 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACE: Mixture-of-Experts Accelerated Coordinate Encoding for Large-Scale Scene Localization and Rendering
Oct 16, 2025Efficient localization and high-quality rendering in large-scale scenes remain a significant challenge due to the computational cost involved. While Scene Coordinate Regression (SCR) methods perform well in small-scale localization, they are limited by the capacity of a single network when extended to large-scale scenes. To address these challenges, we propose the Mixed Expert-based Accelerated Coordinate Encoding method (MACE), which enables efficient localization and high-quality rendering in large-scale scenes. Inspired by the remarkable capabilities of MOE in large model domains, we introduce a gating network to implicitly classify and select sub-networks, ensuring that only a single sub-network is activated during each inference. Furtheremore, we present Auxiliary-Loss-Free Load Balancing(ALF-LB) strategy to enhance the localization accuracy on large-scale scene. Our framework provides a significant reduction in costs while maintaining higher precision, offering an efficient solution for large-scale scene applications. Additional experiments on the Cambridge test set demonstrate that our method achieves high-quality rendering results with merely 10 minutes of training.
A Wireless Collaborated Inference Acceleration Framework for Plant Disease Recognition
May 05, 2025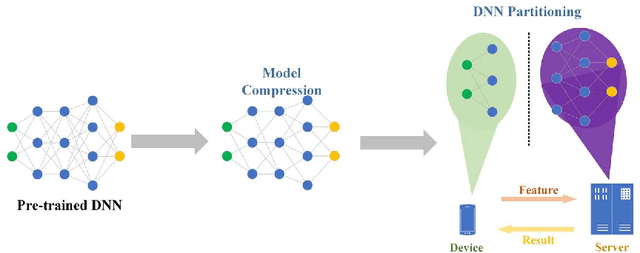

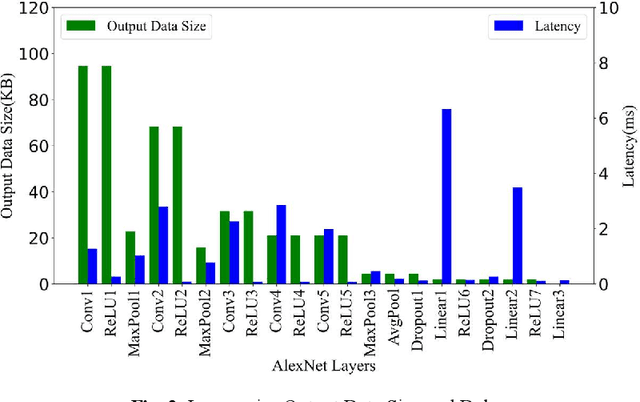
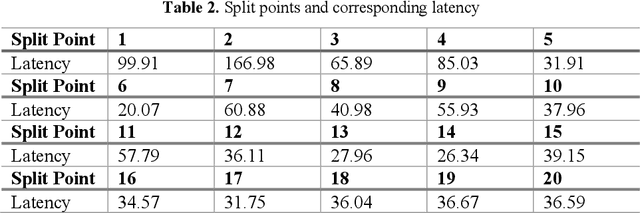
Plant disease is a critical factor affecting agricultural production. Traditional manual recognition methods face significant drawbacks, including low accuracy, high costs, and inefficiency. Deep learning techniques have demonstrated significant benefits in identifying plant diseases, but they still face challenges such as inference delays and high energy consumption. Deep learning algorithms are difficult to run on resource-limited embedded devices. Offloading these models to cloud servers is confronted with the restriction of communication bandwidth, and all of these factors will influence the inference's efficiency. We propose a collaborative inference framework for recognizing plant diseases between edge devices and cloud servers to enhance inference speed. The DNN model for plant disease recognition is pruned through deep reinforcement learning to improve the inference speed and reduce energy consumption. Then the optimal split point is determined by a greedy strategy to achieve the best collaborated inference acceleration. Finally, the system for collaborative inference acceleration in plant disease recognition has been implemented using Gradio to facilitate friendly human-machine interaction. Experiments indicate that the proposed collaborative inference framework significantly increases inference speed while maintaining acceptable recognition accuracy, offering a novel solution for rapidly diagnosing and preventing plant diseases.
Mapping at First Sense: A Lightweight Neural Network-Based Indoor Structures Prediction Method for Robot Autonomous Exploration
Apr 05, 2025Autonomous exploration in unknown environments is a critical challenge in robotics, particularly for applications such as indoor navigation, search and rescue, and service robotics. Traditional exploration strategies, such as frontier-based methods, often struggle to efficiently utilize prior knowledge of structural regularities in indoor spaces. To address this limitation, we propose Mapping at First Sense, a lightweight neural network-based approach that predicts unobserved areas in local maps, thereby enhancing exploration efficiency. The core of our method, SenseMapNet, integrates convolutional and transformerbased architectures to infer occluded regions while maintaining computational efficiency for real-time deployment on resourceconstrained robots. Additionally, we introduce SenseMapDataset, a curated dataset constructed from KTH and HouseExpo environments, which facilitates training and evaluation of neural models for indoor exploration. Experimental results demonstrate that SenseMapNet achieves an SSIM (structural similarity) of 0.78, LPIPS (perceptual quality) of 0.68, and an FID (feature distribution alignment) of 239.79, outperforming conventional methods in map reconstruction quality. Compared to traditional frontier-based exploration, our method reduces exploration time by 46.5% (from 2335.56s to 1248.68s) while maintaining a high coverage rate (88%) and achieving a reconstruction accuracy of 88%. The proposed method represents a promising step toward efficient, learning-driven robotic exploration in structured environments.
SenseExpo: Efficient Autonomous Exploration with Prediction Information from Lightweight Neural Networks
Mar 20, 2025This paper proposes SenseExpo, an efficient autonomous exploration framework based on a lightweight prediction network, which addresses the limitations of traditional methods in computational overhead and environmental generalization. By integrating Generative Adversarial Networks (GANs), Transformer, and Fast Fourier Convolution (FFC), we designed a lightweight prediction model with merely 709k parameters. Our smallest model achieves better performance on the KTH dataset than U-net (24.5M) and LaMa (51M), delivering PSNR 9.026 and SSIM 0.718, particularly representing a 38.7% PSNR improvement over the 51M-parameter LaMa model. Cross-domain testing demonstrates its strong generalization capability, with an FID score of 161.55 on the HouseExpo dataset, significantly outperforming comparable methods. Regarding exploration efficiency, on the KTH dataset,SenseExpo demonstrates approximately a 67.9% time reduction in exploration time compared to MapEx. On the MRPB 1.0 dataset, SenseExpo achieves 77.1% time reduction roughly compared to MapEx. Deployed as a plug-and-play ROS node, the framework seamlessly integrates with existing navigation systems, providing an efficient solution for resource-constrained devices.
"Pass the butter": A study on desktop-classic multitasking robotic arm based on advanced YOLOv7 and BERT
May 27, 2024


In recent years, various intelligent autonomous robots have begun to appear in daily life and production. Desktop-level robots are characterized by their flexible deployment, rapid response, and suitability for light workload environments. In order to meet the current societal demand for service robot technology, this study proposes using a miniaturized desktop-level robot (by ROS) as a carrier, locally deploying a natural language model (NLP-BERT), and integrating visual recognition (CV-YOLO) and speech recognition technology (ASR-Whisper) as inputs to achieve autonomous decision-making and rational action by the desktop robot. Three comprehensive experiments were designed to validate the robotic arm, and the results demonstrate excellent performance using this approach across all three experiments. In Task 1, the execution rates for speech recognition and action performance were 92.6% and 84.3%, respectively. In Task 2, the highest execution rates under the given conditions reached 92.1% and 84.6%, while in Task 3, the highest execution rates were 95.2% and 80.8%, respectively. Therefore, it can be concluded that the proposed solution integrating ASR, NLP, and other technologies on edge devices is feasible and provides a technical and engineering foundation for realizing multimodal desktop-level robots.