 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning as an Attack Surface: Adaptive Evolutionary CoT Jailbreaks for LLMs
May 23, 2026Large Reasoning Models (LRMs) have demonstrated remarkable capabilities in reasoning and generation tasks and are increasingly deployed in real-world applications. However, their explicit chain-of-thought (CoT) mechanism introduces new security risks, making them particularly vulnerable to jailbreak attacks. Existing approaches often rely on static CoT templates to elicit harmful outputs, but such fixed designs suffer from limited diversity, adaptability, and effectiveness. To overcome these limitations, we propose an adaptive evolutionary CoT jailbreak framework, called AE-CoT. Specifically, the method first rewrites harmful goals into mild prompts with teacher role-play and decomposes them into semantically coherent reasoning fragments to construct a pool of CoT jailbreak candidates. Then, within a structured representation space, we perform multi-generation evolutionary search, where candidate diversity is expanded through fragment-level crossover and a mutation strategy with an adaptive mutation-rate control mechanism. An independent scoring model provides graded harmfulness evaluations, and high-scoring candidates are further enhanced with a harmful CoT template to induce more destructive generations. Extensive experiments across multiple models and datasets demonstrate the effectiveness of the proposed AE-CoT, consistently outperforming state-of-the-art jailbreak methods.
ODAR: Principled Adaptive Routing for LLM Reasoning via Active Inference
Feb 27, 2026The paradigm of large language model (LLM) reasoning is shifting from parameter scaling to test-time compute scaling, yet many existing approaches still rely on uniform brute-force sampling (for example, fixed best-of-N or self-consistency) that is costly, hard to attribute, and can trigger overthinking with diminishing returns. We propose ODAR-Expert, an adaptive routing framework that optimizes the accuracy-efficiency trade-off via principled resource allocation. ODAR uses a difficulty estimator grounded in amortized active inference to dynamically route queries between a heuristic Fast Agent and a deliberative Slow Agent. We further introduce a free-energy-principled, risk-sensitive fusion mechanism that selects answers by minimizing a variational free energy objective, balancing log-likelihood with epistemic uncertainty (varentropy) as a principled alternative to ad hoc voting over heterogeneous candidates. Extensive evaluation across 23 benchmarks shows strong and consistent gains, including 98.2% accuracy on MATH and 54.8% on Humanity's Last Exam (HLE), while improving the compute-accuracy frontier under compute-matched settings. We also validate reproducibility on a fully open-source stack (Llama 4 + DeepSeek), where ODAR surpasses homogeneous sampling strategies while reducing computational costs by 82%. Overall, our results suggest that thinking-optimal scaling requires adaptive resource allocation with free-energy-based decision-making rather than simply increasing test-time compute.
Obscure but Effective: Classical Chinese Jailbreak Prompt Optimization via Bio-Inspired Search
Feb 26, 2026As Large Language Models (LLMs) are increasingly used, their security risks have drawn increasing attention. Existing research reveals that LLMs are highly susceptible to jailbreak attacks, with effectiveness varying across language contexts. This paper investigates the role of classical Chinese in jailbreak attacks. Owing to its conciseness and obscurity, classical Chinese can partially bypass existing safety constraints, exposing notable vulnerabilities in LLMs. Based on this observation, this paper proposes a framework, CC-BOS, for the automatic generation of classical Chinese adversarial prompts based on multi-dimensional fruit fly optimization, facilitating efficient and automated jailbreak attacks in black-box settings. Prompts are encoded into eight policy dimensions-covering role, behavior, mechanism, metaphor, expression, knowledge, trigger pattern and context; and iteratively refined via smell search, visual search, and cauchy mutation. This design enables efficient exploration of the search space, thereby enhancing the effectiveness of black-box jailbreak attacks. To enhance readability and evaluation accuracy, we further design a classical Chinese to English translation module. Extensive experiments demonstrate that effectiveness of the proposed CC-BOS, consistently outperforming state-of-the-art jailbreak attack methods.
SkillJect: Automating Stealthy Skill-Based Prompt Injection for Coding Agents with Trace-Driven Closed-Loop Refinement
Feb 15, 2026Agent skills are becoming a core abstraction in coding agents, packaging long-form instructions and auxiliary scripts to extend tool-augmented behaviors. This abstraction introduces an under-measured attack surface: skill-based prompt injection, where poisoned skills can steer agents away from user intent and safety policies. In practice, naive injections often fail because the malicious intent is too explicit or drifts too far from the original skill, leading agents to ignore or refuse them; existing attacks are also largely hand-crafted. We propose the first automated framework for stealthy prompt injection tailored to agent skills. The framework forms a closed loop with three agents: an Attack Agent that synthesizes injection skills under explicit stealth constraints, a Code Agent that executes tasks using the injected skills in a realistic tool environment, and an Evaluate Agent that logs action traces (e.g., tool calls and file operations) and verifies whether targeted malicious behaviors occurred. We also propose a malicious payload hiding strategy that conceals adversarial operations in auxiliary scripts while injecting optimized inducement prompts to trigger tool execution. Extensive experiments across diverse coding-agent settings and real-world software engineering tasks show that our method consistently achieves high attack success rates under realistic settings.
Advances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
SugarTextNet: A Transformer-Based Framework for Detecting Sugar Dating-Related Content on Social Media with Context-Aware Focal Loss
Nov 11, 2025


Sugar dating-related content has rapidly proliferated on mainstream social media platforms, giving rise to serious societal and regulatory concerns, including commercialization of intimate relationships and the normalization of transactional relationships.~Detecting such content is highly challenging due to the prevalence of subtle euphemisms, ambiguous linguistic cues, and extreme class imbalance in real-world data.~In this work, we present SugarTextNet, a novel transformer-based framework specifically designed to identify sugar dating-related posts on social media.~SugarTextNet integrates a pretrained transformer encoder, an attention-based cue extractor, and a contextual phrase encoder to capture both salient and nuanced features in user-generated text.~To address class imbalance and enhance minority-class detection, we introduce Context-Aware Focal Loss, a tailored loss function that combines focal loss scaling with contextual weighting.~We evaluate SugarTextNet on a newly curated, manually annotated dataset of 3,067 Chinese social media posts from Sina Weibo, demonstrating that our approach substantially outperforms traditional machine learning models, deep learning baselines, and large language models across multiple metrics.~Comprehensive ablation studies confirm the indispensable role of each component.~Our findings highlight the importance of domain-specific, context-aware modeling for sensitive content detection, and provide a robust solution for content moderation in complex, real-world scenarios.
PhysPatch: A Physically Realizable and Transferable Adversarial Patch Attack for Multimodal Large Language Models-based Autonomous Driving Systems
Aug 07, 2025



Multimodal Large Language Models (MLLMs) are becoming integral to autonomous driving (AD) systems due to their strong vision-language reasoning capabilities. However, MLLMs are vulnerable to adversarial attacks, particularly adversarial patch attacks, which can pose serious threats in real-world scenarios. Existing patch-based attack methods are primarily designed for object detection models and perform poorly when transferred to MLLM-based systems due to the latter's complex architectures and reasoning abilities. To address these limitations, we propose PhysPatch, a physically realizable and transferable adversarial patch framework tailored for MLLM-based AD systems. PhysPatch jointly optimizes patch location, shape, and content to enhance attack effectiveness and real-world applicability. It introduces a semantic-based mask initialization strategy for realistic placement, an SVD-based local alignment loss with patch-guided crop-resize to improve transferability, and a potential field-based mask refinement method. Extensive experiments across open-source, commercial, and reasoning-capable MLLMs demonstrate that PhysPatch significantly outperforms prior methods in steering MLLM-based AD systems toward target-aligned perception and planning outputs. Moreover, PhysPatch consistently places adversarial patches in physically feasible regions of AD scenes, ensuring strong real-world applicability and deployability.
Adversarial Attacks against Closed-Source MLLMs via Feature Optimal Alignment
May 27, 2025Multimodal large language models (MLLMs) remain vulnerable to transferable adversarial examples. While existing methods typically achieve targeted attacks by aligning global features-such as CLIP's [CLS] token-between adversarial and target samples, they often overlook the rich local information encoded in patch tokens. This leads to suboptimal alignment and limited transferability, particularly for closed-source models. To address this limitation, we propose a targeted transferable adversarial attack method based on feature optimal alignment, called FOA-Attack, to improve adversarial transfer capability. Specifically, at the global level, we introduce a global feature loss based on cosine similarity to align the coarse-grained features of adversarial samples with those of target samples. At the local level, given the rich local representations within Transformers, we leverage clustering techniques to extract compact local patterns to alleviate redundant local features. We then formulate local feature alignment between adversarial and target samples as an optimal transport (OT) problem and propose a local clustering optimal transport loss to refine fine-grained feature alignment. Additionally, we propose a dynamic ensemble model weighting strategy to adaptively balance the influence of multiple models during adversarial example generation, thereby further improving transferability. Extensive experiments across various models demonstrate the superiority of the proposed method, outperforming state-of-the-art methods, especially in transferring to closed-source MLLMs. The code is released at https://github.com/jiaxiaojunQAQ/FOA-Attack.
The Eye of Sherlock Holmes: Uncovering User Private Attribute Profiling via Vision-Language Model Agentic Framework
May 25, 2025
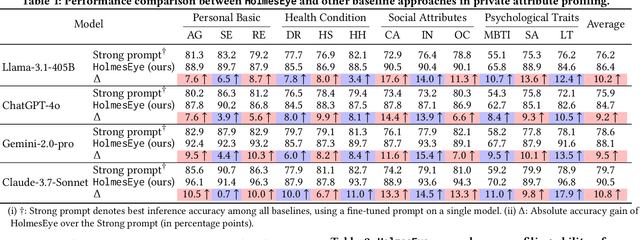
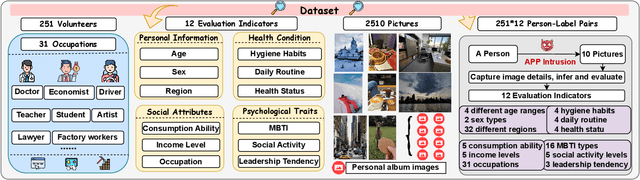

Our research reveals a new privacy risk associated with the vision-language model (VLM) agentic framework: the ability to infer sensitive attributes (e.g., age and health information) and even abstract ones (e.g., personality and social traits) from a set of personal images, which we term "image private attribute profiling." This threat is particularly severe given that modern apps can easily access users' photo albums, and inference from image sets enables models to exploit inter-image relations for more sophisticated profiling. However, two main challenges hinder our understanding of how well VLMs can profile an individual from a few personal photos: (1) the lack of benchmark datasets with multi-image annotations for private attributes, and (2) the limited ability of current multimodal large language models (MLLMs) to infer abstract attributes from large image collections. In this work, we construct PAPI, the largest dataset for studying private attribute profiling in personal images, comprising 2,510 images from 251 individuals with 3,012 annotated privacy attributes. We also propose HolmesEye, a hybrid agentic framework that combines VLMs and LLMs to enhance privacy inference. HolmesEye uses VLMs to extract both intra-image and inter-image information and LLMs to guide the inference process as well as consolidate the results through forensic analysis, overcoming existing limitations in long-context visual reasoning. Experiments reveal that HolmesEye achieves a 10.8% improvement in average accuracy over state-of-the-art baselines and surpasses human-level performance by 15.0% in predicting abstract attributes. This work highlights the urgency of addressing privacy risks in image-based profiling and offers both a new dataset and an advanced framework to guide future research in this area.
Evolution-based Region Adversarial Prompt Learning for Robustness Enhancement in Vision-Language Models
Mar 17, 2025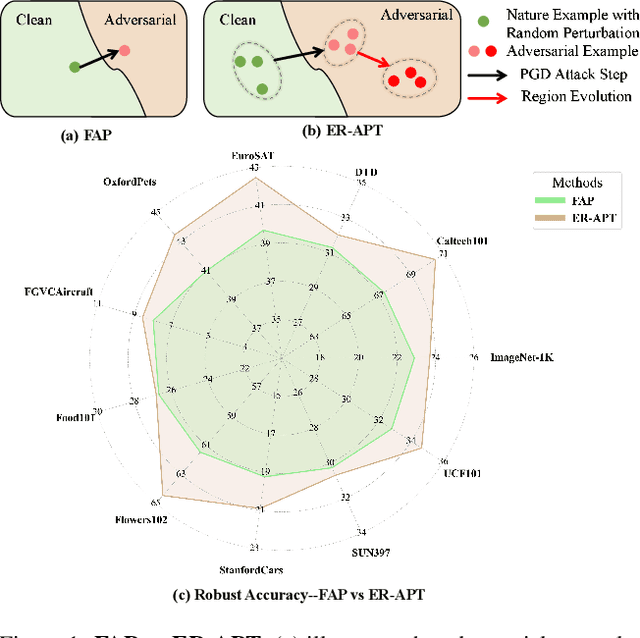
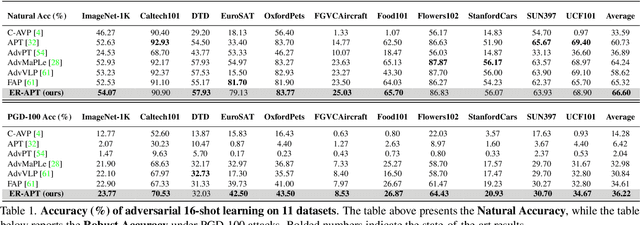
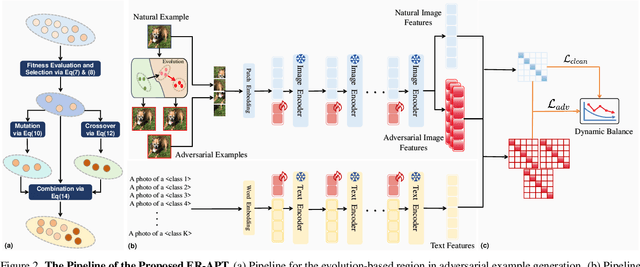
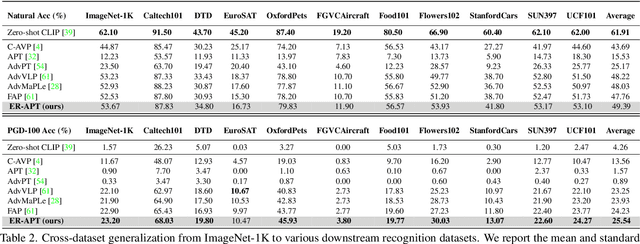
Large pre-trained vision-language models (VLMs), such as CLIP, demonstrate impressive generalization but remain highly vulnerable to adversarial examples (AEs). Previous work has explored robust text prompts through adversarial training, achieving some improvement in both robustness and generalization. However, they primarily rely on singlegradient direction perturbations (e.g., PGD) to generate AEs, which lack diversity, resulting in limited improvement in adversarial robustness. To address these limitations, we propose an evolution-based region adversarial prompt tuning method called ER-APT, which combines gradient methods with genetic evolution to generate more diverse and challenging AEs. In each training iteration, we first generate AEs using traditional gradient-based methods. Subsequently, a genetic evolution mechanism incorporating selection, mutation, and crossover is applied to optimize the AEs, ensuring a broader and more aggressive perturbation distribution.The final evolved AEs are used for prompt tuning, achieving region-based adversarial optimization instead of conventional single-point adversarial prompt tuning. We also propose a dynamic loss weighting method to adjust prompt learning efficiency for accuracy and robustness. Experimental evaluations on various benchmark datasets demonstrate the superiority of our proposed method, outperforming stateof-the-art APT methods. The code is released at https://github.com/jiaxiaojunQAQ/ER-APT.