 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocRefine: An Intelligent Framework for Scientific Document Understanding and Content Optimization based on Multimodal Large Model Agents
Aug 09, 2025The exponential growth of scientific literature in PDF format necessitates advanced tools for efficient and accurate document understanding, summarization, and content optimization. Traditional methods fall short in handling complex layouts and multimodal content, while direct application of Large Language Models (LLMs) and Vision-Language Large Models (LVLMs) lacks precision and control for intricate editing tasks. This paper introduces DocRefine, an innovative framework designed for intelligent understanding, content refinement, and automated summarization of scientific PDF documents, driven by natural language instructions. DocRefine leverages the power of advanced LVLMs (e.g., GPT-4o) by orchestrating a sophisticated multi-agent system comprising six specialized and collaborative agents: Layout & Structure Analysis, Multimodal Content Understanding, Instruction Decomposition, Content Refinement, Summarization & Generation, and Fidelity & Consistency Verification. This closed-loop feedback architecture ensures high semantic accuracy and visual fidelity. Evaluated on the comprehensive DocEditBench dataset, DocRefine consistently outperforms state-of-the-art baselines across various tasks, achieving overall scores of 86.7% for Semantic Consistency Score (SCS), 93.9% for Layout Fidelity Index (LFI), and 85.0% for Instruction Adherence Rate (IAR). These results demonstrate DocRefine's superior capability in handling complex multimodal document editing, preserving semantic integrity, and maintaining visual consistency, marking a significant advancement in automated scientific document processing.
Policy Gradient with Second Order Momentum
May 16, 2025We develop Policy Gradient with Second-Order Momentum (PG-SOM), a lightweight second-order optimisation scheme for reinforcement-learning policies. PG-SOM augments the classical REINFORCE update with two exponentially weighted statistics: a first-order gradient average and a diagonal approximation of the Hessian. By preconditioning the gradient with this curvature estimate, the method adaptively rescales each parameter, yielding faster and more stable ascent of the expected return. We provide a concise derivation, establish that the diagonal Hessian estimator is unbiased and positive-definite under mild regularity assumptions, and prove that the resulting update is a descent direction in expectation. Numerical experiments on standard control benchmarks show up to a 2.1x increase in sample efficiency and a substantial reduction in variance compared to first-order and Fisher-matrix baselines. These results indicate that even coarse second-order information can deliver significant practical gains while incurring only D memory overhead for a D-parameter policy. All code and reproducibility scripts will be made publicly available.
Contrastive Speaker-Aware Learning for Multi-party Dialogue Generation with LLMs
Mar 11, 2025Multi-party dialogue generation presents significant challenges due to the complex interplay of multiple speakers and interwoven conversational threads. Traditional approaches often fall short in capturing these complexities, particularly when relying on manually annotated dialogue relations. This paper introduces Speaker-Attentive LLM (SA-LLM), a novel generative model that leverages pre-trained Large Language Models (LLMs) and a speaker-aware contrastive learning strategy to address these challenges. SA-LLM incorporates a speaker-attributed input encoding and a contrastive learning objective to implicitly learn contextual coherence and speaker roles without explicit relation annotations. Extensive experiments on the Ubuntu IRC and Movie Dialogues datasets demonstrate that SA-LLM significantly outperforms state-of-the-art baselines in automatic and human evaluations, achieving superior performance in fluency, coherence, informativeness, and response diversity. Ablation studies and detailed error analyses further validate the effectiveness of the proposed speaker-attentive training approach, highlighting its robustness across different speaker roles and context lengths. The results underscore the potential of SA-LLM as a powerful and annotation-free solution for high-quality multi-party dialogue generation.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Exploring Large Vision-Language Models for Robust and Efficient Industrial Anomaly Detection
Dec 01, 2024



Industrial anomaly detection (IAD) plays a crucial role in the maintenance and quality control of manufacturing processes. In this paper, we propose a novel approach, Vision-Language Anomaly Detection via Contrastive Cross-Modal Training (CLAD), which leverages large vision-language models (LVLMs) to improve both anomaly detection and localization in industrial settings. CLAD aligns visual and textual features into a shared embedding space using contrastive learning, ensuring that normal instances are grouped together while anomalies are pushed apart. Through extensive experiments on two benchmark industrial datasets, MVTec-AD and VisA, we demonstrate that CLAD outperforms state-of-the-art methods in both image-level anomaly detection and pixel-level anomaly localization. Additionally, we provide ablation studies and human evaluation to validate the importance of key components in our method. Our approach not only achieves superior performance but also enhances interpretability by accurately localizing anomalies, making it a promising solution for real-world industrial applications.
QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou
Nov 18, 2024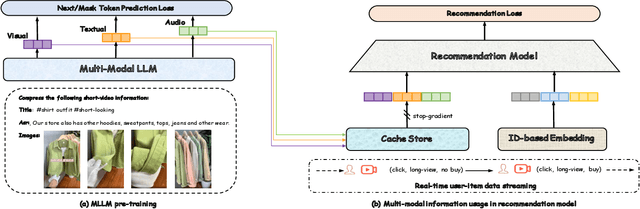
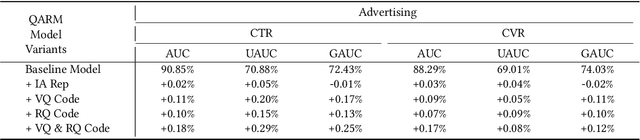
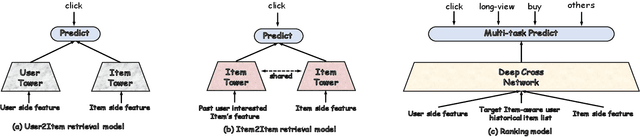
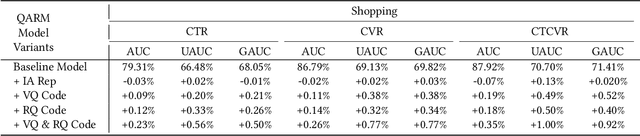
In recent years, with the significant evolution of multi-modal large models, many recommender researchers realized the potential of multi-modal information for user interest modeling. In industry, a wide-used modeling architecture is a cascading paradigm: (1) first pre-training a multi-modal model to provide omnipotent representations for downstream services; (2) The downstream recommendation model takes the multi-modal representation as additional input to fit real user-item behaviours. Although such paradigm achieves remarkable improvements, however, there still exist two problems that limit model performance: (1) Representation Unmatching: The pre-trained multi-modal model is always supervised by the classic NLP/CV tasks, while the recommendation models are supervised by real user-item interaction. As a result, the two fundamentally different tasks' goals were relatively separate, and there was a lack of consistent objective on their representations; (2) Representation Unlearning: The generated multi-modal representations are always stored in cache store and serve as extra fixed input of recommendation model, thus could not be updated by recommendation model gradient, further unfriendly for downstream training. Inspired by the two difficulties challenges in downstream tasks usage, we introduce a quantitative multi-modal framework to customize the specialized and trainable multi-modal information for different downstream models.
Efficient 3D Perception on Multi-Sweep Point Cloud with Gumbel Spatial Pruning
Nov 12, 2024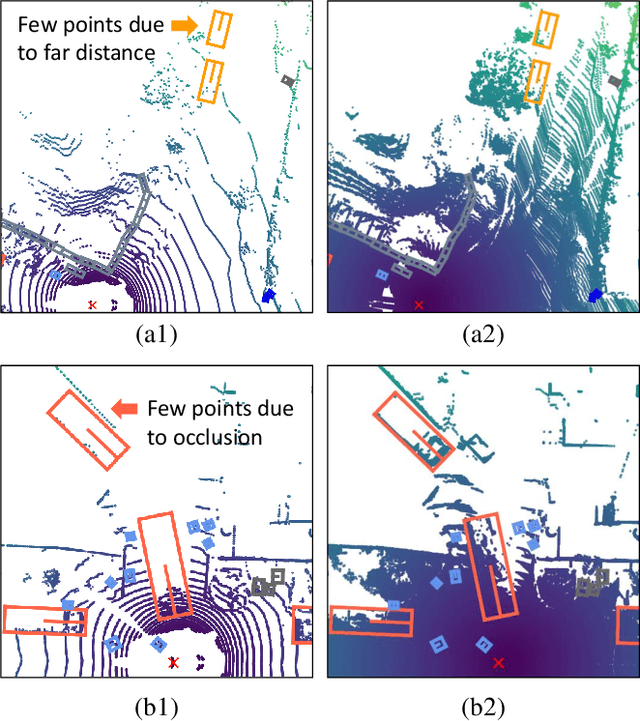
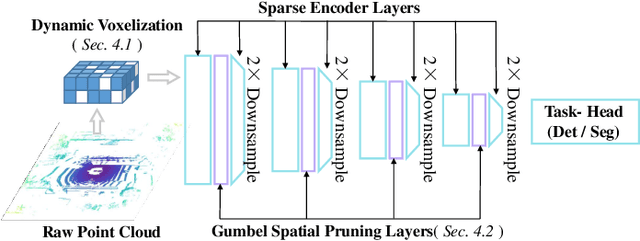
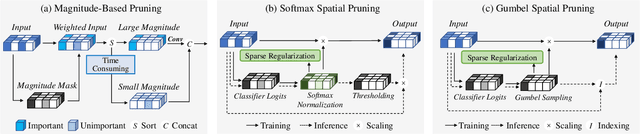
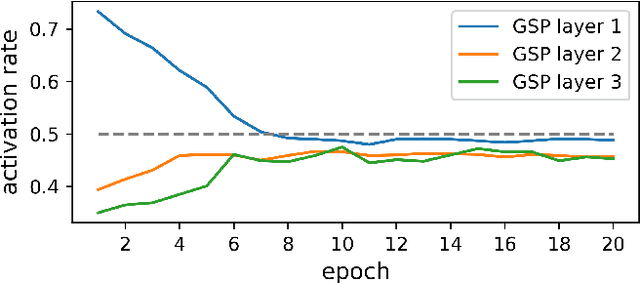
This paper studies point cloud perception within outdoor environments. Existing methods face limitations in recognizing objects located at a distance or occluded, due to the sparse nature of outdoor point clouds. In this work, we observe a significant mitigation of this problem by accumulating multiple temporally consecutive LiDAR sweeps, resulting in a remarkable improvement in perception accuracy. However, the computation cost also increases, hindering previous approaches from utilizing a large number of LiDAR sweeps. To tackle this challenge, we find that a considerable portion of points in the accumulated point cloud is redundant, and discarding these points has minimal impact on perception accuracy. We introduce a simple yet effective Gumbel Spatial Pruning (GSP) layer that dynamically prunes points based on a learned end-to-end sampling. The GSP layer is decoupled from other network components and thus can be seamlessly integrated into existing point cloud network architectures. Without incurring additional computational overhead, we increase the number of LiDAR sweeps from 10, a common practice, to as many as 40. Consequently, there is a significant enhancement in perception performance. For instance, in nuScenes 3D object detection and BEV map segmentation tasks, our pruning strategy improves the vanilla TransL baseline and other baseline methods.
Diffusion-Based Depth Inpainting for Transparent and Reflective Objects
Oct 11, 2024



Transparent and reflective objects, which are common in our everyday lives, present a significant challenge to 3D imaging techniques due to their unique visual and optical properties. Faced with these types of objects, RGB-D cameras fail to capture the real depth value with their accurate spatial information. To address this issue, we propose DITR, a diffusion-based Depth Inpainting framework specifically designed for Transparent and Reflective objects. This network consists of two stages, including a Region Proposal stage and a Depth Inpainting stage. DITR dynamically analyzes the optical and geometric depth loss and inpaints them automatically. Furthermore, comprehensive experimental results demonstrate that DITR is highly effective in depth inpainting tasks of transparent and reflective objects with robust adaptability.
Segment, Lift and Fit: Automatic 3D Shape Labeling from 2D Prompts
Jul 16, 2024

This paper proposes an algorithm for automatically labeling 3D objects from 2D point or box prompts, especially focusing on applications in autonomous driving. Unlike previous arts, our auto-labeler predicts 3D shapes instead of bounding boxes and does not require training on a specific dataset. We propose a Segment, Lift, and Fit (SLF) paradigm to achieve this goal. Firstly, we segment high-quality instance masks from the prompts using the Segment Anything Model (SAM) and transform the remaining problem into predicting 3D shapes from given 2D masks. Due to the ill-posed nature of this problem, it presents a significant challenge as multiple 3D shapes can project into an identical mask. To tackle this issue, we then lift 2D masks to 3D forms and employ gradient descent to adjust their poses and shapes until the projections fit the masks and the surfaces conform to surrounding LiDAR points. Notably, since we do not train on a specific dataset, the SLF auto-labeler does not overfit to biased annotation patterns in the training set as other methods do. Thus, the generalization ability across different datasets improves. Experimental results on the KITTI dataset demonstrate that the SLF auto-labeler produces high-quality bounding box annotations, achieving an AP@0.5 IoU of nearly 90\%. Detectors trained with the generated pseudo-labels perform nearly as well as those trained with actual ground-truth annotations. Furthermore, the SLF auto-labeler shows promising results in detailed shape predictions, providing a potential alternative for the occupancy annotation of dynamic objects.
Optimizing Psychological Counseling with Instruction-Tuned Large Language Models
Jun 19, 2024


The advent of large language models (LLMs) has significantly advanced various fields, including natural language processing and automated dialogue systems. This paper explores the application of LLMs in psychological counseling, addressing the increasing demand for mental health services. We present a method for instruction tuning LLMs with specialized prompts to enhance their performance in providing empathetic, relevant, and supportive responses. Our approach involves developing a comprehensive dataset of counseling-specific prompts, refining them through feedback from professional counselors, and conducting rigorous evaluations using both automatic metrics and human assessments. The results demonstrate that our instruction-tuned model outperforms several baseline LLMs, highlighting its potential as a scalable and accessible tool for mental health support.