. These findings reveal significant security gaps in current LLM implementations and provide valuable insights for improving AI safety alignment in code generation applications.
Shedding Light on VLN Robustness: A Black-box Framework for Indoor Lighting-based Adversarial Attack
Nov 17, 2025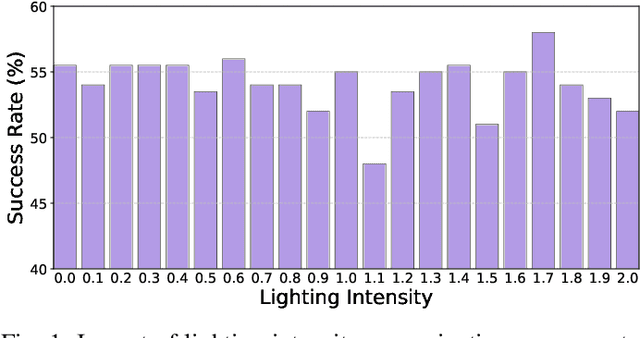
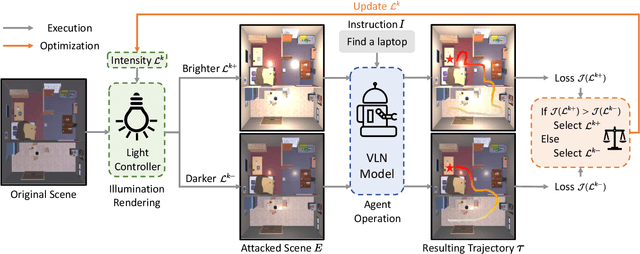
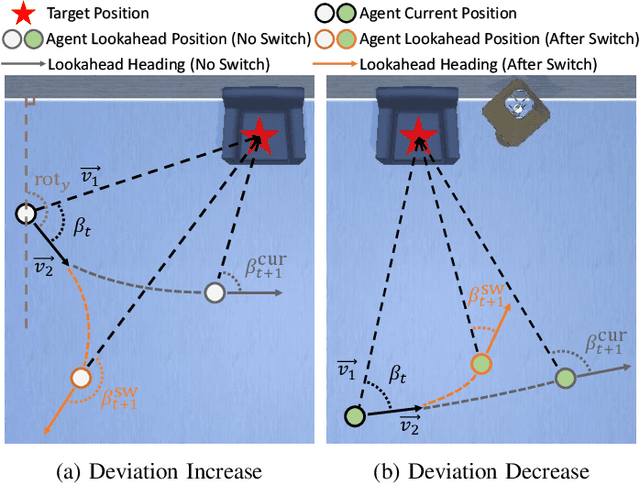

Vision-and-Language Navigation (VLN) agents have made remarkable progress, but their robustness remains insufficiently studied. Existing adversarial evaluations often rely on perturbations that manifest as unusual textures rarely encountered in everyday indoor environments. Errors under such contrived conditions have limited practical relevance, as real-world agents are unlikely to encounter such artificial patterns. In this work, we focus on indoor lighting, an intrinsic yet largely overlooked scene attribute that strongly influences navigation. We propose Indoor Lighting-based Adversarial Attack (ILA), a black-box framework that manipulates global illumination to disrupt VLN agents. Motivated by typical household lighting usage, we design two attack modes: Static Indoor Lighting-based Attack (SILA), where the lighting intensity remains constant throughout an episode, and Dynamic Indoor Lighting-based Attack (DILA), where lights are switched on or off at critical moments to induce abrupt illumination changes. We evaluate ILA on two state-of-the-art VLN models across three navigation tasks. Results show that ILA significantly increases failure rates while reducing trajectory efficiency, revealing previously unrecognized vulnerabilities of VLN agents to realistic indoor lighting variations.
Beyond Pixels: Semantic-aware Typographic Attack for Geo-Privacy Protection
Nov 16, 2025Large Visual Language Models (LVLMs) now pose a serious yet overlooked privacy threat, as they can infer a social media user's geolocation directly from shared images, leading to unintended privacy leakage. While adversarial image perturbations provide a potential direction for geo-privacy protection, they require relatively strong distortions to be effective against LVLMs, which noticeably degrade visual quality and diminish an image's value for sharing. To overcome this limitation, we identify typographical attacks as a promising direction for protecting geo-privacy by adding text extension outside the visual content. We further investigate which textual semantics are effective in disrupting geolocation inference and design a two-stage, semantics-aware typographical attack that generates deceptive text to protect user privacy. Extensive experiments across three datasets demonstrate that our approach significantly reduces geolocation prediction accuracy of five state-of-the-art commercial LVLMs, establishing a practical and visually-preserving protection strategy against emerging geo-privacy threats.
Adversarial Attacks against Closed-Source MLLMs via Feature Optimal Alignment
May 27, 2025Multimodal large language models (MLLMs) remain vulnerable to transferable adversarial examples. While existing methods typically achieve targeted attacks by aligning global features-such as CLIP's [CLS] token-between adversarial and target samples, they often overlook the rich local information encoded in patch tokens. This leads to suboptimal alignment and limited transferability, particularly for closed-source models. To address this limitation, we propose a targeted transferable adversarial attack method based on feature optimal alignment, called FOA-Attack, to improve adversarial transfer capability. Specifically, at the global level, we introduce a global feature loss based on cosine similarity to align the coarse-grained features of adversarial samples with those of target samples. At the local level, given the rich local representations within Transformers, we leverage clustering techniques to extract compact local patterns to alleviate redundant local features. We then formulate local feature alignment between adversarial and target samples as an optimal transport (OT) problem and propose a local clustering optimal transport loss to refine fine-grained feature alignment. Additionally, we propose a dynamic ensemble model weighting strategy to adaptively balance the influence of multiple models during adversarial example generation, thereby further improving transferability. Extensive experiments across various models demonstrate the superiority of the proposed method, outperforming state-of-the-art methods, especially in transferring to closed-source MLLMs. The code is released at https://github.com/jiaxiaojunQAQ/FOA-Attack.
A Vision for Auto Research with LLM Agents
Apr 26, 2025This paper introduces Agent-Based Auto Research, a structured multi-agent framework designed to automate, coordinate, and optimize the full lifecycle of scientific research. Leveraging the capabilities of large language models (LLMs) and modular agent collaboration, the system spans all major research phases, including literature review, ideation, methodology planning, experimentation, paper writing, peer review response, and dissemination. By addressing issues such as fragmented workflows, uneven methodological expertise, and cognitive overload, the framework offers a systematic and scalable approach to scientific inquiry. Preliminary explorations demonstrate the feasibility and potential of Auto Research as a promising paradigm for self-improving, AI-driven research processes.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
Privacy Protection Against Personalized Text-to-Image Synthesis via Cross-image Consistency Constraints
Apr 17, 2025The rapid advancement of diffusion models and personalization techniques has made it possible to recreate individual portraits from just a few publicly available images. While such capabilities empower various creative applications, they also introduce serious privacy concerns, as adversaries can exploit them to generate highly realistic impersonations. To counter these threats, anti-personalization methods have been proposed, which add adversarial perturbations to published images to disrupt the training of personalization models. However, existing approaches largely overlook the intrinsic multi-image nature of personalization and instead adopt a naive strategy of applying perturbations independently, as commonly done in single-image settings. This neglects the opportunity to leverage inter-image relationships for stronger privacy protection. Therefore, we advocate for a group-level perspective on privacy protection against personalization. Specifically, we introduce Cross-image Anti-Personalization (CAP), a novel framework that enhances resistance to personalization by enforcing style consistency across perturbed images. Furthermore, we develop a dynamic ratio adjustment strategy that adaptively balances the impact of the consistency loss throughout the attack iterations. Extensive experiments on the classical CelebHQ and VGGFace2 benchmarks show that CAP substantially improves existing methods.
PATFinger: Prompt-Adapted Transferable Fingerprinting against Unauthorized Multimodal Dataset Usage
Apr 15, 2025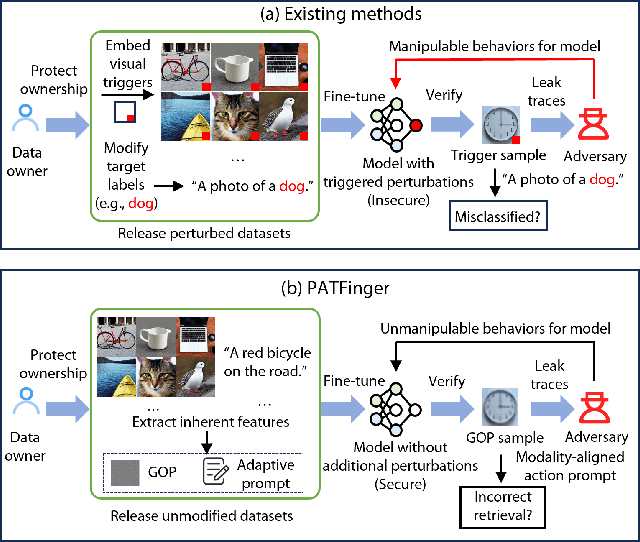
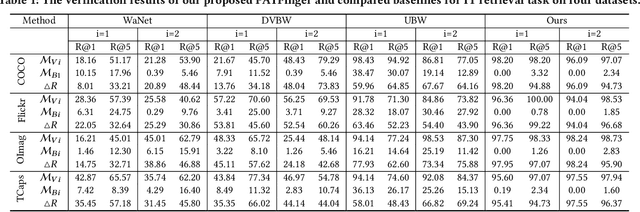
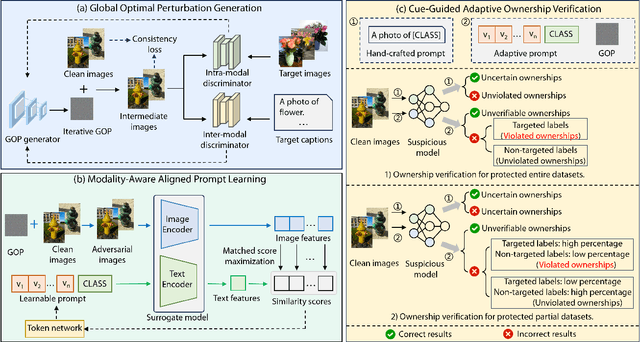
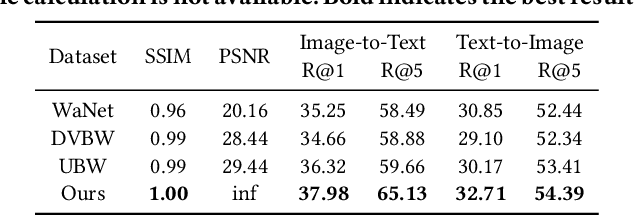
The multimodal datasets can be leveraged to pre-train large-scale vision-language models by providing cross-modal semantics. Current endeavors for determining the usage of datasets mainly focus on single-modal dataset ownership verification through intrusive methods and non-intrusive techniques, while cross-modal approaches remain under-explored. Intrusive methods can adapt to multimodal datasets but degrade model accuracy, while non-intrusive methods rely on label-driven decision boundaries that fail to guarantee stable behaviors for verification. To address these issues, we propose a novel prompt-adapted transferable fingerprinting scheme from a training-free perspective, called PATFinger, which incorporates the global optimal perturbation (GOP) and the adaptive prompts to capture dataset-specific distribution characteristics. Our scheme utilizes inherent dataset attributes as fingerprints instead of compelling the model to learn triggers. The GOP is derived from the sample distribution to maximize embedding drifts between different modalities. Subsequently, our PATFinger re-aligns the adaptive prompt with GOP samples to capture the cross-modal interactions on the carefully crafted surrogate model. This allows the dataset owner to check the usage of datasets by observing specific prediction behaviors linked to the PATFinger during retrieval queries. Extensive experiments demonstrate the effectiveness of our scheme against unauthorized multimodal dataset usage on various cross-modal retrieval architectures by 30% over state-of-the-art baselines.
Evolution-based Region Adversarial Prompt Learning for Robustness Enhancement in Vision-Language Models
Mar 17, 2025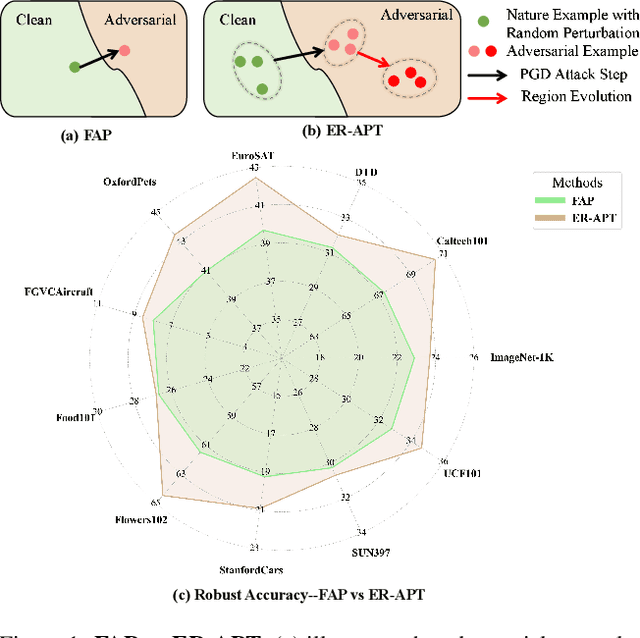
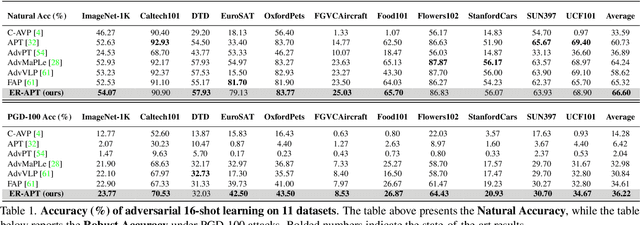
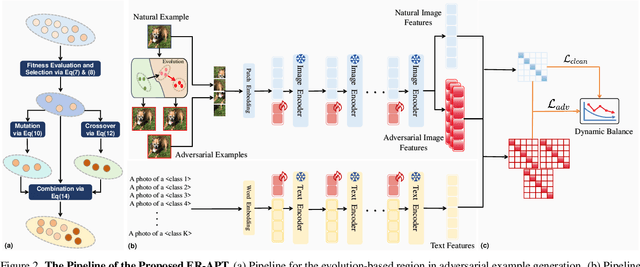
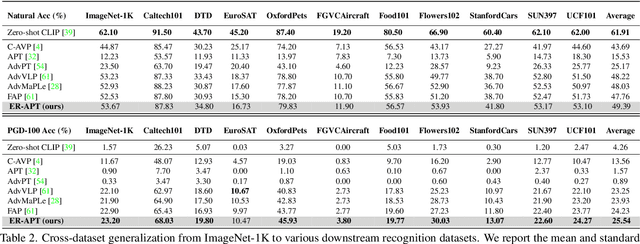
Large pre-trained vision-language models (VLMs), such as CLIP, demonstrate impressive generalization but remain highly vulnerable to adversarial examples (AEs). Previous work has explored robust text prompts through adversarial training, achieving some improvement in both robustness and generalization. However, they primarily rely on singlegradient direction perturbations (e.g., PGD) to generate AEs, which lack diversity, resulting in limited improvement in adversarial robustness. To address these limitations, we propose an evolution-based region adversarial prompt tuning method called ER-APT, which combines gradient methods with genetic evolution to generate more diverse and challenging AEs. In each training iteration, we first generate AEs using traditional gradient-based methods. Subsequently, a genetic evolution mechanism incorporating selection, mutation, and crossover is applied to optimize the AEs, ensuring a broader and more aggressive perturbation distribution.The final evolved AEs are used for prompt tuning, achieving region-based adversarial optimization instead of conventional single-point adversarial prompt tuning. We also propose a dynamic loss weighting method to adjust prompt learning efficiency for accuracy and robustness. Experimental evaluations on various benchmark datasets demonstrate the superiority of our proposed method, outperforming stateof-the-art APT methods. The code is released at https://github.com/jiaxiaojunQAQ/ER-APT.