 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Vision-Language-Action World Models for Autonomous Driving
Apr 10, 2026Vision-Language-Action (VLA) models have recently achieved notable progress in end-to-end autonomous driving by integrating perception, reasoning, and control within a unified multimodal framework. However, they often lack explicit modeling of temporal dynamics and global world consistency, which limits their foresight and safety. In contrast, world models can simulate plausible future scenes but generally struggle to reason about or evaluate the imagined future they generate. In this work, we present VLA-World, a simple yet effective VLA world model that unifies predictive imagination with reflective reasoning to improve driving foresight. VLA-World first uses an action-derived feasible trajectory to guide the generation of the next-frame image, capturing rich spatial and temporal cues that describe how the surrounding environment evolves. The model then reasons over this self-generated future imagined frame to refine the predicted trajectory, achieving higher performance and better interpretability. To support this pipeline, we curate nuScenes-GR-20K, a generative reasoning dataset derived from nuScenes, and employ a three-stage training strategy that includes pretraining, supervised fine-tuning, and reinforcement learning. Extensive experiments demonstrate that VLA-World consistently surpasses state-of-the-art VLA and world-model baselines on both planning and future-generation benchmarks. Project page: https://vlaworld.github.io
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
GenieDrive: Towards Physics-Aware Driving World Model with 4D Occupancy Guided Video Generation
Dec 14, 2025Physics-aware driving world model is essential for drive planning, out-of-distribution data synthesis, and closed-loop evaluation. However, existing methods often rely on a single diffusion model to directly map driving actions to videos, which makes learning difficult and leads to physically inconsistent outputs. To overcome these challenges, we propose GenieDrive, a novel framework designed for physics-aware driving video generation. Our approach starts by generating 4D occupancy, which serves as a physics-informed foundation for subsequent video generation. 4D occupancy contains rich physical information, including high-resolution 3D structures and dynamics. To facilitate effective compression of such high-resolution occupancy, we propose a VAE that encodes occupancy into a latent tri-plane representation, reducing the latent size to only 58% of that used in previous methods. We further introduce Mutual Control Attention (MCA) to accurately model the influence of control on occupancy evolution, and we jointly train the VAE and the subsequent prediction module in an end-to-end manner to maximize forecasting accuracy. Together, these designs yield a 7.2% improvement in forecasting mIoU at an inference speed of 41 FPS, while using only 3.47 M parameters. Additionally, a Normalized Multi-View Attention is introduced in the video generation model to generate multi-view driving videos with guidance from our 4D occupancy, significantly improving video quality with a 20.7% reduction in FVD. Experiments demonstrate that GenieDrive enables highly controllable, multi-view consistent, and physics-aware driving video generation.
Efficient 3D Perception on Multi-Sweep Point Cloud with Gumbel Spatial Pruning
Nov 12, 2024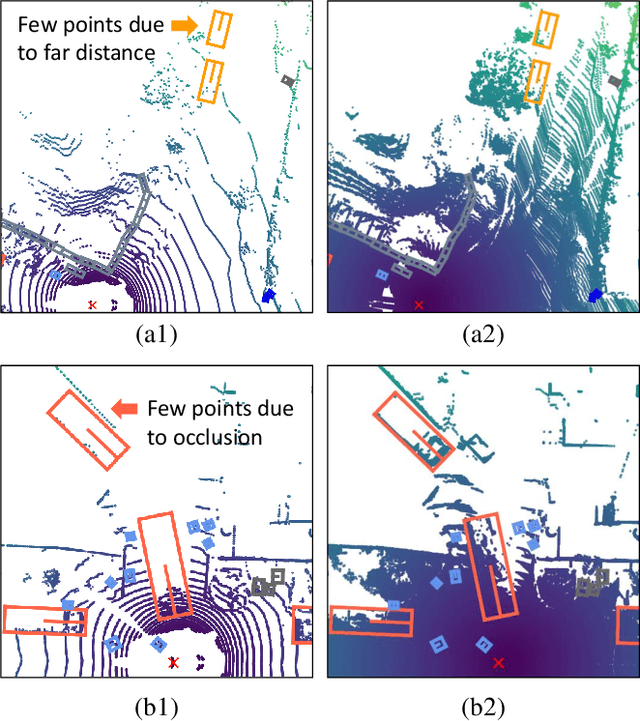
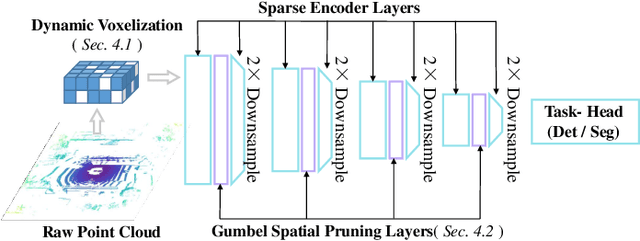
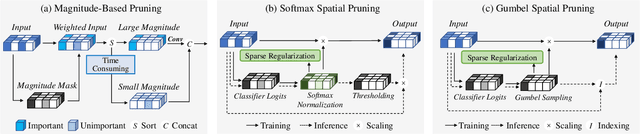
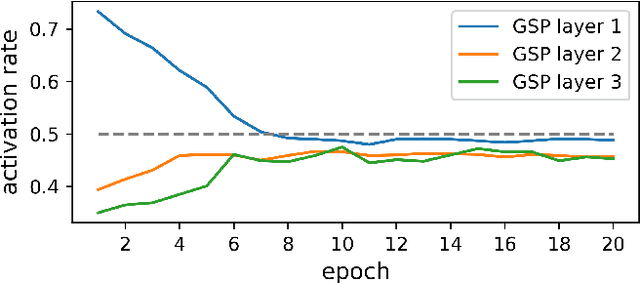
This paper studies point cloud perception within outdoor environments. Existing methods face limitations in recognizing objects located at a distance or occluded, due to the sparse nature of outdoor point clouds. In this work, we observe a significant mitigation of this problem by accumulating multiple temporally consecutive LiDAR sweeps, resulting in a remarkable improvement in perception accuracy. However, the computation cost also increases, hindering previous approaches from utilizing a large number of LiDAR sweeps. To tackle this challenge, we find that a considerable portion of points in the accumulated point cloud is redundant, and discarding these points has minimal impact on perception accuracy. We introduce a simple yet effective Gumbel Spatial Pruning (GSP) layer that dynamically prunes points based on a learned end-to-end sampling. The GSP layer is decoupled from other network components and thus can be seamlessly integrated into existing point cloud network architectures. Without incurring additional computational overhead, we increase the number of LiDAR sweeps from 10, a common practice, to as many as 40. Consequently, there is a significant enhancement in perception performance. For instance, in nuScenes 3D object detection and BEV map segmentation tasks, our pruning strategy improves the vanilla TransL baseline and other baseline methods.
ReliOcc: Towards Reliable Semantic Occupancy Prediction via Uncertainty Learning
Sep 26, 2024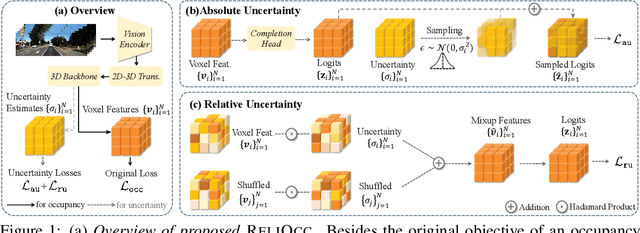
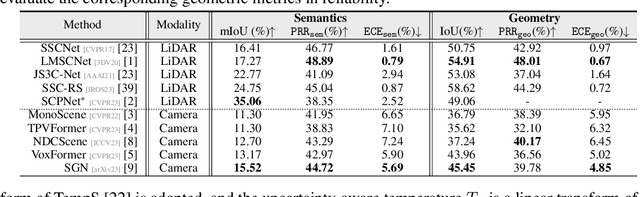
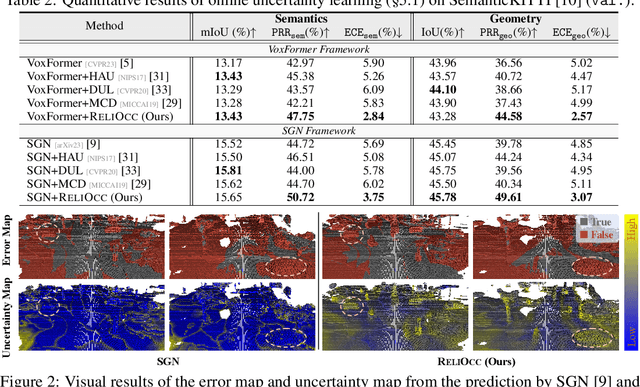
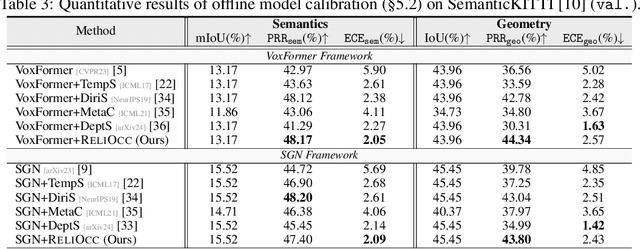
Vision-centric semantic occupancy prediction plays a crucial role in autonomous driving, which requires accurate and reliable predictions from low-cost sensors. Although having notably narrowed the accuracy gap with LiDAR, there is still few research effort to explore the reliability in predicting semantic occupancy from camera. In this paper, we conduct a comprehensive evaluation of existing semantic occupancy prediction models from a reliability perspective for the first time. Despite the gradual alignment of camera-based models with LiDAR in term of accuracy, a significant reliability gap persists. To addresses this concern, we propose ReliOcc, a method designed to enhance the reliability of camera-based occupancy networks. ReliOcc provides a plug-and-play scheme for existing models, which integrates hybrid uncertainty from individual voxels with sampling-based noise and relative voxels through mix-up learning. Besides, an uncertainty-aware calibration strategy is devised to further enhance model reliability in offline mode. Extensive experiments under various settings demonstrate that ReliOcc significantly enhances model reliability while maintaining the accuracy of both geometric and semantic predictions. Importantly, our proposed approach exhibits robustness to sensor failures and out of domain noises during inference.
VEON: Vocabulary-Enhanced Occupancy Prediction
Jul 17, 2024



Perceiving the world as 3D occupancy supports embodied agents to avoid collision with any types of obstacle. While open-vocabulary image understanding has prospered recently, how to bind the predicted 3D occupancy grids with open-world semantics still remains under-explored due to limited open-world annotations. Hence, instead of building our model from scratch, we try to blend 2D foundation models, specifically a depth model MiDaS and a semantic model CLIP, to lift the semantics to 3D space, thus fulfilling 3D occupancy. However, building upon these foundation models is not trivial. First, the MiDaS faces the depth ambiguity problem, i.e., it only produces relative depth but fails to estimate bin depth for feature lifting. Second, the CLIP image features lack high-resolution pixel-level information, which limits the 3D occupancy accuracy. Third, open vocabulary is often trapped by the long-tail problem. To address these issues, we propose VEON for Vocabulary-Enhanced Occupancy predictioN by not only assembling but also adapting these foundation models. We first equip MiDaS with a Zoedepth head and low-rank adaptation (LoRA) for relative-metric-bin depth transformation while reserving beneficial depth prior. Then, a lightweight side adaptor network is attached to the CLIP vision encoder to generate high-resolution features for fine-grained 3D occupancy prediction. Moreover, we design a class reweighting strategy to give priority to the tail classes. With only 46M trainable parameters and zero manual semantic labels, VEON achieves 15.14 mIoU on Occ3D-nuScenes, and shows the capability of recognizing objects with open-vocabulary categories, meaning that our VEON is label-efficient, parameter-efficient, and precise enough.
Segment, Lift and Fit: Automatic 3D Shape Labeling from 2D Prompts
Jul 16, 2024

This paper proposes an algorithm for automatically labeling 3D objects from 2D point or box prompts, especially focusing on applications in autonomous driving. Unlike previous arts, our auto-labeler predicts 3D shapes instead of bounding boxes and does not require training on a specific dataset. We propose a Segment, Lift, and Fit (SLF) paradigm to achieve this goal. Firstly, we segment high-quality instance masks from the prompts using the Segment Anything Model (SAM) and transform the remaining problem into predicting 3D shapes from given 2D masks. Due to the ill-posed nature of this problem, it presents a significant challenge as multiple 3D shapes can project into an identical mask. To tackle this issue, we then lift 2D masks to 3D forms and employ gradient descent to adjust their poses and shapes until the projections fit the masks and the surfaces conform to surrounding LiDAR points. Notably, since we do not train on a specific dataset, the SLF auto-labeler does not overfit to biased annotation patterns in the training set as other methods do. Thus, the generalization ability across different datasets improves. Experimental results on the KITTI dataset demonstrate that the SLF auto-labeler produces high-quality bounding box annotations, achieving an AP@0.5 IoU of nearly 90\%. Detectors trained with the generated pseudo-labels perform nearly as well as those trained with actual ground-truth annotations. Furthermore, the SLF auto-labeler shows promising results in detailed shape predictions, providing a potential alternative for the occupancy annotation of dynamic objects.
OccGen: Generative Multi-modal 3D Occupancy Prediction for Autonomous Driving
Apr 23, 2024



Existing solutions for 3D semantic occupancy prediction typically treat the task as a one-shot 3D voxel-wise segmentation perception problem. These discriminative methods focus on learning the mapping between the inputs and occupancy map in a single step, lacking the ability to gradually refine the occupancy map and the reasonable scene imaginative capacity to complete the local regions somewhere. In this paper, we introduce OccGen, a simple yet powerful generative perception model for the task of 3D semantic occupancy prediction. OccGen adopts a ''noise-to-occupancy'' generative paradigm, progressively inferring and refining the occupancy map by predicting and eliminating noise originating from a random Gaussian distribution. OccGen consists of two main components: a conditional encoder that is capable of processing multi-modal inputs, and a progressive refinement decoder that applies diffusion denoising using the multi-modal features as conditions. A key insight of this generative pipeline is that the diffusion denoising process is naturally able to model the coarse-to-fine refinement of the dense 3D occupancy map, therefore producing more detailed predictions. Extensive experiments on several occupancy benchmarks demonstrate the effectiveness of the proposed method compared to the state-of-the-art methods. For instance, OccGen relatively enhances the mIoU by 9.5%, 6.3%, and 13.3% on nuScenes-Occupancy dataset under the muli-modal, LiDAR-only, and camera-only settings, respectively. Moreover, as a generative perception model, OccGen exhibits desirable properties that discriminative models cannot achieve, such as providing uncertainty estimates alongside its multiple-step predictions.
SparseOcc: Rethinking Sparse Latent Representation for Vision-Based Semantic Occupancy Prediction
Apr 15, 2024
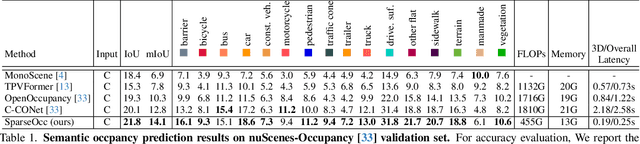
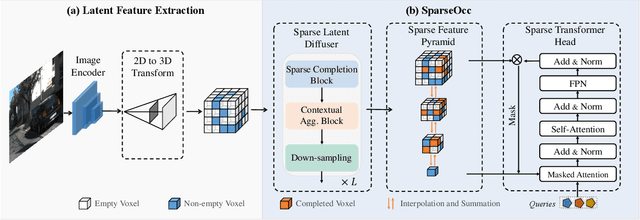
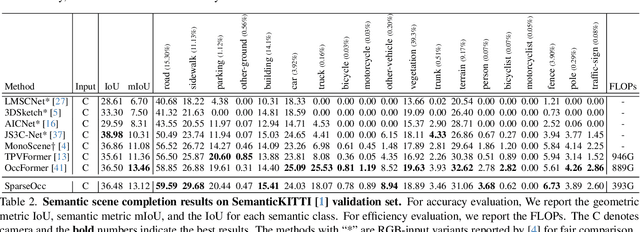
Vision-based perception for autonomous driving requires an explicit modeling of a 3D space, where 2D latent representations are mapped and subsequent 3D operators are applied. However, operating on dense latent spaces introduces a cubic time and space complexity, which limits scalability in terms of perception range or spatial resolution. Existing approaches compress the dense representation using projections like Bird's Eye View (BEV) or Tri-Perspective View (TPV). Although efficient, these projections result in information loss, especially for tasks like semantic occupancy prediction. To address this, we propose SparseOcc, an efficient occupancy network inspired by sparse point cloud processing. It utilizes a lossless sparse latent representation with three key innovations. Firstly, a 3D sparse diffuser performs latent completion using spatially decomposed 3D sparse convolutional kernels. Secondly, a feature pyramid and sparse interpolation enhance scales with information from others. Finally, the transformer head is redesigned as a sparse variant. SparseOcc achieves a remarkable 74.9% reduction on FLOPs over the dense baseline. Interestingly, it also improves accuracy, from 12.8% to 14.1% mIOU, which in part can be attributed to the sparse representation's ability to avoid hallucinations on empty voxels.
* 10 pages, 4 figures, accepted by CVPR 2024
Unbiased IoU for Spherical Image Object Detection
Aug 18, 2021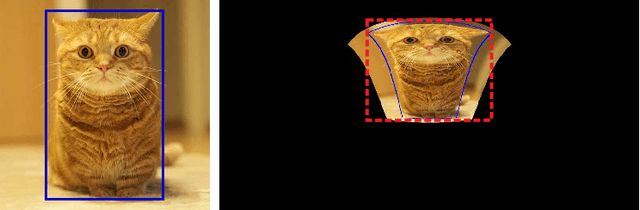
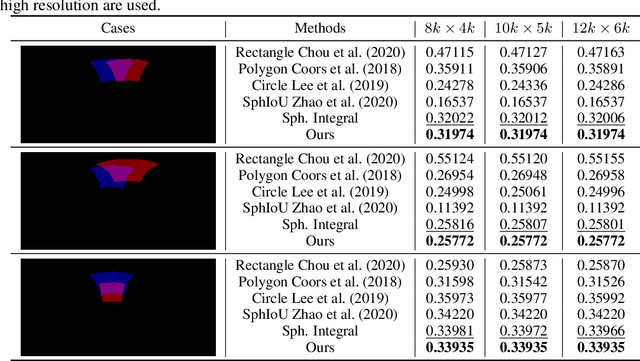
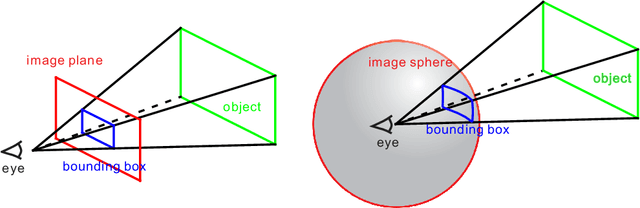

As one of the most fundamental and challenging problems in computer vision, object detection tries to locate object instances and find their categories in natural images. The most important step in the evaluation of object detection algorithm is calculating the intersection-over-union (IoU) between the predicted bounding box and the ground truth one. Although this procedure is well-defined and solved for planar images, it is not easy for spherical image object detection. Existing methods either compute the IoUs based on biased bounding box representations or make excessive approximations, thus would give incorrect results. In this paper, we first identify that spherical rectangles are unbiased bounding boxes for objects in spherical images, and then propose an analytical method for IoU calculation without any approximations. Based on the unbiased representation and calculation, we also present an anchor free object detection algorithm for spherical images. The experiments on two spherical object detection datasets show that the proposed method can achieve better performance than existing methods.