 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion Ensemble Network: Improving Convolutional Network for Hand Pose Estimation
Paper and Code
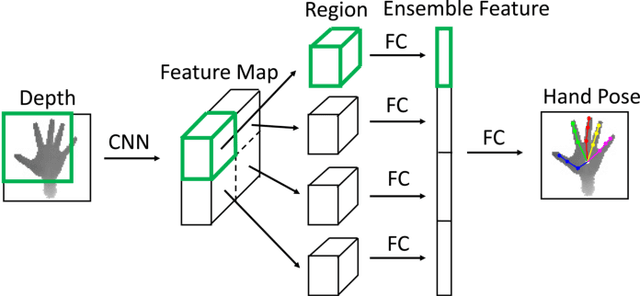
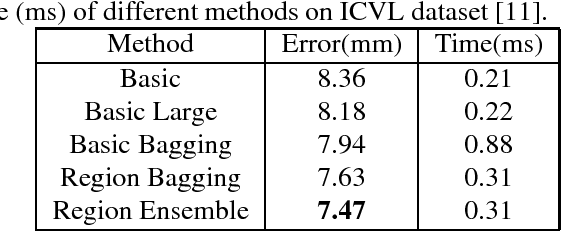
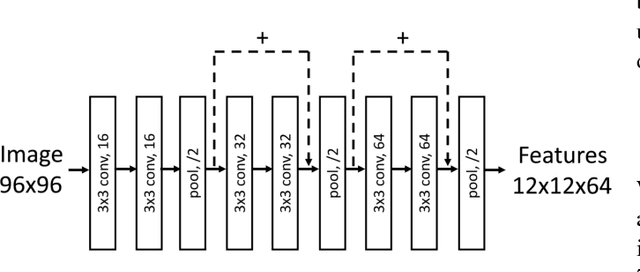

Hand pose estimation from monocular depth images is an important and challenging problem for human-computer interaction. Recently deep convolutional networks (ConvNet) with sophisticated design have been employed to address it, but the improvement over traditional methods is not so apparent. To promote the performance of directly 3D coordinate regression, we propose a tree-structured Region Ensemble Network (REN), which partitions the convolution outputs into regions and integrates the results from multiple regressors on each regions. Compared with multi-model ensemble, our model is completely end-to-end training. The experimental results demonstrate that our approach achieves the best performance among state-of-the-arts on two public datasets.