 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Vision-Language-Action World Models for Autonomous Driving
Apr 10, 2026Vision-Language-Action (VLA) models have recently achieved notable progress in end-to-end autonomous driving by integrating perception, reasoning, and control within a unified multimodal framework. However, they often lack explicit modeling of temporal dynamics and global world consistency, which limits their foresight and safety. In contrast, world models can simulate plausible future scenes but generally struggle to reason about or evaluate the imagined future they generate. In this work, we present VLA-World, a simple yet effective VLA world model that unifies predictive imagination with reflective reasoning to improve driving foresight. VLA-World first uses an action-derived feasible trajectory to guide the generation of the next-frame image, capturing rich spatial and temporal cues that describe how the surrounding environment evolves. The model then reasons over this self-generated future imagined frame to refine the predicted trajectory, achieving higher performance and better interpretability. To support this pipeline, we curate nuScenes-GR-20K, a generative reasoning dataset derived from nuScenes, and employ a three-stage training strategy that includes pretraining, supervised fine-tuning, and reinforcement learning. Extensive experiments demonstrate that VLA-World consistently surpasses state-of-the-art VLA and world-model baselines on both planning and future-generation benchmarks. Project page: https://vlaworld.github.io
CT-1: Vision-Language-Camera Models Transfer Spatial Reasoning Knowledge to Camera-Controllable Video Generation
Apr 10, 2026Camera-controllable video generation aims to synthesize videos with flexible and physically plausible camera movements. However, existing methods either provide imprecise camera control from text prompts or rely on labor-intensive manual camera trajectory parameters, limiting their use in automated scenarios. To address these issues, we propose a novel Vision-Language-Camera model, termed CT-1 (Camera Transformer 1), a specialized model designed to transfer spatial reasoning knowledge to video generation by accurately estimating camera trajectories. Built upon vision-language modules and a Diffusion Transformer model, CT-1 employs a Wavelet-based Regularization Loss in the frequency domain to effectively learn complex camera trajectory distributions. These trajectories are integrated into a video diffusion model to enable spatially aware camera control that aligns with user intentions. To facilitate the training of CT-1, we design a dedicated data curation pipeline and construct CT-200K, a large-scale dataset containing over 47M frames. Experimental results demonstrate that our framework successfully bridges the gap between spatial reasoning and video synthesis, yielding faithful and high-quality camera-controllable videos and improving camera control accuracy by 25.7% over prior methods.
LiteFusion: Taming 3D Object Detectors from Vision-Based to Multi-Modal with Minimal Adaptation
Dec 23, 20253D object detection is fundamental for safe and robust intelligent transportation systems. Current multi-modal 3D object detectors often rely on complex architectures and training strategies to achieve higher detection accuracy. However, these methods heavily rely on the LiDAR sensor so that they suffer from large performance drops when LiDAR is absent, which compromises the robustness and safety of autonomous systems in practical scenarios. Moreover, existing multi-modal detectors face difficulties in deployment on diverse hardware platforms, such as NPUs and FPGAs, due to their reliance on 3D sparse convolution operators, which are primarily optimized for NVIDIA GPUs. To address these challenges, we reconsider the role of LiDAR in the camera-LiDAR fusion paradigm and introduce a novel multi-modal 3D detector, LiteFusion. Instead of treating LiDAR point clouds as an independent modality with a separate feature extraction backbone, LiteFusion utilizes LiDAR data as a complementary source of geometric information to enhance camera-based detection. This straightforward approach completely eliminates the reliance on a 3D backbone, making the method highly deployment-friendly. Specifically, LiteFusion integrates complementary features from LiDAR points into image features within a quaternion space, where the orthogonal constraints are well-preserved during network training. This helps model domain-specific relations across modalities, yielding a compact cross-modal embedding. Experiments on the nuScenes dataset show that LiteFusion improves the baseline vision-based detector by +20.4% mAP and +19.7% NDS with a minimal increase in parameters (1.1%) without using dedicated LiDAR encoders. Notably, even in the absence of LiDAR input, LiteFusion maintains strong results , highlighting its favorable robustness and effectiveness across diverse fusion paradigms and deployment scenarios.
Grounding Everything in Tokens for Multimodal Large Language Models
Dec 11, 2025Multimodal large language models (MLLMs) have made significant advancements in vision understanding and reasoning. However, the autoregressive Transformer architecture used by MLLMs requries tokenization on input images, which limits their ability to accurately ground objects within the 2D image space. This raises an important question: how can sequential language tokens be improved to better ground objects in 2D spatial space for MLLMs? To address this, we present a spatial representation method for grounding objects, namely GETok, that integrates a specialized vocabulary of learnable tokens into MLLMs. GETok first uses grid tokens to partition the image plane into structured spatial anchors, and then exploits offset tokens to enable precise and iterative refinement of localization predictions. By embedding spatial relationships directly into tokens, GETok significantly advances MLLMs in native 2D space reasoning without modifying the autoregressive architecture. Extensive experiments demonstrate that GETok achieves superior performance over the state-of-the-art methods across various referring tasks in both supervised fine-tuning and reinforcement learning settings.
Enhancing Sampling Protocol for Robust Point Cloud Classification
Aug 22, 2024Established sampling protocols for 3D point cloud learning, such as Farthest Point Sampling (FPS) and Fixed Sample Size (FSS), have long been recognized and utilized. However, real-world data often suffer from corrputions such as sensor noise, which violates the benignness assumption of point cloud in current protocols. Consequently, they are notably vulnerable to noise, posing significant safety risks in critical applications like autonomous driving. To address these issues, we propose an enhanced point cloud sampling protocol, PointDR, which comprises two components: 1) Downsampling for key point identification and 2) Resampling for flexible sample size. Furthermore, differentiated strategies are implemented for training and inference processes. Particularly, an isolation-rated weight considering local density is designed for the downsampling method, assisting it in performing random key points selection in the training phase and bypassing noise in the inference phase. A local-geometry-preserved upsampling is incorporated into resampling, facilitating it to maintain a stochastic sample size in the training stage and complete insufficient data in the inference. It is crucial to note that the proposed protocol is free of model architecture altering and extra learning, thus minimal efforts are demanded for its replacement of the existing one. Despite the simplicity, it substantially improves the robustness of point cloud learning, showcased by outperforming the state-of-the-art methods on multiple benchmarks of corrupted point cloud classification. The code will be available upon the paper's acceptance.
VEON: Vocabulary-Enhanced Occupancy Prediction
Jul 17, 2024



Perceiving the world as 3D occupancy supports embodied agents to avoid collision with any types of obstacle. While open-vocabulary image understanding has prospered recently, how to bind the predicted 3D occupancy grids with open-world semantics still remains under-explored due to limited open-world annotations. Hence, instead of building our model from scratch, we try to blend 2D foundation models, specifically a depth model MiDaS and a semantic model CLIP, to lift the semantics to 3D space, thus fulfilling 3D occupancy. However, building upon these foundation models is not trivial. First, the MiDaS faces the depth ambiguity problem, i.e., it only produces relative depth but fails to estimate bin depth for feature lifting. Second, the CLIP image features lack high-resolution pixel-level information, which limits the 3D occupancy accuracy. Third, open vocabulary is often trapped by the long-tail problem. To address these issues, we propose VEON for Vocabulary-Enhanced Occupancy predictioN by not only assembling but also adapting these foundation models. We first equip MiDaS with a Zoedepth head and low-rank adaptation (LoRA) for relative-metric-bin depth transformation while reserving beneficial depth prior. Then, a lightweight side adaptor network is attached to the CLIP vision encoder to generate high-resolution features for fine-grained 3D occupancy prediction. Moreover, we design a class reweighting strategy to give priority to the tail classes. With only 46M trainable parameters and zero manual semantic labels, VEON achieves 15.14 mIoU on Occ3D-nuScenes, and shows the capability of recognizing objects with open-vocabulary categories, meaning that our VEON is label-efficient, parameter-efficient, and precise enough.
OccGen: Generative Multi-modal 3D Occupancy Prediction for Autonomous Driving
Apr 23, 2024



Existing solutions for 3D semantic occupancy prediction typically treat the task as a one-shot 3D voxel-wise segmentation perception problem. These discriminative methods focus on learning the mapping between the inputs and occupancy map in a single step, lacking the ability to gradually refine the occupancy map and the reasonable scene imaginative capacity to complete the local regions somewhere. In this paper, we introduce OccGen, a simple yet powerful generative perception model for the task of 3D semantic occupancy prediction. OccGen adopts a ''noise-to-occupancy'' generative paradigm, progressively inferring and refining the occupancy map by predicting and eliminating noise originating from a random Gaussian distribution. OccGen consists of two main components: a conditional encoder that is capable of processing multi-modal inputs, and a progressive refinement decoder that applies diffusion denoising using the multi-modal features as conditions. A key insight of this generative pipeline is that the diffusion denoising process is naturally able to model the coarse-to-fine refinement of the dense 3D occupancy map, therefore producing more detailed predictions. Extensive experiments on several occupancy benchmarks demonstrate the effectiveness of the proposed method compared to the state-of-the-art methods. For instance, OccGen relatively enhances the mIoU by 9.5%, 6.3%, and 13.3% on nuScenes-Occupancy dataset under the muli-modal, LiDAR-only, and camera-only settings, respectively. Moreover, as a generative perception model, OccGen exhibits desirable properties that discriminative models cannot achieve, such as providing uncertainty estimates alongside its multiple-step predictions.
SparseOcc: Rethinking Sparse Latent Representation for Vision-Based Semantic Occupancy Prediction
Apr 15, 2024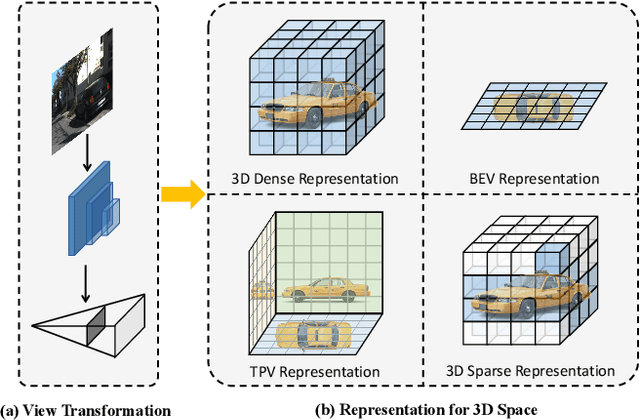
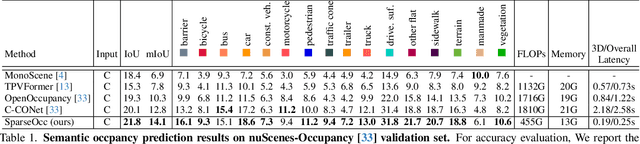
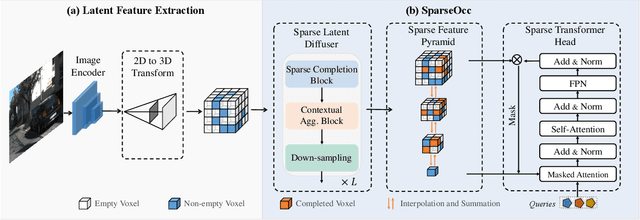
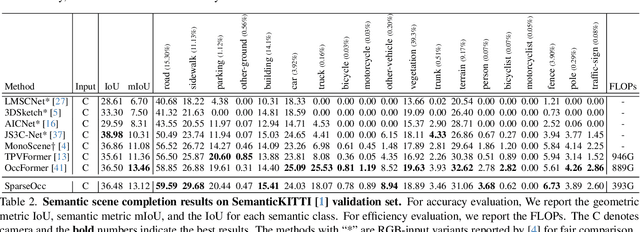
Vision-based perception for autonomous driving requires an explicit modeling of a 3D space, where 2D latent representations are mapped and subsequent 3D operators are applied. However, operating on dense latent spaces introduces a cubic time and space complexity, which limits scalability in terms of perception range or spatial resolution. Existing approaches compress the dense representation using projections like Bird's Eye View (BEV) or Tri-Perspective View (TPV). Although efficient, these projections result in information loss, especially for tasks like semantic occupancy prediction. To address this, we propose SparseOcc, an efficient occupancy network inspired by sparse point cloud processing. It utilizes a lossless sparse latent representation with three key innovations. Firstly, a 3D sparse diffuser performs latent completion using spatially decomposed 3D sparse convolutional kernels. Secondly, a feature pyramid and sparse interpolation enhance scales with information from others. Finally, the transformer head is redesigned as a sparse variant. SparseOcc achieves a remarkable 74.9% reduction on FLOPs over the dense baseline. Interestingly, it also improves accuracy, from 12.8% to 14.1% mIOU, which in part can be attributed to the sparse representation's ability to avoid hallucinations on empty voxels.
* 10 pages, 4 figures, accepted by CVPR 2024
DSU-net: Dense SegU-net for automatic head-and-neck tumor segmentation in MR images
Jun 12, 2020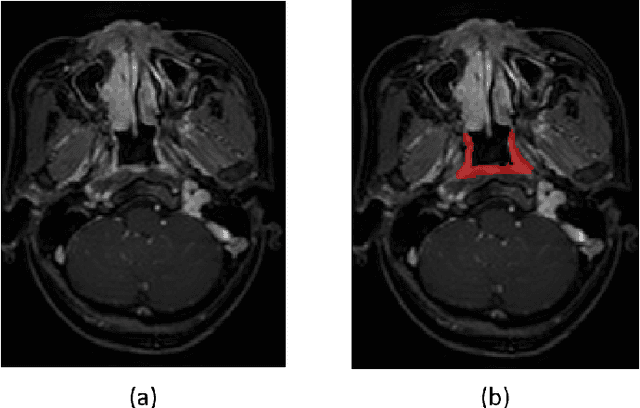

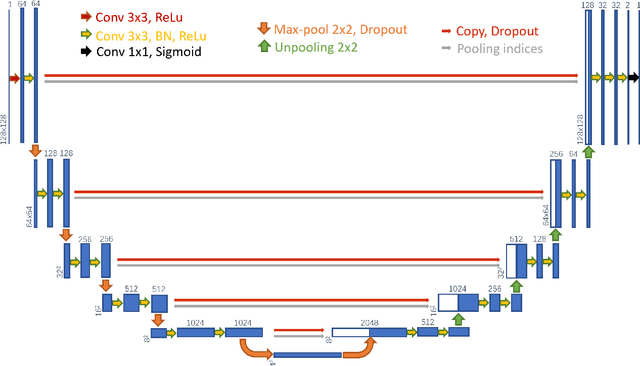

Precise and accurate segmentation of the most common head-and-neck tumor, nasopharyngeal carcinoma (NPC), in MRI sheds light on treatment and regulatory decisions making. However, the large variations in the lesion size and shape of NPC, boundary ambiguity, as well as the limited available annotated samples conspire NPC segmentation in MRI towards a challenging task. In this paper, we propose a Dense SegU-net (DSU-net) framework for automatic NPC segmentation in MRI. Our contribution is threefold. First, different from the traditional decoder in U-net using upconvolution for upsamling, we argue that the restoration from low resolution features to high resolution output should be capable of preserving information significant for precise boundary localization. Hence, we use unpooling to unsample and propose SegU-net. Second, to combat the potential vanishing-gradient problem, we introduce dense blocks which can facilitate feature propagation and reuse. Third, using only cross entropy (CE) as loss function may bring about troubles such as miss-prediction, therefore we propose to use a loss function comprised of both CE loss and Dice loss to train the network. Quantitative and qualitative comparisons are carried out extensively on in-house datasets, the experimental results show that our proposed architecture outperforms the existing state-of-the-art segmentation networks.
Recognizing Chinese Judicial Named Entity using BiLSTM-CRF
May 31, 2020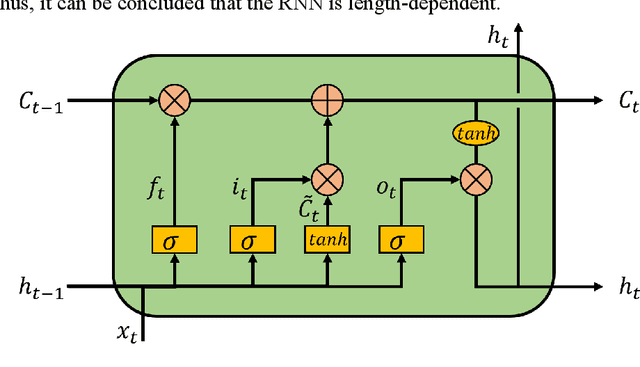
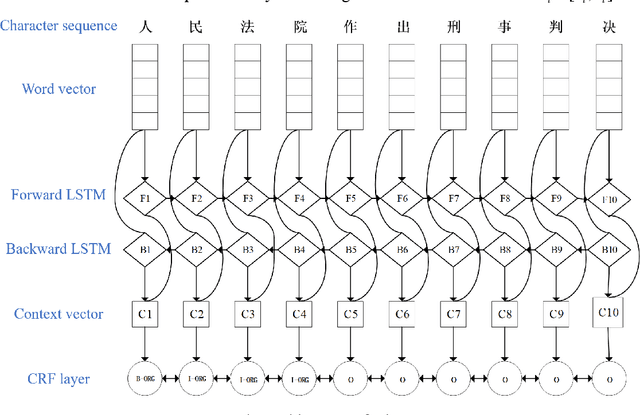

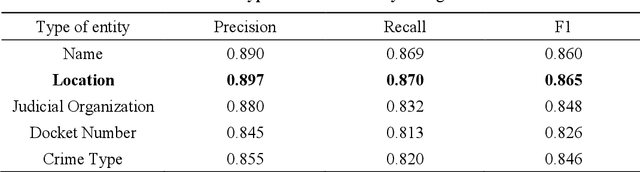
Named entity recognition (NER) plays an essential role in natural language processing systems. Judicial NER is a fundamental component of judicial information retrieval, entity relation extraction, and knowledge map building. However, Chinese judicial NER remains to be more challenging due to the characteristics of Chinese and high accuracy requirements in the judicial filed. Thus, in this paper, we propose a deep learning-based method named BiLSTM-CRF which consists of bi-directional long short-term memory (BiLSTM) and conditional random fields (CRF). For further accuracy promotion, we propose to use Adaptive moment estimation (Adam) for optimization of the model. To validate our method, we perform experiments on judgment documents including commutation, parole and temporary service outside prison, which is acquired from China Judgments Online. Experimental results achieve the accuracy of 0.876, recall of 0.856 and F1 score of 0.855, which suggests the superiority of the proposed BiLSTM-CRF with Adam optimizer.