 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyMoERec: Hybrid Mixture-of-Experts for Sequential Recommendation
Nov 09, 2025We propose HyMoERec, a novel sequential recommendation framework that addresses the limitations of uniform Position-wise Feed-Forward Networks in existing models. Current approaches treat all user interactions and items equally, overlooking the heterogeneity in user behavior patterns and diversity in item complexity. HyMoERec initially introduces a hybrid mixture-of-experts architecture that combines shared and specialized expert branches with an adaptive expert fusion mechanism for the sequential recommendation task. This design captures diverse reasoning for varied users and items while ensuring stable training. Experiments on MovieLens-1M and Beauty datasets demonstrate that HyMoERec consistently outperforms state-of-the-art baselines.
Mapping at First Sense: A Lightweight Neural Network-Based Indoor Structures Prediction Method for Robot Autonomous Exploration
Apr 05, 2025Autonomous exploration in unknown environments is a critical challenge in robotics, particularly for applications such as indoor navigation, search and rescue, and service robotics. Traditional exploration strategies, such as frontier-based methods, often struggle to efficiently utilize prior knowledge of structural regularities in indoor spaces. To address this limitation, we propose Mapping at First Sense, a lightweight neural network-based approach that predicts unobserved areas in local maps, thereby enhancing exploration efficiency. The core of our method, SenseMapNet, integrates convolutional and transformerbased architectures to infer occluded regions while maintaining computational efficiency for real-time deployment on resourceconstrained robots. Additionally, we introduce SenseMapDataset, a curated dataset constructed from KTH and HouseExpo environments, which facilitates training and evaluation of neural models for indoor exploration. Experimental results demonstrate that SenseMapNet achieves an SSIM (structural similarity) of 0.78, LPIPS (perceptual quality) of 0.68, and an FID (feature distribution alignment) of 239.79, outperforming conventional methods in map reconstruction quality. Compared to traditional frontier-based exploration, our method reduces exploration time by 46.5% (from 2335.56s to 1248.68s) while maintaining a high coverage rate (88%) and achieving a reconstruction accuracy of 88%. The proposed method represents a promising step toward efficient, learning-driven robotic exploration in structured environments.
Semantic Consistency Regularization with Large Language Models for Semi-supervised Sentiment Analysis
Jan 29, 2025
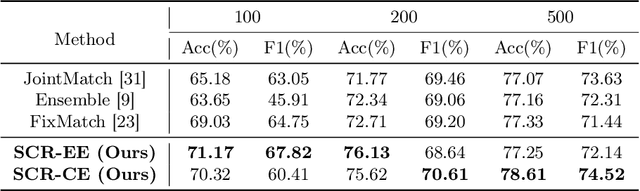


Accurate sentiment analysis of texts is crucial for a variety of applications, such as understanding customer feedback, monitoring market trends, and detecting public sentiment. However, manually annotating large sentiment corpora for supervised learning is labor-intensive and time-consuming. Therefore, it is essential and effective to develop a semi-supervised method for the sentiment analysis task. Although some methods have been proposed for semi-supervised text classification, they rely on the intrinsic information within the unlabeled data and the learning capability of the NLP model, which lack generalization ability to the sentiment analysis scenario and may prone to overfit. Inspired by the ability of pretrained Large Language Models (LLMs) in following instructions and generating coherent text, we propose a Semantic Consistency Regularization with Large Language Models (SCR) framework for semi-supervised sentiment analysis. We introduce two prompting strategies to semantically enhance unlabeled text using LLMs. The first is Entity-based Enhancement (SCR-EE), which involves extracting entities and numerical information, and querying the LLM to reconstruct the textual information. The second is Concept-based Enhancement (SCR-CE), which directly queries the LLM with the original sentence for semantic reconstruction. Subsequently, the LLM-augmented data is utilized for a consistency loss with confidence thresholding, which preserves high-quality agreement samples to provide additional supervision signals during training. Furthermore, to fully utilize the uncertain unlabeled data samples, we propose a class re-assembling strategy inspired by the class space shrinking theorem. Experiments show our method achieves remarkable performance over prior semi-supervised methods.