 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Depth Inpainting for Transparent and Reflective Objects
Oct 11, 2024



Transparent and reflective objects, which are common in our everyday lives, present a significant challenge to 3D imaging techniques due to their unique visual and optical properties. Faced with these types of objects, RGB-D cameras fail to capture the real depth value with their accurate spatial information. To address this issue, we propose DITR, a diffusion-based Depth Inpainting framework specifically designed for Transparent and Reflective objects. This network consists of two stages, including a Region Proposal stage and a Depth Inpainting stage. DITR dynamically analyzes the optical and geometric depth loss and inpaints them automatically. Furthermore, comprehensive experimental results demonstrate that DITR is highly effective in depth inpainting tasks of transparent and reflective objects with robust adaptability.
GAP-RL: Grasps As Points for RL Towards Dynamic Object Grasping
Oct 04, 2024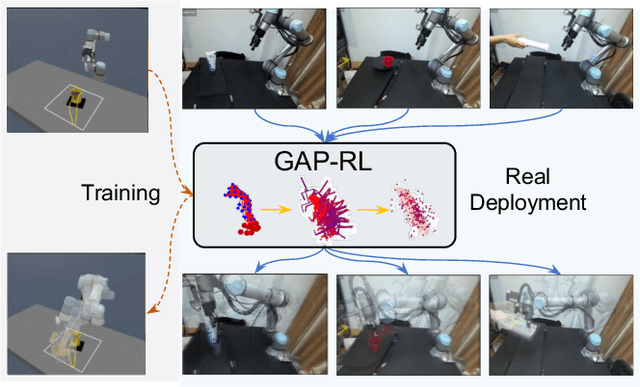
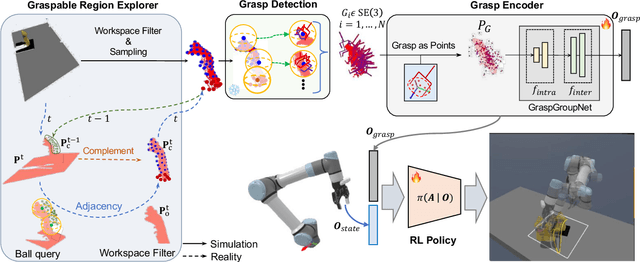
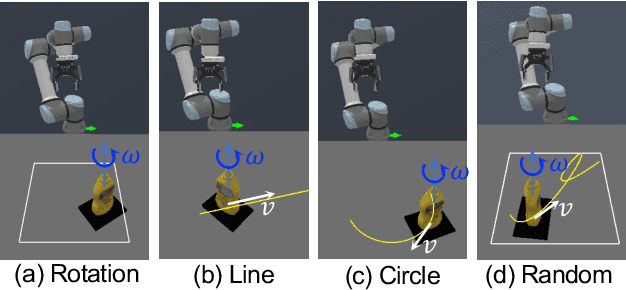
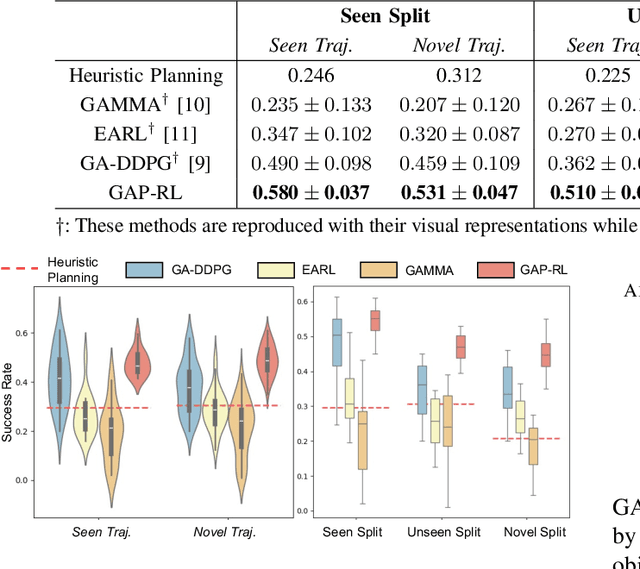
Dynamic grasping of moving objects in complex, continuous motion scenarios remains challenging. Reinforcement Learning (RL) has been applied in various robotic manipulation tasks, benefiting from its closed-loop property. However, existing RL-based methods do not fully explore the potential for enhancing visual representations. In this letter, we propose a novel framework called Grasps As Points for RL (GAP-RL) to effectively and reliably grasp moving objects. By implementing a fast region-based grasp detector, we build a Grasp Encoder by transforming 6D grasp poses into Gaussian points and extracting grasp features as a higher-level abstraction than the original object point features. Additionally, we develop a Graspable Region Explorer for real-world deployment, which searches for consistent graspable regions, enabling smoother grasp generation and stable policy execution. To assess the performance fairly, we construct a simulated dynamic grasping benchmark involving objects with various complex motions. Experiment results demonstrate that our method effectively generalizes to novel objects and unseen dynamic motions compared to other baselines. Real-world experiments further validate the framework's sim-to-real transferability.
Target-Oriented Object Grasping via Multimodal Human Guidance
Aug 20, 2024



In the context of human-robot interaction and collaboration scenarios, robotic grasping still encounters numerous challenges. Traditional grasp detection methods generally analyze the entire scene to predict grasps, leading to redundancy and inefficiency. In this work, we reconsider 6-DoF grasp detection from a target-referenced perspective and propose a Target-Oriented Grasp Network (TOGNet). TOGNet specifically targets local, object-agnostic region patches to predict grasps more efficiently. It integrates seamlessly with multimodal human guidance, including language instructions, pointing gestures, and interactive clicks. Thus our system comprises two primary functional modules: a guidance module that identifies the target object in 3D space and TOGNet, which detects region-focal 6-DoF grasps around the target, facilitating subsequent motion planning. Through 50 target-grasping simulation experiments in cluttered scenes, our system achieves a success rate improvement of about 13.7%. In real-world experiments, we demonstrate that our method excels in various target-oriented grasping scenarios.
Region-aware Grasp Framework with Normalized Grasp Space for 6-DoF Grasping in Cluttered Scene
Jun 03, 2024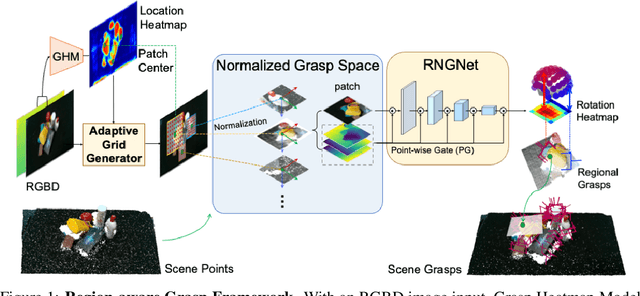
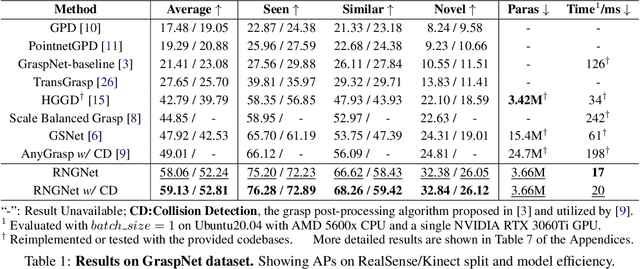
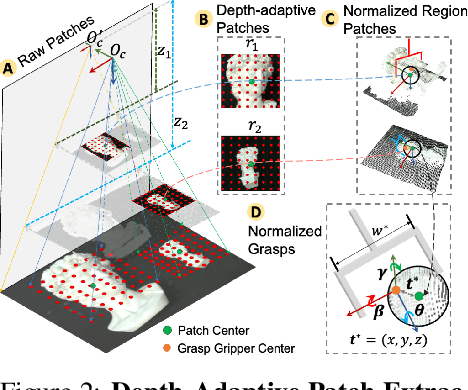

Regional geometric information is crucial for determining grasp poses. A series of region-based methods succeed in extracting regional features and enhancing grasp detection quality. However, faced with a cluttered scene with multiple objects and potential collision, the definition of the grasp-relevant region remains inconsistent among methods, and the relationship between grasps and regional spaces remains incompletely investigated. In this paper, from a novel region-aware and grasp-centric viewpoint, we propose Normalized Grasp Space (NGS), unifying the grasp representation within a normalized regional space. The relationship among the grasp widths, region scales, and gripper sizes is considered and empowers our method to generalize to grippers and scenes with different scales. Leveraging the characteristics of the NGS, we find that 2D CNNs are surprisingly underestimated for complicated 6-DoF grasp detection tasks in clutter scenes and build a highly efficient Region-aware Normalized Grasp Network (RNGNet). Experiments conducted on the public benchmark show that our method achieves the best grasp detection results compared to the previous state-of-the-arts while attaining a real-time inference speed of approximately 50 FPS. Real-world cluttered scene clearance experiments underscore the effectiveness of our method with a higher success rate than other methods. Further human-to-robot handover and moving object grasping experiments demonstrate the potential of our proposed method for closed-loop grasping in dynamic scenarios.
Rethinking 6-Dof Grasp Detection: A Flexible Framework for High-Quality Grasping
Mar 22, 2024Robotic grasping is a primitive skill for complex tasks and is fundamental to intelligence. For general 6-Dof grasping, most previous methods directly extract scene-level semantic or geometric information, while few of them consider the suitability for various downstream applications, such as target-oriented grasping. Addressing this issue, we rethink 6-Dof grasp detection from a grasp-centric view and propose a versatile grasp framework capable of handling both scene-level and target-oriented grasping. Our framework, FlexLoG, is composed of a Flexible Guidance Module and a Local Grasp Model. Specifically, the Flexible Guidance Module is compatible with both global (e.g., grasp heatmap) and local (e.g., visual grounding) guidance, enabling the generation of high-quality grasps across various tasks. The Local Grasp Model focuses on object-agnostic regional points and predicts grasps locally and intently. Experiment results reveal that our framework achieves over 18% and 23% improvement on unseen splits of the GraspNet-1Billion Dataset. Furthermore, real-world robotic tests in three distinct settings yield a 95% success rate.