 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteFusion: Taming 3D Object Detectors from Vision-Based to Multi-Modal with Minimal Adaptation
Dec 23, 20253D object detection is fundamental for safe and robust intelligent transportation systems. Current multi-modal 3D object detectors often rely on complex architectures and training strategies to achieve higher detection accuracy. However, these methods heavily rely on the LiDAR sensor so that they suffer from large performance drops when LiDAR is absent, which compromises the robustness and safety of autonomous systems in practical scenarios. Moreover, existing multi-modal detectors face difficulties in deployment on diverse hardware platforms, such as NPUs and FPGAs, due to their reliance on 3D sparse convolution operators, which are primarily optimized for NVIDIA GPUs. To address these challenges, we reconsider the role of LiDAR in the camera-LiDAR fusion paradigm and introduce a novel multi-modal 3D detector, LiteFusion. Instead of treating LiDAR point clouds as an independent modality with a separate feature extraction backbone, LiteFusion utilizes LiDAR data as a complementary source of geometric information to enhance camera-based detection. This straightforward approach completely eliminates the reliance on a 3D backbone, making the method highly deployment-friendly. Specifically, LiteFusion integrates complementary features from LiDAR points into image features within a quaternion space, where the orthogonal constraints are well-preserved during network training. This helps model domain-specific relations across modalities, yielding a compact cross-modal embedding. Experiments on the nuScenes dataset show that LiteFusion improves the baseline vision-based detector by +20.4% mAP and +19.7% NDS with a minimal increase in parameters (1.1%) without using dedicated LiDAR encoders. Notably, even in the absence of LiDAR input, LiteFusion maintains strong results , highlighting its favorable robustness and effectiveness across diverse fusion paradigms and deployment scenarios.
SparseFormer: Detecting Objects in HRW Shots via Sparse Vision Transformer
Feb 11, 2025Recent years have seen an increase in the use of gigapixel-level image and video capture systems and benchmarks with high-resolution wide (HRW) shots. However, unlike close-up shots in the MS COCO dataset, the higher resolution and wider field of view raise unique challenges, such as extreme sparsity and huge scale changes, causing existing close-up detectors inaccuracy and inefficiency. In this paper, we present a novel model-agnostic sparse vision transformer, dubbed SparseFormer, to bridge the gap of object detection between close-up and HRW shots. The proposed SparseFormer selectively uses attentive tokens to scrutinize the sparsely distributed windows that may contain objects. In this way, it can jointly explore global and local attention by fusing coarse- and fine-grained features to handle huge scale changes. SparseFormer also benefits from a novel Cross-slice non-maximum suppression (C-NMS) algorithm to precisely localize objects from noisy windows and a simple yet effective multi-scale strategy to improve accuracy. Extensive experiments on two HRW benchmarks, PANDA and DOTA-v1.0, demonstrate that the proposed SparseFormer significantly improves detection accuracy (up to 5.8%) and speed (up to 3x) over the state-of-the-art approaches.
VEON: Vocabulary-Enhanced Occupancy Prediction
Jul 17, 2024



Perceiving the world as 3D occupancy supports embodied agents to avoid collision with any types of obstacle. While open-vocabulary image understanding has prospered recently, how to bind the predicted 3D occupancy grids with open-world semantics still remains under-explored due to limited open-world annotations. Hence, instead of building our model from scratch, we try to blend 2D foundation models, specifically a depth model MiDaS and a semantic model CLIP, to lift the semantics to 3D space, thus fulfilling 3D occupancy. However, building upon these foundation models is not trivial. First, the MiDaS faces the depth ambiguity problem, i.e., it only produces relative depth but fails to estimate bin depth for feature lifting. Second, the CLIP image features lack high-resolution pixel-level information, which limits the 3D occupancy accuracy. Third, open vocabulary is often trapped by the long-tail problem. To address these issues, we propose VEON for Vocabulary-Enhanced Occupancy predictioN by not only assembling but also adapting these foundation models. We first equip MiDaS with a Zoedepth head and low-rank adaptation (LoRA) for relative-metric-bin depth transformation while reserving beneficial depth prior. Then, a lightweight side adaptor network is attached to the CLIP vision encoder to generate high-resolution features for fine-grained 3D occupancy prediction. Moreover, we design a class reweighting strategy to give priority to the tail classes. With only 46M trainable parameters and zero manual semantic labels, VEON achieves 15.14 mIoU on Occ3D-nuScenes, and shows the capability of recognizing objects with open-vocabulary categories, meaning that our VEON is label-efficient, parameter-efficient, and precise enough.
OccGen: Generative Multi-modal 3D Occupancy Prediction for Autonomous Driving
Apr 23, 2024



Existing solutions for 3D semantic occupancy prediction typically treat the task as a one-shot 3D voxel-wise segmentation perception problem. These discriminative methods focus on learning the mapping between the inputs and occupancy map in a single step, lacking the ability to gradually refine the occupancy map and the reasonable scene imaginative capacity to complete the local regions somewhere. In this paper, we introduce OccGen, a simple yet powerful generative perception model for the task of 3D semantic occupancy prediction. OccGen adopts a ''noise-to-occupancy'' generative paradigm, progressively inferring and refining the occupancy map by predicting and eliminating noise originating from a random Gaussian distribution. OccGen consists of two main components: a conditional encoder that is capable of processing multi-modal inputs, and a progressive refinement decoder that applies diffusion denoising using the multi-modal features as conditions. A key insight of this generative pipeline is that the diffusion denoising process is naturally able to model the coarse-to-fine refinement of the dense 3D occupancy map, therefore producing more detailed predictions. Extensive experiments on several occupancy benchmarks demonstrate the effectiveness of the proposed method compared to the state-of-the-art methods. For instance, OccGen relatively enhances the mIoU by 9.5%, 6.3%, and 13.3% on nuScenes-Occupancy dataset under the muli-modal, LiDAR-only, and camera-only settings, respectively. Moreover, as a generative perception model, OccGen exhibits desirable properties that discriminative models cannot achieve, such as providing uncertainty estimates alongside its multiple-step predictions.
SparseOcc: Rethinking Sparse Latent Representation for Vision-Based Semantic Occupancy Prediction
Apr 15, 2024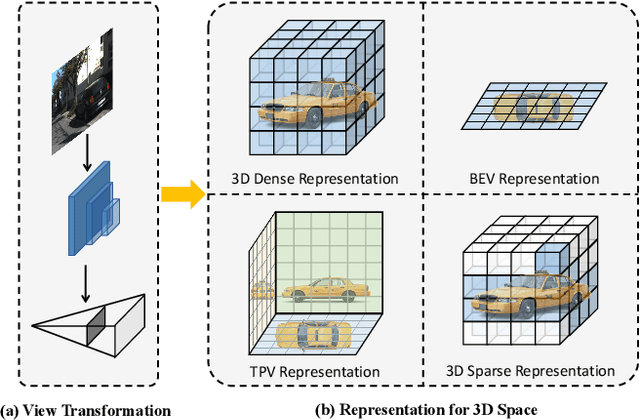
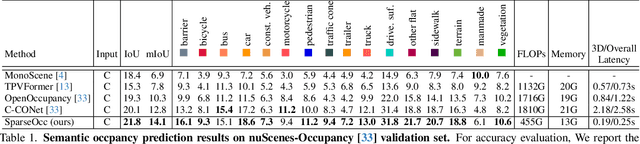
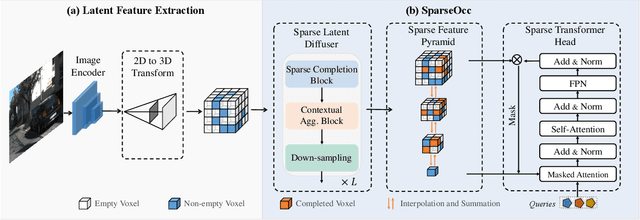
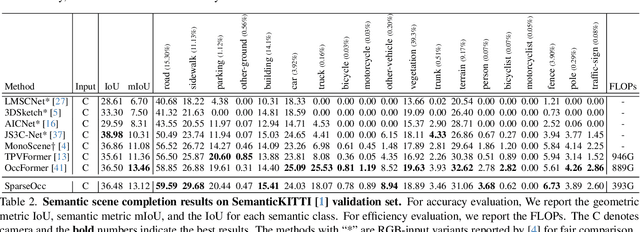
Vision-based perception for autonomous driving requires an explicit modeling of a 3D space, where 2D latent representations are mapped and subsequent 3D operators are applied. However, operating on dense latent spaces introduces a cubic time and space complexity, which limits scalability in terms of perception range or spatial resolution. Existing approaches compress the dense representation using projections like Bird's Eye View (BEV) or Tri-Perspective View (TPV). Although efficient, these projections result in information loss, especially for tasks like semantic occupancy prediction. To address this, we propose SparseOcc, an efficient occupancy network inspired by sparse point cloud processing. It utilizes a lossless sparse latent representation with three key innovations. Firstly, a 3D sparse diffuser performs latent completion using spatially decomposed 3D sparse convolutional kernels. Secondly, a feature pyramid and sparse interpolation enhance scales with information from others. Finally, the transformer head is redesigned as a sparse variant. SparseOcc achieves a remarkable 74.9% reduction on FLOPs over the dense baseline. Interestingly, it also improves accuracy, from 12.8% to 14.1% mIOU, which in part can be attributed to the sparse representation's ability to avoid hallucinations on empty voxels.
* 10 pages, 4 figures, accepted by CVPR 2024
Single-Model and Any-Modality for Video Object Tracking
Nov 27, 2023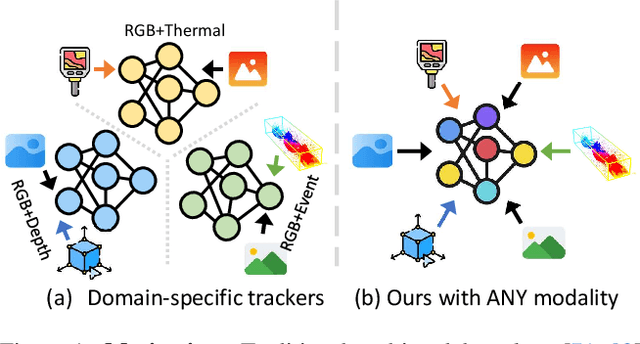

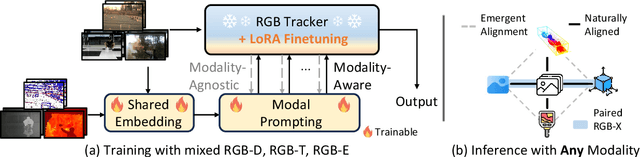

In the realm of video object tracking, auxiliary modalities such as depth, thermal, or event data have emerged as valuable assets to complement the RGB trackers. In practice, most existing RGB trackers learn a single set of parameters to use them across datasets and applications. However, a similar single-model unification for multi-modality tracking presents several challenges. These challenges stem from the inherent heterogeneity of inputs -- each with modality-specific representations, the scarcity of multi-modal datasets, and the absence of all the modalities at all times. In this work, we introduce Un-Track, a \underline{Un}ified Tracker of a single set of parameters for any modality. To handle any modality, our method learns their common latent space through low-rank factorization and reconstruction techniques. More importantly, we use only the RGB-X pairs to learn the common latent space. This unique shared representation seamlessly binds all modalities together, enabling effective unification and accommodating any missing modality, all within a single transformer-based architecture and without the need for modality-specific fine-tuning. Our Un-Track achieves +8.1 absolute F-score gain, on the DepthTrack dataset, by introducing only +2.14 (over 21.50) GFLOPs with +6.6M (over 93M) parameters, through a simple yet efficient prompting strategy. Extensive comparisons on five benchmark datasets with different modalities show that Un-Track surpasses both SOTA unified trackers and modality-specific finetuned counterparts, validating our effectiveness and practicality.
Learning to Track Objects from Unlabeled Videos
Aug 28, 2021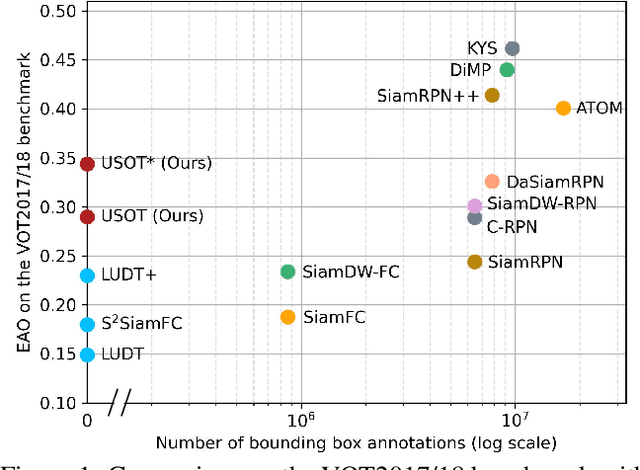
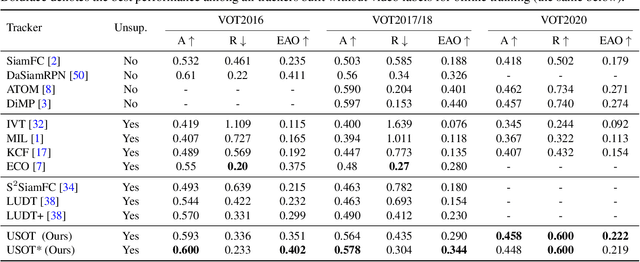

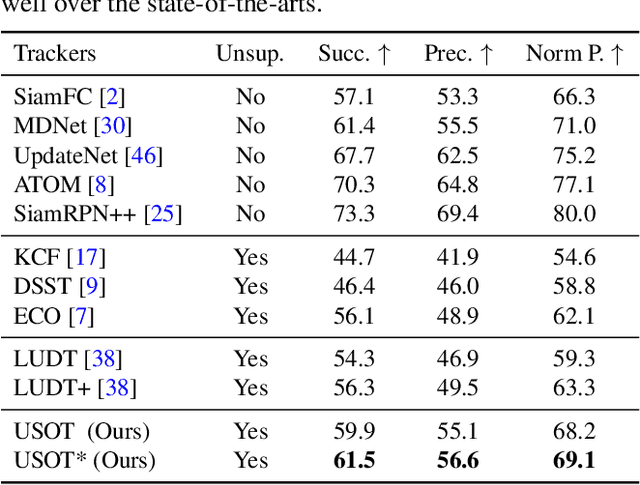
In this paper, we propose to learn an Unsupervised Single Object Tracker (USOT) from scratch. We identify that three major challenges, i.e., moving object discovery, rich temporal variation exploitation, and online update, are the central causes of the performance bottleneck of existing unsupervised trackers. To narrow the gap between unsupervised trackers and supervised counterparts, we propose an effective unsupervised learning approach composed of three stages. First, we sample sequentially moving objects with unsupervised optical flow and dynamic programming, instead of random cropping. Second, we train a naive Siamese tracker from scratch using single-frame pairs. Third, we continue training the tracker with a novel cycle memory learning scheme, which is conducted in longer temporal spans and also enables our tracker to update online. Extensive experiments show that the proposed USOT learned from unlabeled videos performs well over the state-of-the-art unsupervised trackers by large margins, and on par with recent supervised deep trackers. Code is available at https://github.com/VISION-SJTU/USOT.