 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Agile and Cooperative LEO Satellite Beam-Hopping Networks: Paradigms, Challenges, and Opportunities
May 30, 2026Low-Earth orbit (LEO) satellite beam-hopping (BH) technology is emerging as a promising approach to meet the ever-increasing global connectivity demands, enabling agile, on-demand coverage. LEO satellite BH can address the spatio-temporal non-uniformity of ground user traffic by dynamically allocating capacity and optimizing network performance. Cooperative multi-satellite BH enables joint transmission and interference avoidance to improve received signal quality. This article provides a comprehensive paradigm of BH, detailing its key dimensions, strategies, and architectures. Through exploration of key challenges, including beam pattern design, on-demand scheduling, and interference management, this paper identifies the potential applications of BH, ranging from adaptive capacity allocation for hotspot areas, low-power Internet-of-Things (IoT), delay-sensitive services, to massive connectivity support. Furthermore, a system-level analysis is presented, including key metrics, models of inter-beam and inter-satellite interference, and cooperative joint transmission, and a case study is provided to demonstrate the performance benefits of BH with cooperative transmission. Several promising future research directions are discussed to guide the future development of LEO satellite BH networks.
Structure-Grounded Knowledge Retrieval via Code Dependencies for Multi-Step Data Reasoning
Apr 12, 2026Selecting the right knowledge is critical when using large language models (LLMs) to solve domain-specific data analysis tasks. However, most retrieval-augmented approaches rely primarily on lexical or embedding similarity, which is often a weak proxy for the task-critical knowledge needed for multi-step reasoning. In many such tasks, the relevant knowledge is not merely textually related to the query, but is instead grounded in executable code and the dependency structure through which computations are carried out. To address this mismatch, we propose SGKR (Structure-Grounded Knowledge Retrieval), a retrieval framework that organizes domain knowledge with a graph induced by function-call dependencies. Given a question, SGKR extracts semantic input and output tags, identifies dependency paths connecting them, and constructs a task-relevant subgraph. The associated knowledge and corresponding function implementations are then assembled as a structured context for LLM-based code generation. Experiments on multi-step data analysis benchmarks show that SGKR consistently improves solution correctness over no-retrieval and similarity-based retrieval baselines for both vanilla LLMs and coding agents.
OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
Apr 06, 2026World models have garnered significant attention as a promising research direction in artificial intelligence, yet a clear and unified definition remains lacking. In this paper, we introduce OpenWorldLib, a comprehensive and standardized inference framework for Advanced World Models. Drawing on the evolution of world models, we propose a clear definition: a world model is a model or framework centered on perception, equipped with interaction and long-term memory capabilities, for understanding and predicting the complex world. We further systematically categorize the essential capabilities of world models. Based on this definition, OpenWorldLib integrates models across different tasks within a unified framework, enabling efficient reuse and collaborative inference. Finally, we present additional reflections and analyses on potential future directions for world model research. Code link: https://github.com/OpenDCAI/OpenWorldLib
Silo-Bench: A Scalable Environment for Evaluating Distributed Coordination in Multi-Agent LLM Systems
Mar 01, 2026Large language models are increasingly deployed in multi-agent systems to overcome context limitations by distributing information across agents. Yet whether agents can reliably compute with distributed information -- rather than merely exchange it -- remains an open question. We introduce Silo-Bench, a role-agnostic benchmark of 30 algorithmic tasks across three communication complexity levels, evaluating 54 configurations over 1,620 experiments. Our experiments expose a fundamental Communication-Reasoning Gap: agents spontaneously form task-appropriate coordination topologies and exchange information actively, yet systematically fail to synthesize distributed state into correct answers. The failure is localized to the reasoning-integration stage -- agents often acquire sufficient information but cannot integrate it. This coordination overhead compounds with scale, eventually eliminating parallelization gains entirely. These findings demonstrate that naively scaling agent count cannot circumvent context limitations, and Silo-Bench provides a foundation for tracking progress toward genuinely collaborative multi-agent systems.
Research on World Models Is Not Merely Injecting World Knowledge into Specific Tasks
Feb 02, 2026World models have emerged as a critical frontier in AI research, aiming to enhance large models by infusing them with physical dynamics and world knowledge. The core objective is to enable agents to understand, predict, and interact with complex environments. However, current research landscape remains fragmented, with approaches predominantly focused on injecting world knowledge into isolated tasks, such as visual prediction, 3D estimation, or symbol grounding, rather than establishing a unified definition or framework. While these task-specific integrations yield performance gains, they often lack the systematic coherence required for holistic world understanding. In this paper, we analyze the limitations of such fragmented approaches and propose a unified design specification for world models. We suggest that a robust world model should not be a loose collection of capabilities but a normative framework that integrally incorporates interaction, perception, symbolic reasoning, and spatial representation. This work aims to provide a structured perspective to guide future research toward more general, robust, and principled models of the world.
Backdoor Attacks on Prompt-Driven Video Segmentation Foundation Models
Dec 26, 2025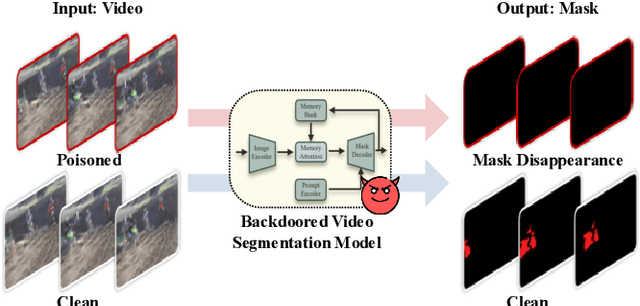
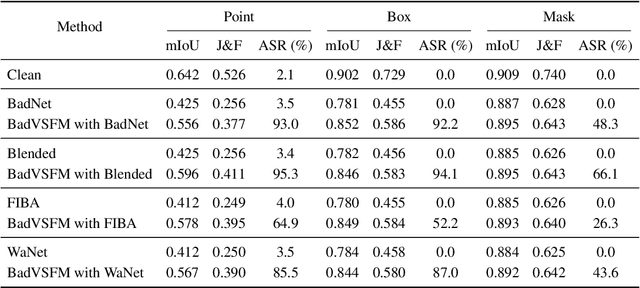
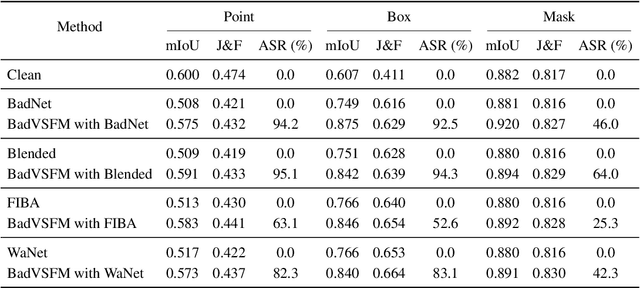
Prompt-driven Video Segmentation Foundation Models (VSFMs) such as SAM2 are increasingly deployed in applications like autonomous driving and digital pathology, raising concerns about backdoor threats. Surprisingly, we find that directly transferring classic backdoor attacks (e.g., BadNet) to VSFMs is almost ineffective, with ASR below 5\%. To understand this, we study encoder gradients and attention maps and observe that conventional training keeps gradients for clean and triggered samples largely aligned, while attention still focuses on the true object, preventing the encoder from learning a distinct trigger-related representation. To address this challenge, we propose BadVSFM, the first backdoor framework tailored to prompt-driven VSFMs. BadVSFM uses a two-stage strategy: (1) steer the image encoder so triggered frames map to a designated target embedding while clean frames remain aligned with a clean reference encoder; (2) train the mask decoder so that, across prompt types, triggered frame-prompt pairs produce a shared target mask, while clean outputs stay close to a reference decoder. Extensive experiments on two datasets and five VSFMs show that BadVSFM achieves strong, controllable backdoor effects under diverse triggers and prompts while preserving clean segmentation quality. Ablations over losses, stages, targets, trigger settings, and poisoning rates demonstrate robustness to reasonable hyperparameter changes and confirm the necessity of the two-stage design. Finally, gradient-conflict analysis and attention visualizations show that BadVSFM separates triggered and clean representations and shifts attention to trigger regions, while four representative defenses remain largely ineffective, revealing an underexplored vulnerability in current VSFMs.
VABench: A Comprehensive Benchmark for Audio-Video Generation
Dec 10, 2025Recent advances in video generation have been remarkable, enabling models to produce visually compelling videos with synchronized audio. While existing video generation benchmarks provide comprehensive metrics for visual quality, they lack convincing evaluations for audio-video generation, especially for models aiming to generate synchronized audio-video outputs. To address this gap, we introduce VABench, a comprehensive and multi-dimensional benchmark framework designed to systematically evaluate the capabilities of synchronous audio-video generation. VABench encompasses three primary task types: text-to-audio-video (T2AV), image-to-audio-video (I2AV), and stereo audio-video generation. It further establishes two major evaluation modules covering 15 dimensions. These dimensions specifically assess pairwise similarities (text-video, text-audio, video-audio), audio-video synchronization, lip-speech consistency, and carefully curated audio and video question-answering (QA) pairs, among others. Furthermore, VABench covers seven major content categories: animals, human sounds, music, environmental sounds, synchronous physical sounds, complex scenes, and virtual worlds. We provide a systematic analysis and visualization of the evaluation results, aiming to establish a new standard for assessing video generation models with synchronous audio capabilities and to promote the comprehensive advancement of the field.
ZPD-SCA: Unveiling the Blind Spots of LLMs in Assessing Students' Cognitive Abilities
Aug 20, 2025


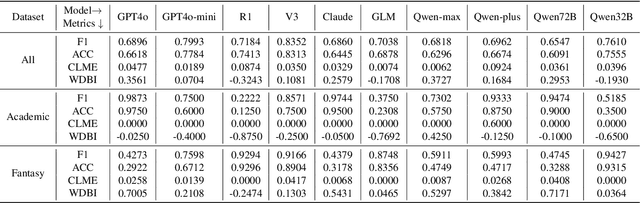
Large language models (LLMs) have demonstrated potential in educational applications, yet their capacity to accurately assess the cognitive alignment of reading materials with students' developmental stages remains insufficiently explored. This gap is particularly critical given the foundational educational principle of the Zone of Proximal Development (ZPD), which emphasizes the need to match learning resources with Students' Cognitive Abilities (SCA). Despite the importance of this alignment, there is a notable absence of comprehensive studies investigating LLMs' ability to evaluate reading comprehension difficulty across different student age groups, especially in the context of Chinese language education. To fill this gap, we introduce ZPD-SCA, a novel benchmark specifically designed to assess stage-level Chinese reading comprehension difficulty. The benchmark is annotated by 60 Special Grade teachers, a group that represents the top 0.15% of all in-service teachers nationwide. Experimental results reveal that LLMs perform poorly in zero-shot learning scenarios, with Qwen-max and GLM even falling below the probability of random guessing. When provided with in-context examples, LLMs performance improves substantially, with some models achieving nearly double the accuracy of their zero-shot baselines. These results reveal that LLMs possess emerging abilities to assess reading difficulty, while also exposing limitations in their current training for educationally aligned judgment. Notably, even the best-performing models display systematic directional biases, suggesting difficulties in accurately aligning material difficulty with SCA. Furthermore, significant variations in model performance across different genres underscore the complexity of task. We envision that ZPD-SCA can provide a foundation for evaluating and improving LLMs in cognitively aligned educational applications.
Evaluation Hallucination in Multi-Round Incomplete Information Lateral-Driven Reasoning Tasks
May 28, 2025


Multi-round incomplete information tasks are crucial for evaluating the lateral thinking capabilities of large language models (LLMs). Currently, research primarily relies on multiple benchmarks and automated evaluation metrics to assess these abilities. However, our study reveals novel insights into the limitations of existing methods, as they often yield misleading results that fail to uncover key issues, such as shortcut-taking behaviors, rigid patterns, and premature task termination. These issues obscure the true reasoning capabilities of LLMs and undermine the reliability of evaluations. To address these limitations, we propose a refined set of evaluation standards, including inspection of reasoning paths, diversified assessment metrics, and comparative analyses with human performance.
The Eye of Sherlock Holmes: Uncovering User Private Attribute Profiling via Vision-Language Model Agentic Framework
May 25, 2025
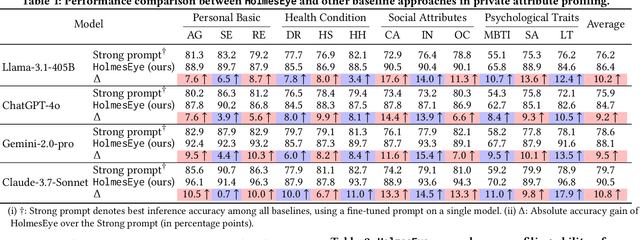
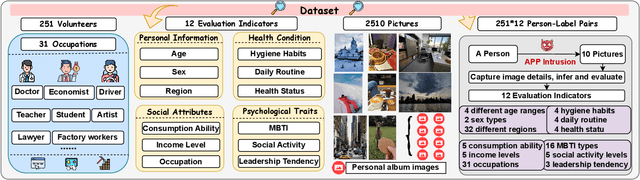

Our research reveals a new privacy risk associated with the vision-language model (VLM) agentic framework: the ability to infer sensitive attributes (e.g., age and health information) and even abstract ones (e.g., personality and social traits) from a set of personal images, which we term "image private attribute profiling." This threat is particularly severe given that modern apps can easily access users' photo albums, and inference from image sets enables models to exploit inter-image relations for more sophisticated profiling. However, two main challenges hinder our understanding of how well VLMs can profile an individual from a few personal photos: (1) the lack of benchmark datasets with multi-image annotations for private attributes, and (2) the limited ability of current multimodal large language models (MLLMs) to infer abstract attributes from large image collections. In this work, we construct PAPI, the largest dataset for studying private attribute profiling in personal images, comprising 2,510 images from 251 individuals with 3,012 annotated privacy attributes. We also propose HolmesEye, a hybrid agentic framework that combines VLMs and LLMs to enhance privacy inference. HolmesEye uses VLMs to extract both intra-image and inter-image information and LLMs to guide the inference process as well as consolidate the results through forensic analysis, overcoming existing limitations in long-context visual reasoning. Experiments reveal that HolmesEye achieves a 10.8% improvement in average accuracy over state-of-the-art baselines and surpasses human-level performance by 15.0% in predicting abstract attributes. This work highlights the urgency of addressing privacy risks in image-based profiling and offers both a new dataset and an advanced framework to guide future research in this area.