 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotiMem: Motion-Aware Approximate Memory for Energy-Efficient Neural Perception in Autonomous Vehicles
Mar 28, 2026High-resolution sensors are critical for robust autonomous perception but impose a severe memory wall on battery-constrained electric vehicles. In these systems, data movement energy often outweighs computation. Traditional image compression is ill-suited as it is semantically blind and optimizes for storage rather than bus switching activity. We propose MotiMem, a hardware-software co-designed interface. Exploiting temporal coherence,MotiMem uses lightweight 2D Motion Propagation to dynamically identify Regions of Interest (RoI). Complementing this, a Hybrid Sparsity-Aware Coding scheme leverages adaptive inversion and truncation to induce bitlevel sparsity. Extensive experiments across nuScenes, Waymo, and KITTI with 16 detection models demonstrate that MotiMem reduces memory-interface dynamic energy by approximately 43 percent while retaining approximately 93 percent of the object detection accuracy, establishing a new Pareto frontier significantly superior to standard codecs like JPEG and WebP.
A digital SRAM-based compute-in-memory macro for weight-stationary dynamic matrix multiplication in Transformer attention score computation
Nov 15, 2025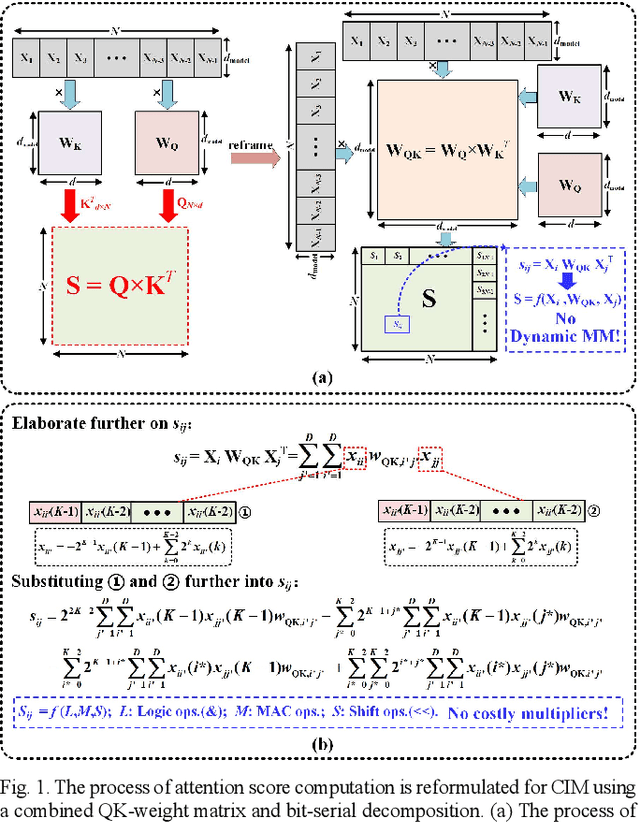
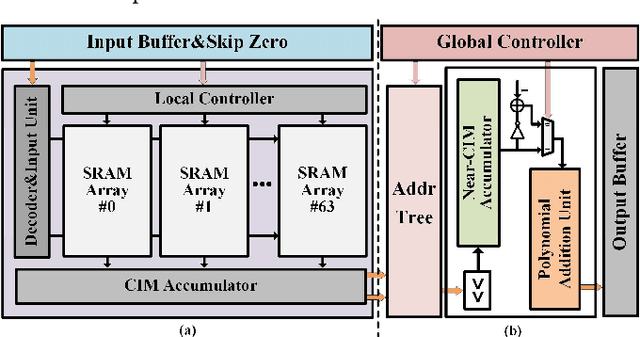


Compute-in-memory (CIM) techniques are widely employed in energy-efficient artificial intelligent (AI) processors. They alleviate power and latency bottlenecks caused by extensive data movements between compute and storage units. This work proposes a digital CIM macro to compute Transformer attention. To mitigate dynamic matrix multiplication that is unsuitable for the common weight-stationary CIM paradigm, we reformulate the attention score computation process based on a combined QK-weight matrix, so that inputs can be directly fed to CIM cells to obtain the score results. Moreover, the involved binomial matrix multiplication operation is decomposed into 4 groups of bit-serial shifting and additions, without costly physical multipliers in the CIM. We maximize the energy efficiency of the CIM circuit through zero-value bit-skipping, data-driven word line activation, read-write separate 6T cells and bit-alternating 14T/28T adders. The proposed CIM macro was implemented using a 65-nm process. It occupied only 0.35 mm2 area, and delivered a 42.27 GOPS peak performance with 1.24 mW power consumption at a 1.0 V power supply and a 100 MHz clock frequency, resulting in 34.1 TOPS/W energy efficiency and 120.77 GOPS/mm2 area efficiency. When compared to the CPU and GPU, our CIM macro is 25x and 13x more energy efficient on practical tasks, respectively. Compared with other Transformer-CIMs, our design exhibits at least 7x energy efficiency and at least 2x area efficiency improvements when scaled to the same technology node, showcasing its potential for edge-side intelligent applications.
Mapping at First Sense: A Lightweight Neural Network-Based Indoor Structures Prediction Method for Robot Autonomous Exploration
Apr 05, 2025Autonomous exploration in unknown environments is a critical challenge in robotics, particularly for applications such as indoor navigation, search and rescue, and service robotics. Traditional exploration strategies, such as frontier-based methods, often struggle to efficiently utilize prior knowledge of structural regularities in indoor spaces. To address this limitation, we propose Mapping at First Sense, a lightweight neural network-based approach that predicts unobserved areas in local maps, thereby enhancing exploration efficiency. The core of our method, SenseMapNet, integrates convolutional and transformerbased architectures to infer occluded regions while maintaining computational efficiency for real-time deployment on resourceconstrained robots. Additionally, we introduce SenseMapDataset, a curated dataset constructed from KTH and HouseExpo environments, which facilitates training and evaluation of neural models for indoor exploration. Experimental results demonstrate that SenseMapNet achieves an SSIM (structural similarity) of 0.78, LPIPS (perceptual quality) of 0.68, and an FID (feature distribution alignment) of 239.79, outperforming conventional methods in map reconstruction quality. Compared to traditional frontier-based exploration, our method reduces exploration time by 46.5% (from 2335.56s to 1248.68s) while maintaining a high coverage rate (88%) and achieving a reconstruction accuracy of 88%. The proposed method represents a promising step toward efficient, learning-driven robotic exploration in structured environments.
SenseExpo: Efficient Autonomous Exploration with Prediction Information from Lightweight Neural Networks
Mar 20, 2025This paper proposes SenseExpo, an efficient autonomous exploration framework based on a lightweight prediction network, which addresses the limitations of traditional methods in computational overhead and environmental generalization. By integrating Generative Adversarial Networks (GANs), Transformer, and Fast Fourier Convolution (FFC), we designed a lightweight prediction model with merely 709k parameters. Our smallest model achieves better performance on the KTH dataset than U-net (24.5M) and LaMa (51M), delivering PSNR 9.026 and SSIM 0.718, particularly representing a 38.7% PSNR improvement over the 51M-parameter LaMa model. Cross-domain testing demonstrates its strong generalization capability, with an FID score of 161.55 on the HouseExpo dataset, significantly outperforming comparable methods. Regarding exploration efficiency, on the KTH dataset,SenseExpo demonstrates approximately a 67.9% time reduction in exploration time compared to MapEx. On the MRPB 1.0 dataset, SenseExpo achieves 77.1% time reduction roughly compared to MapEx. Deployed as a plug-and-play ROS node, the framework seamlessly integrates with existing navigation systems, providing an efficient solution for resource-constrained devices.
RaP-Net: A Region-wise and Point-wise Weighting Network to Extract Robust Keypoints for Indoor Localization
Dec 01, 2020

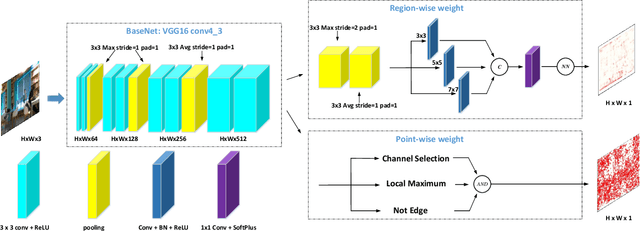
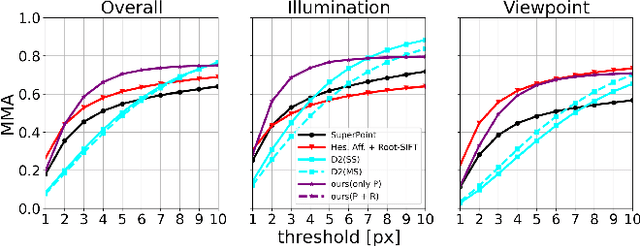
Image keypoint extraction is an important step for visual localization. The localization in indoor environment is challenging for that there may be many unreliable features on dynamic or repetitive objects. Such kind of reliability cannot be well learned by existing Convolutional Neural Network (CNN) based feature extractors. We propose a novel network, RaP-Net, which explicitly addresses feature invariability with a region-wise predictor, and combines it with a point-wise predictor to select reliable keypoints in an image. We also build a new dataset, OpenLORIS-Location, to train this network. The dataset contains 1553 indoor images with location labels. There are various scene changes between images on the same location, which can help a network to learn the invariability in typical indoor scenes. Experimental results show that the proposed RaP-Net trained with the OpenLORIS-Location dataset significantly outperforms existing CNN-based keypoint extraction algorithms for indoor localization. The code and data are available at https://github.com/ivipsourcecode/RaP-Net.
DXSLAM: A Robust and Efficient Visual SLAM System with Deep Features
Aug 12, 2020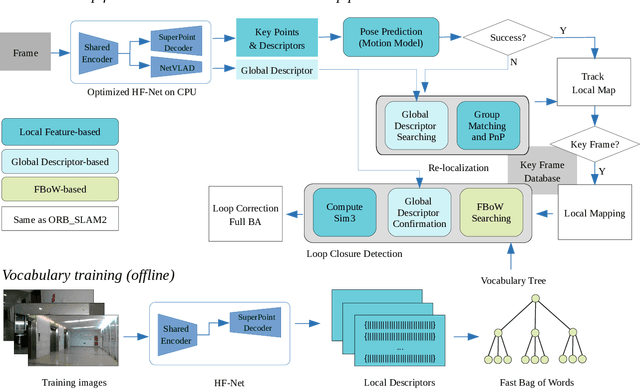
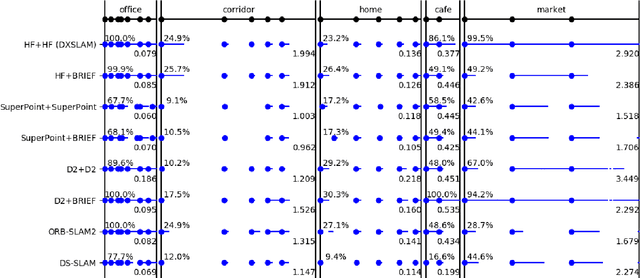

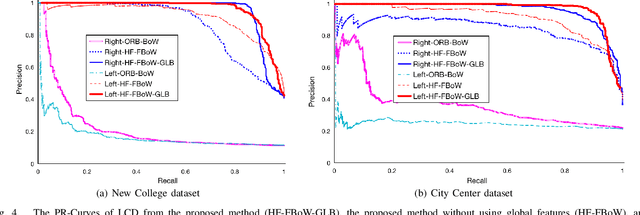
A robust and efficient Simultaneous Localization and Mapping (SLAM) system is essential for robot autonomy. For visual SLAM algorithms, though the theoretical framework has been well established for most aspects, feature extraction and association is still empirically designed in most cases, and can be vulnerable in complex environments. This paper shows that feature extraction with deep convolutional neural networks (CNNs) can be seamlessly incorporated into a modern SLAM framework. The proposed SLAM system utilizes a state-of-the-art CNN to detect keypoints in each image frame, and to give not only keypoint descriptors, but also a global descriptor of the whole image. These local and global features are then used by different SLAM modules, resulting in much more robustness against environmental changes and viewpoint changes compared with using hand-crafted features. We also train a visual vocabulary of local features with a Bag of Words (BoW) method. Based on the local features, global features, and the vocabulary, a highly reliable loop closure detection method is built. Experimental results show that all the proposed modules significantly outperforms the baseline, and the full system achieves much lower trajectory errors and much higher correct rates on all evaluated data. Furthermore, by optimizing the CNN with Intel OpenVINO toolkit and utilizing the Fast BoW library, the system benefits greatly from the SIMD (single-instruction-multiple-data) techniques in modern CPUs. The full system can run in real-time without any GPU or other accelerators. The code is public at https://github.com/ivipsourcecode/dxslam.
OpenLORIS-Object: A Dataset and Benchmark towards Lifelong Object Recognition
Nov 15, 2019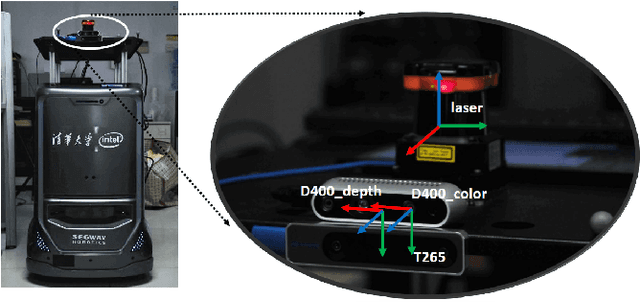


The recent breakthroughs in computer vision have benefited from the availability of large representative datasets (e.g. ImageNet and COCO) for training. Yet, robotic vision poses unique challenges for applying visual algorithms developed from these standard computer vision datasets due to their implicit assumption over non-varying distributions for a fixed set of tasks. Fully retraining models each time a new task becomes available is infeasible due to computational, storage and sometimes privacy issues, while na\"{i}ve incremental strategies have been shown to suffer from catastrophic forgetting. It is crucial for the robots to operate continuously under open-set and detrimental conditions with adaptive visual perceptual systems, where lifelong learning is a fundamental capability. However, very few datasets and benchmarks are available to evaluate and compare emerging techniques. To fill this gap, we provide a new lifelong robotic vision dataset ("OpenLORIS-Object") collected via RGB-D cameras mounted on mobile robots. The dataset embeds the challenges faced by a robot in the real-life application and provides new benchmarks for validating lifelong object recognition algorithms. Moreover, we have provided a testbed of $9$ state-of-the-art lifelong learning algorithms. Each of them involves $48$ tasks with $4$ evaluation metrics over the OpenLORIS-Object dataset. The results demonstrate that the object recognition task in the ever-changing difficulty environments is far from being solved and the bottlenecks are at the forward/backward transfer designs. Our dataset and benchmark are publicly available at \href{https://lifelong-robotic-vision.github.io/dataset/Data_Object-Recognition.html}{\underline{this url}}.
Are We Ready for Service Robots? The OpenLORIS-Scene Datasets for Lifelong SLAM
Nov 13, 2019
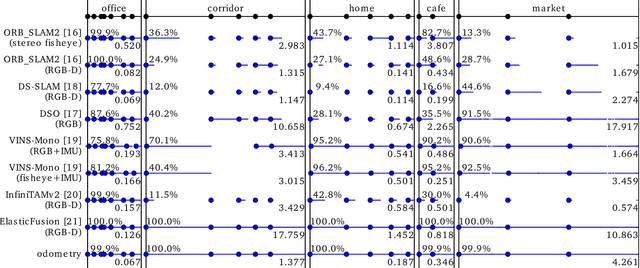
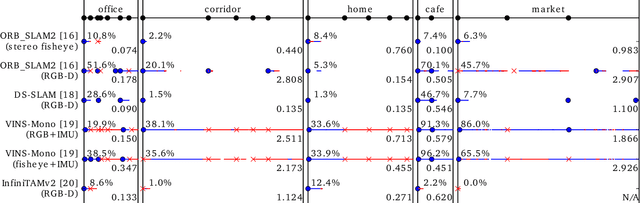
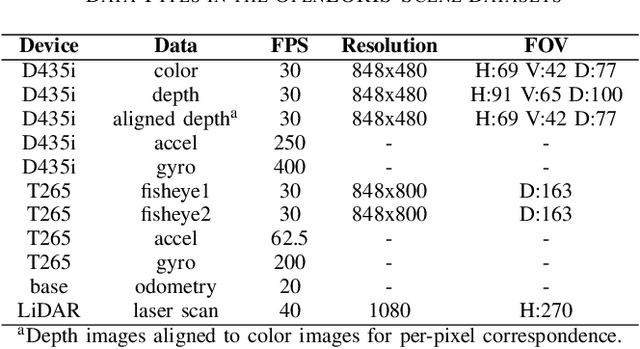
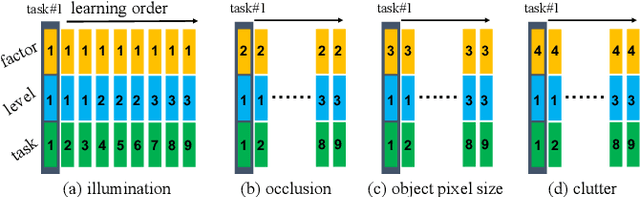
Service robots should be able to operate autonomously in dynamic and daily changing environments over an extended period of time. While Simultaneous Localization And Mapping (SLAM) is one of the most fundamental problems for robotic autonomy, most existing SLAM works are evaluated with data sequences that are recorded in a short period of time. In real-world deployment, there can be out-of-sight scene changes caused by both natural factors and human activities. For example, in home scenarios, most objects may be movable, replaceable or deformable, and the visual features of the same place may be significantly different in some successive days. Such out-of-sight dynamics pose great challenges to the robustness of pose estimation, and hence a robot's long-term deployment and operation. To differentiate the forementioned problem from the conventional works which are usually evaluated in a static setting in a single run, the term lifelong SLAM is used here to address SLAM problems in an ever-changing environment over a long period of time. To accelerate lifelong SLAM research, we release the OpenLORIS-Scene datasets. The data are collected in real-world indoor scenes, for multiple times in each place to include scene changes in real life. We also design benchmarking metrics for lifelong SLAM, with which the robustness and accuracy of pose estimation are evaluated separately. The datasets and benchmark are available online at https://lifelong-robotic-vision.github.io/dataset/scene.
Interactive Hand Pose Estimation: Boosting accuracy in localizing extended finger joints
Jul 25, 2018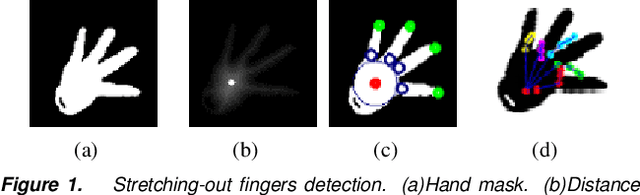
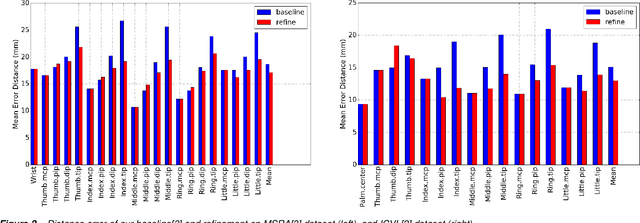
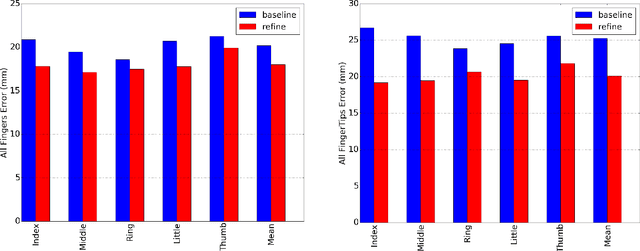
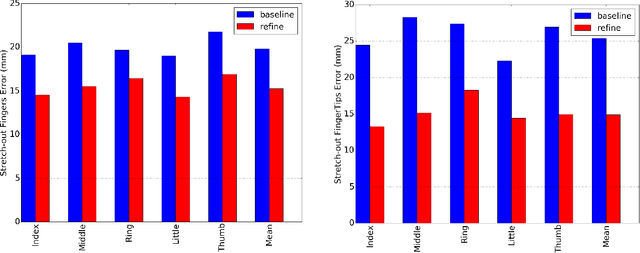
Accurate 3D hand pose estimation plays an important role in Human Machine Interaction (HMI). In the reality of HMI, joints in fingers stretching out, especially corresponding fingertips, are much more important than other joints. We propose a novel method to refine stretching-out finger joint locations after obtaining rough hand pose estimation. It first detects which fingers are stretching out, then neighbor pixels of certain joint vote for its new location based on random forests. The algorithm is tested on two public datasets: MSRA15 and ICVL. After the refinement stage of stretching-out fingers, errors of predicted HMI finger joint locations are significantly reduced. Mean error of all fingertips reduces around 5mm (relatively more than 20%). Stretching-out fingertip locations are even more precise, which in MSRA15 reduces 10.51mm (relatively 41.4%).
* Original publication available on https://doi.org/10.2352/ISSN.2470-1173.2018.2.VIPC-251
Region Ensemble Network: Improving Convolutional Network for Hand Pose Estimation
May 09, 2017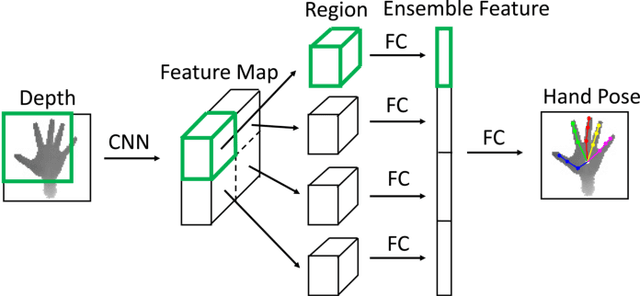
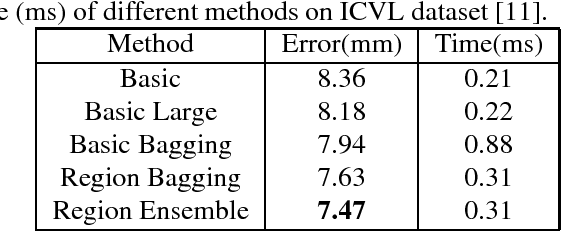
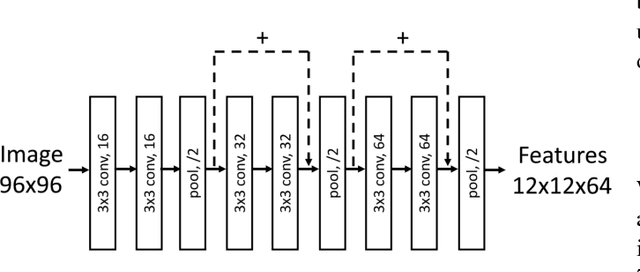

Hand pose estimation from monocular depth images is an important and challenging problem for human-computer interaction. Recently deep convolutional networks (ConvNet) with sophisticated design have been employed to address it, but the improvement over traditional methods is not so apparent. To promote the performance of directly 3D coordinate regression, we propose a tree-structured Region Ensemble Network (REN), which partitions the convolution outputs into regions and integrates the results from multiple regressors on each regions. Compared with multi-model ensemble, our model is completely end-to-end training. The experimental results demonstrate that our approach achieves the best performance among state-of-the-arts on two public datasets.