 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-MGTD: Privacy-Preserving Machine-Generated Text Detection via Adaptive Differentially Private Entity Sanitization
Jan 08, 2026The deployment of Machine-Generated Text (MGT) detection systems necessitates processing sensitive user data, creating a fundamental conflict between authorship verification and privacy preservation. Standard anonymization techniques often disrupt linguistic fluency, while rigorous Differential Privacy (DP) mechanisms typically degrade the statistical signals required for accurate detection. To resolve this dilemma, we propose \textbf{DP-MGTD}, a framework incorporating an Adaptive Differentially Private Entity Sanitization algorithm. Our approach utilizes a two-stage mechanism that performs noisy frequency estimation and dynamically calibrates privacy budgets, applying Laplace and Exponential mechanisms to numerical and textual entities respectively. Crucially, we identify a counter-intuitive phenomenon where the application of DP noise amplifies the distinguishability between human and machine text by exposing distinct sensitivity patterns to perturbation. Extensive experiments on the MGTBench-2.0 dataset show that our method achieves near-perfect detection accuracy, significantly outperforming non-private baselines while satisfying strict privacy guarantees.
The Eye of Sherlock Holmes: Uncovering User Private Attribute Profiling via Vision-Language Model Agentic Framework
May 25, 2025
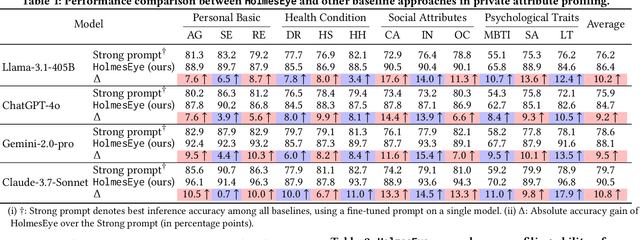
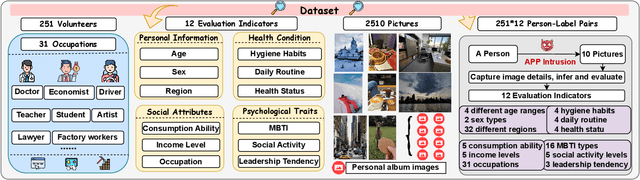

Our research reveals a new privacy risk associated with the vision-language model (VLM) agentic framework: the ability to infer sensitive attributes (e.g., age and health information) and even abstract ones (e.g., personality and social traits) from a set of personal images, which we term "image private attribute profiling." This threat is particularly severe given that modern apps can easily access users' photo albums, and inference from image sets enables models to exploit inter-image relations for more sophisticated profiling. However, two main challenges hinder our understanding of how well VLMs can profile an individual from a few personal photos: (1) the lack of benchmark datasets with multi-image annotations for private attributes, and (2) the limited ability of current multimodal large language models (MLLMs) to infer abstract attributes from large image collections. In this work, we construct PAPI, the largest dataset for studying private attribute profiling in personal images, comprising 2,510 images from 251 individuals with 3,012 annotated privacy attributes. We also propose HolmesEye, a hybrid agentic framework that combines VLMs and LLMs to enhance privacy inference. HolmesEye uses VLMs to extract both intra-image and inter-image information and LLMs to guide the inference process as well as consolidate the results through forensic analysis, overcoming existing limitations in long-context visual reasoning. Experiments reveal that HolmesEye achieves a 10.8% improvement in average accuracy over state-of-the-art baselines and surpasses human-level performance by 15.0% in predicting abstract attributes. This work highlights the urgency of addressing privacy risks in image-based profiling and offers both a new dataset and an advanced framework to guide future research in this area.
JieHua Paintings Style Feature Extracting Model using Stable Diffusion with ControlNet
Aug 21, 2024


This study proposes a novel approach to extract stylistic features of Jiehua: the utilization of the Fine-tuned Stable Diffusion Model with ControlNet (FSDMC) to refine depiction techniques from artists' Jiehua. The training data for FSDMC is based on the opensource Jiehua artist's work collected from the Internet, which were subsequently manually constructed in the format of (Original Image, Canny Edge Features, Text Prompt). By employing the optimal hyperparameters identified in this paper, it was observed FSDMC outperforms CycleGAN, another mainstream style transfer model. FSDMC achieves FID of 3.27 on the dataset and also surpasses CycleGAN in terms of expert evaluation. This not only demonstrates the model's high effectiveness in extracting Jiehua's style features, but also preserves the original pre-trained semantic information. The findings of this study suggest that the application of FSDMC with appropriate hyperparameters can enhance the efficacy of the Stable Diffusion Model in the field of traditional art style migration tasks, particularly within the context of Jiehua.