 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRe-ECG: Advancing Self-Supervised Representation Learning for 12-Lead ECG via Contrastive and Reconstructive Synergy
Apr 13, 2026Accurate interpretation of electrocardiogram (ECG) remains challenging due to the scarcity of labeled data and the high cost of expert annotation. Self-supervised learning (SSL) offers a promising solution by enabling models to learn expressive representations from unlabeled signals. Existing ECG SSL methods typically rely on either contrastive learning or reconstructive learning. However, each approach in isolation provides limited supervisory signals and suffers from additional limitations, including non-physiological distortions introduced by naive augmentations and trivial correlations across multiple leads that models may exploit as shortcuts. In this work, we propose CoRe-ECG, a unified contrastive and reconstructive pretraining paradigm that establishes a synergistic interaction between global semantic modeling and local structural learning. CoRe-ECG aligns global representations during reconstruction, enabling instance-level discriminative signals to guide local waveform recovery. To further enhance pretraining, we introduce Frequency Dynamic Augmentation (FDA) to adaptively perturb ECG signals based on their frequency-domain importance, and Spatio-Temporal Dual Masking (STDM) to break linear dependencies across leads, increasing the difficulty of reconstructive tasks. Our method achieves state-of-the-art performance across multiple downstream ECG datasets. Ablation studies further demonstrate the necessity and complementarity of each component. This approach provides a robust and physiologically meaningful representation learning framework for ECG analysis.
WaterSplat-SLAM: Photorealistic Monocular SLAM in Underwater Environment
Apr 06, 2026Underwater monocular SLAM is a challenging problem with applications from autonomous underwater vehicles to marine archaeology. However, existing underwater SLAM methods struggle to produce maps with high-fidelity rendering. In this paper, we propose WaterSplat-SLAM, a novel monocular underwater SLAM system that achieves robust pose estimation and photorealistic dense mapping. Specifically, we couple semantic medium filtering into two-view 3D reconstruction prior to enable underwater-adapted camera tracking and depth estimation. Furthermore, we present a semantic-guided rendering and adaptive map management strategy with an online medium-aware Gaussian map, modeling underwater environment in a photorealistic and compact manner. Experiments on multiple underwater datasets demonstrate that WaterSplat-SLAM achieves robust camera tracking and high-fidelity rendering in underwater environments.
MG-Grasp: Metric-Scale Geometric 6-DoF Grasping Framework with Sparse RGB Observations
Mar 17, 2026Single-view RGB-D grasp detection remains a com- mon choice in 6-DoF robotic grasping systems, which typically requires a depth sensor. While RGB-only 6-DoF grasp methods has been studied recently, their inaccurate geometric repre- sentation is not directly suitable for physically reliable robotic manipulation, thereby hindering reliable grasp generation. To address these limitations, we propose MG-Grasp, a novel depth- free 6-DoF grasping framework that achieves high-quality object grasping. Leveraging two-view 3D foundation model with camera intrinsic/extrinsic, our method reconstructs metric- scale and multi-view consistent dense point clouds from sparse RGB images and generates stable 6-DoF grasp. Experiments on GraspNet-1Billion dataset and real world demonstrate that MG-Grasp achieves state-of-the-art (SOTA) grasp performance among RGB-based 6-DoF grasping methods.
PRISM: Probabilistic and Robust Inverse Solver with Measurement-Conditioned Diffusion Prior for Blind Inverse Problems
Sep 19, 2025Diffusion models are now commonly used to solve inverse problems in computational imaging. However, most diffusion-based inverse solvers require complete knowledge of the forward operator to be used. In this work, we introduce a novel probabilistic and robust inverse solver with measurement-conditioned diffusion prior (PRISM) to effectively address blind inverse problems. PRISM offers a technical advancement over current methods by incorporating a powerful measurement-conditioned diffusion model into a theoretically principled posterior sampling scheme. Experiments on blind image deblurring validate the effectiveness of the proposed method, demonstrating the superior performance of PRISM over state-of-the-art baselines in both image and blur kernel recovery.
VISTA: Unsupervised 2D Temporal Dependency Representations for Time Series Anomaly Detection
Apr 03, 2025Time Series Anomaly Detection (TSAD) is essential for uncovering rare and potentially harmful events in unlabeled time series data. Existing methods are highly dependent on clean, high-quality inputs, making them susceptible to noise and real-world imperfections. Additionally, intricate temporal relationships in time series data are often inadequately captured in traditional 1D representations, leading to suboptimal modeling of dependencies. We introduce VISTA, a training-free, unsupervised TSAD algorithm designed to overcome these challenges. VISTA features three core modules: 1) Time Series Decomposition using Seasonal and Trend Decomposition via Loess (STL) to decompose noisy time series into trend, seasonal, and residual components; 2) Temporal Self-Attention, which transforms 1D time series into 2D temporal correlation matrices for richer dependency modeling and anomaly detection; and 3) Multivariate Temporal Aggregation, which uses a pretrained feature extractor to integrate cross-variable information into a unified, memory-efficient representation. VISTA's training-free approach enables rapid deployment and easy hyperparameter tuning, making it suitable for industrial applications. It achieves state-of-the-art performance on five multivariate TSAD benchmarks.
Efficient End-to-End 6-Dof Grasp Detection Framework for Edge Devices with Hierarchical Heatmaps and Feature Propagation
Oct 30, 2024



6-DoF grasp detection is critically important for the advancement of intelligent embodied systems, as it provides feasible robot poses for object grasping. Various methods have been proposed to detect 6-DoF grasps through the extraction of 3D geometric features from RGBD or point cloud data. However, most of these approaches encounter challenges during real robot deployment due to their significant computational demands, which can be particularly problematic for mobile robot platforms, especially those reliant on edge computing devices. This paper presents an Efficient End-to-End Grasp Detection Network (E3GNet) for 6-DoF grasp detection utilizing hierarchical heatmap representations. E3GNet effectively identifies high-quality and diverse grasps in cluttered real-world environments. Benefiting from our end-to-end methodology and efficient network design, our approach surpasses previous methods in model inference efficiency and achieves real-time 6-Dof grasp detection on edge devices. Furthermore, real-world experiments validate the effectiveness of our method, achieving a satisfactory 94% object grasping success rate.
Diffusion-Based Depth Inpainting for Transparent and Reflective Objects
Oct 11, 2024



Transparent and reflective objects, which are common in our everyday lives, present a significant challenge to 3D imaging techniques due to their unique visual and optical properties. Faced with these types of objects, RGB-D cameras fail to capture the real depth value with their accurate spatial information. To address this issue, we propose DITR, a diffusion-based Depth Inpainting framework specifically designed for Transparent and Reflective objects. This network consists of two stages, including a Region Proposal stage and a Depth Inpainting stage. DITR dynamically analyzes the optical and geometric depth loss and inpaints them automatically. Furthermore, comprehensive experimental results demonstrate that DITR is highly effective in depth inpainting tasks of transparent and reflective objects with robust adaptability.
GAP-RL: Grasps As Points for RL Towards Dynamic Object Grasping
Oct 04, 2024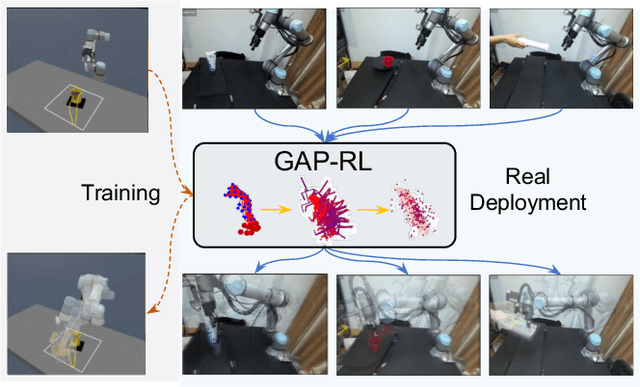
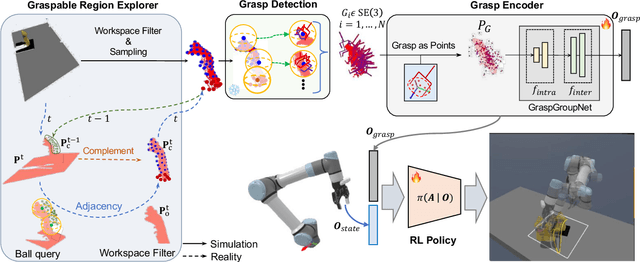
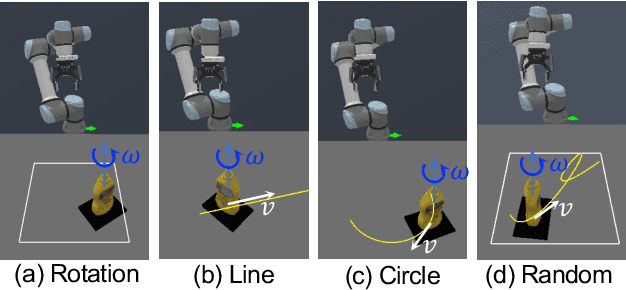
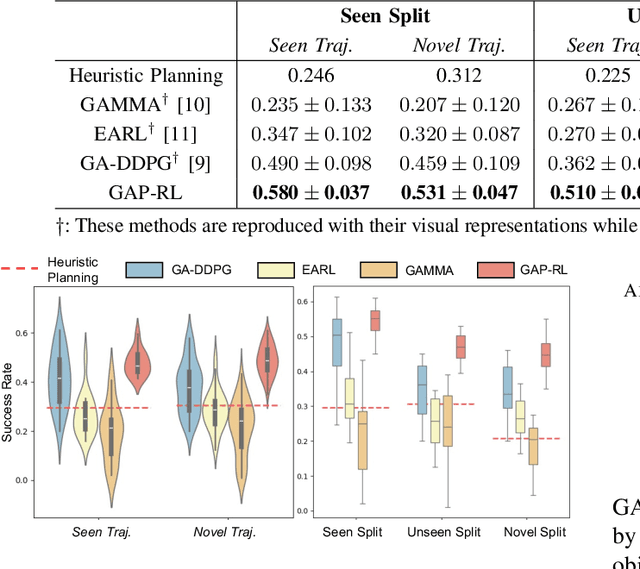
Dynamic grasping of moving objects in complex, continuous motion scenarios remains challenging. Reinforcement Learning (RL) has been applied in various robotic manipulation tasks, benefiting from its closed-loop property. However, existing RL-based methods do not fully explore the potential for enhancing visual representations. In this letter, we propose a novel framework called Grasps As Points for RL (GAP-RL) to effectively and reliably grasp moving objects. By implementing a fast region-based grasp detector, we build a Grasp Encoder by transforming 6D grasp poses into Gaussian points and extracting grasp features as a higher-level abstraction than the original object point features. Additionally, we develop a Graspable Region Explorer for real-world deployment, which searches for consistent graspable regions, enabling smoother grasp generation and stable policy execution. To assess the performance fairly, we construct a simulated dynamic grasping benchmark involving objects with various complex motions. Experiment results demonstrate that our method effectively generalizes to novel objects and unseen dynamic motions compared to other baselines. Real-world experiments further validate the framework's sim-to-real transferability.
Target-Oriented Object Grasping via Multimodal Human Guidance
Aug 20, 2024



In the context of human-robot interaction and collaboration scenarios, robotic grasping still encounters numerous challenges. Traditional grasp detection methods generally analyze the entire scene to predict grasps, leading to redundancy and inefficiency. In this work, we reconsider 6-DoF grasp detection from a target-referenced perspective and propose a Target-Oriented Grasp Network (TOGNet). TOGNet specifically targets local, object-agnostic region patches to predict grasps more efficiently. It integrates seamlessly with multimodal human guidance, including language instructions, pointing gestures, and interactive clicks. Thus our system comprises two primary functional modules: a guidance module that identifies the target object in 3D space and TOGNet, which detects region-focal 6-DoF grasps around the target, facilitating subsequent motion planning. Through 50 target-grasping simulation experiments in cluttered scenes, our system achieves a success rate improvement of about 13.7%. In real-world experiments, we demonstrate that our method excels in various target-oriented grasping scenarios.
Region-aware Grasp Framework with Normalized Grasp Space for 6-DoF Grasping in Cluttered Scene
Jun 03, 2024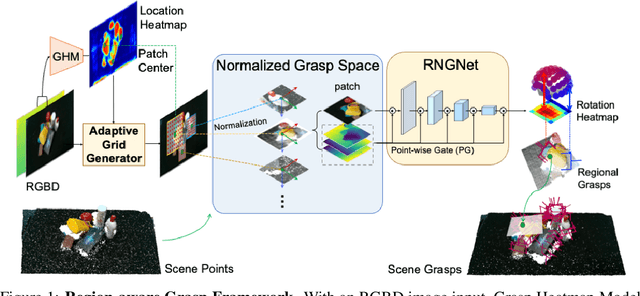
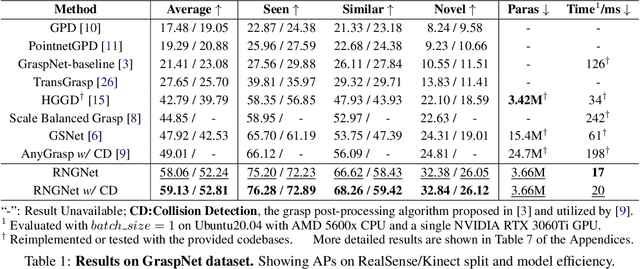
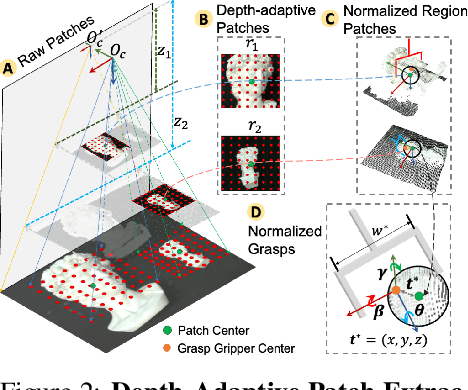

Regional geometric information is crucial for determining grasp poses. A series of region-based methods succeed in extracting regional features and enhancing grasp detection quality. However, faced with a cluttered scene with multiple objects and potential collision, the definition of the grasp-relevant region remains inconsistent among methods, and the relationship between grasps and regional spaces remains incompletely investigated. In this paper, from a novel region-aware and grasp-centric viewpoint, we propose Normalized Grasp Space (NGS), unifying the grasp representation within a normalized regional space. The relationship among the grasp widths, region scales, and gripper sizes is considered and empowers our method to generalize to grippers and scenes with different scales. Leveraging the characteristics of the NGS, we find that 2D CNNs are surprisingly underestimated for complicated 6-DoF grasp detection tasks in clutter scenes and build a highly efficient Region-aware Normalized Grasp Network (RNGNet). Experiments conducted on the public benchmark show that our method achieves the best grasp detection results compared to the previous state-of-the-arts while attaining a real-time inference speed of approximately 50 FPS. Real-world cluttered scene clearance experiments underscore the effectiveness of our method with a higher success rate than other methods. Further human-to-robot handover and moving object grasping experiments demonstrate the potential of our proposed method for closed-loop grasping in dynamic scenarios.