 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteFusion: Taming 3D Object Detectors from Vision-Based to Multi-Modal with Minimal Adaptation
Dec 23, 20253D object detection is fundamental for safe and robust intelligent transportation systems. Current multi-modal 3D object detectors often rely on complex architectures and training strategies to achieve higher detection accuracy. However, these methods heavily rely on the LiDAR sensor so that they suffer from large performance drops when LiDAR is absent, which compromises the robustness and safety of autonomous systems in practical scenarios. Moreover, existing multi-modal detectors face difficulties in deployment on diverse hardware platforms, such as NPUs and FPGAs, due to their reliance on 3D sparse convolution operators, which are primarily optimized for NVIDIA GPUs. To address these challenges, we reconsider the role of LiDAR in the camera-LiDAR fusion paradigm and introduce a novel multi-modal 3D detector, LiteFusion. Instead of treating LiDAR point clouds as an independent modality with a separate feature extraction backbone, LiteFusion utilizes LiDAR data as a complementary source of geometric information to enhance camera-based detection. This straightforward approach completely eliminates the reliance on a 3D backbone, making the method highly deployment-friendly. Specifically, LiteFusion integrates complementary features from LiDAR points into image features within a quaternion space, where the orthogonal constraints are well-preserved during network training. This helps model domain-specific relations across modalities, yielding a compact cross-modal embedding. Experiments on the nuScenes dataset show that LiteFusion improves the baseline vision-based detector by +20.4% mAP and +19.7% NDS with a minimal increase in parameters (1.1%) without using dedicated LiDAR encoders. Notably, even in the absence of LiDAR input, LiteFusion maintains strong results , highlighting its favorable robustness and effectiveness across diverse fusion paradigms and deployment scenarios.
Grounding Everything in Tokens for Multimodal Large Language Models
Dec 11, 2025Multimodal large language models (MLLMs) have made significant advancements in vision understanding and reasoning. However, the autoregressive Transformer architecture used by MLLMs requries tokenization on input images, which limits their ability to accurately ground objects within the 2D image space. This raises an important question: how can sequential language tokens be improved to better ground objects in 2D spatial space for MLLMs? To address this, we present a spatial representation method for grounding objects, namely GETok, that integrates a specialized vocabulary of learnable tokens into MLLMs. GETok first uses grid tokens to partition the image plane into structured spatial anchors, and then exploits offset tokens to enable precise and iterative refinement of localization predictions. By embedding spatial relationships directly into tokens, GETok significantly advances MLLMs in native 2D space reasoning without modifying the autoregressive architecture. Extensive experiments demonstrate that GETok achieves superior performance over the state-of-the-art methods across various referring tasks in both supervised fine-tuning and reinforcement learning settings.
TGDPO: Harnessing Token-Level Reward Guidance for Enhancing Direct Preference Optimization
Jun 17, 2025Recent advancements in reinforcement learning from human feedback have shown that utilizing fine-grained token-level reward models can substantially enhance the performance of Proximal Policy Optimization (PPO) in aligning large language models. However, it is challenging to leverage such token-level reward as guidance for Direct Preference Optimization (DPO), since DPO is formulated as a sequence-level bandit problem. To address this challenge, this work decomposes the sequence-level PPO into a sequence of token-level proximal policy optimization problems and then frames the problem of token-level PPO with token-level reward guidance, from which closed-form optimal token-level policy and the corresponding token-level reward can be derived. Using the obtained reward and Bradley-Terry model, this work establishes a framework of computable loss functions with token-level reward guidance for DPO, and proposes a practical reward guidance based on the induced DPO reward. This formulation enables different tokens to exhibit varying degrees of deviation from reference policy based on their respective rewards. Experiment results demonstrate that our method achieves substantial performance improvements over DPO, with win rate gains of up to 7.5 points on MT-Bench, 6.2 points on AlpacaEval 2, and 4.3 points on Arena-Hard. Code is available at https://github.com/dvlab-research/TGDPO.
Turbo2K: Towards Ultra-Efficient and High-Quality 2K Video Synthesis
Apr 20, 2025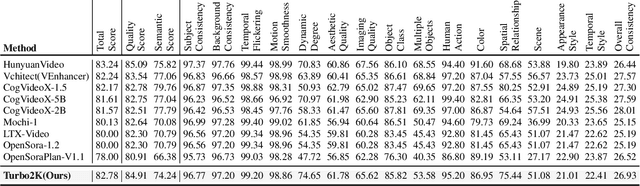

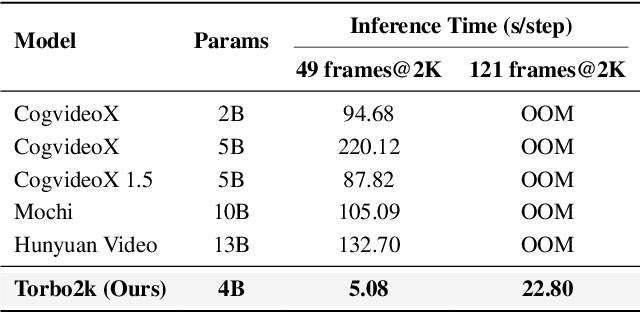

Demand for 2K video synthesis is rising with increasing consumer expectations for ultra-clear visuals. While diffusion transformers (DiTs) have demonstrated remarkable capabilities in high-quality video generation, scaling them to 2K resolution remains computationally prohibitive due to quadratic growth in memory and processing costs. In this work, we propose Turbo2K, an efficient and practical framework for generating detail-rich 2K videos while significantly improving training and inference efficiency. First, Turbo2K operates in a highly compressed latent space, reducing computational complexity and memory footprint, making high-resolution video synthesis feasible. However, the high compression ratio of the VAE and limited model size impose constraints on generative quality. To mitigate this, we introduce a knowledge distillation strategy that enables a smaller student model to inherit the generative capacity of a larger, more powerful teacher model. Our analysis reveals that, despite differences in latent spaces and architectures, DiTs exhibit structural similarities in their internal representations, facilitating effective knowledge transfer. Second, we design a hierarchical two-stage synthesis framework that first generates multi-level feature at lower resolutions before guiding high-resolution video generation. This approach ensures structural coherence and fine-grained detail refinement while eliminating redundant encoding-decoding overhead, further enhancing computational efficiency.Turbo2K achieves state-of-the-art efficiency, generating 5-second, 24fps, 2K videos with significantly reduced computational cost. Compared to existing methods, Turbo2K is up to 20$\times$ faster for inference, making high-resolution video generation more scalable and practical for real-world applications.
Modular Customization of Diffusion Models via Blockwise-Parameterized Low-Rank Adaptation
Mar 11, 2025Recent diffusion model customization has shown impressive results in incorporating subject or style concepts with a handful of images. However, the modular composition of multiple concepts into a customized model, aimed to efficiently merge decentralized-trained concepts without influencing their identities, remains unresolved. Modular customization is essential for applications like concept stylization and multi-concept customization using concepts trained by different users. Existing post-training methods are only confined to a fixed set of concepts, and any different combinations require a new round of retraining. In contrast, instant merging methods often cause identity loss and interference of individual merged concepts and are usually limited to a small number of concepts. To address these issues, we propose BlockLoRA, an instant merging method designed to efficiently combine multiple concepts while accurately preserving individual concepts' identity. With a careful analysis of the underlying reason for interference, we develop the Randomized Output Erasure technique to minimize the interference of different customized models. Additionally, Blockwise LoRA Parameterization is proposed to reduce the identity loss during instant model merging. Extensive experiments validate the effectiveness of BlockLoRA, which can instantly merge 15 concepts of people, subjects, scenes, and styles with high fidelity.
Effective LLM Knowledge Learning via Model Generalization
Mar 05, 2025Large language models (LLMs) are trained on enormous documents that contain extensive world knowledge. However, it is still not well-understood how knowledge is acquired via autoregressive pre-training. This lack of understanding greatly hinders effective knowledge learning, especially for continued pretraining on up-to-date information, as this evolving information often lacks diverse repetitions like foundational knowledge. In this paper, we focus on understanding and improving LLM knowledge learning. We found and verified that knowledge learning for LLMs can be deemed as an implicit supervised task hidden in the autoregressive pre-training objective. Our findings suggest that knowledge learning for LLMs would benefit from methods designed to improve generalization ability for supervised tasks. Based on our analysis, we propose the formatting-based data augmentation to grow in-distribution samples, which does not present the risk of altering the facts embedded in documents as text paraphrasing. We also introduce sharpness-aware minimization as an effective optimization algorithm to better improve generalization. Moreover, our analysis and method can be readily extended to instruction tuning. Extensive experiment results validate our findings and demonstrate our methods' effectiveness in both continued pre-training and instruction tuning. This paper offers new perspectives and insights to interpret and design effective strategies for LLM knowledge learning.
Edit as You See: Image-guided Video Editing via Masked Motion Modeling
Jan 08, 2025Recent advancements in diffusion models have significantly facilitated text-guided video editing. However, there is a relative scarcity of research on image-guided video editing, a method that empowers users to edit videos by merely indicating a target object in the initial frame and providing an RGB image as reference, without relying on the text prompts. In this paper, we propose a novel Image-guided Video Editing Diffusion model, termed IVEDiff for the image-guided video editing. IVEDiff is built on top of image editing models, and is equipped with learnable motion modules to maintain the temporal consistency of edited video. Inspired by self-supervised learning concepts, we introduce a masked motion modeling fine-tuning strategy that empowers the motion module's capabilities for capturing inter-frame motion dynamics, while preserving the capabilities for intra-frame semantic correlations modeling of the base image editing model. Moreover, an optical-flow-guided motion reference network is proposed to ensure the accurate propagation of information between edited video frames, alleviating the misleading effects of invalid information. We also construct a benchmark to facilitate further research. The comprehensive experiments demonstrate that our method is able to generate temporally smooth edited videos while robustly dealing with various editing objects with high quality.
ReNeg: Learning Negative Embedding with Reward Guidance
Dec 27, 2024In text-to-image (T2I) generation applications, negative embeddings have proven to be a simple yet effective approach for enhancing generation quality. Typically, these negative embeddings are derived from user-defined negative prompts, which, while being functional, are not necessarily optimal. In this paper, we introduce ReNeg, an end-to-end method designed to learn improved Negative embeddings guided by a Reward model. We employ a reward feedback learning framework and integrate classifier-free guidance (CFG) into the training process, which was previously utilized only during inference, thus enabling the effective learning of negative embeddings. We also propose two strategies for learning both global and per-sample negative embeddings. Extensive experiments show that the learned negative embedding significantly outperforms null-text and handcrafted counterparts, achieving substantial improvements in human preference alignment. Additionally, the negative embedding learned within the same text embedding space exhibits strong generalization capabilities. For example, using the same CLIP text encoder, the negative embedding learned on SD1.5 can be seamlessly transferred to text-to-image or even text-to-video models such as ControlNet, ZeroScope, and VideoCrafter2, resulting in consistent performance improvements across the board.
Efficient 3D Perception on Multi-Sweep Point Cloud with Gumbel Spatial Pruning
Nov 12, 2024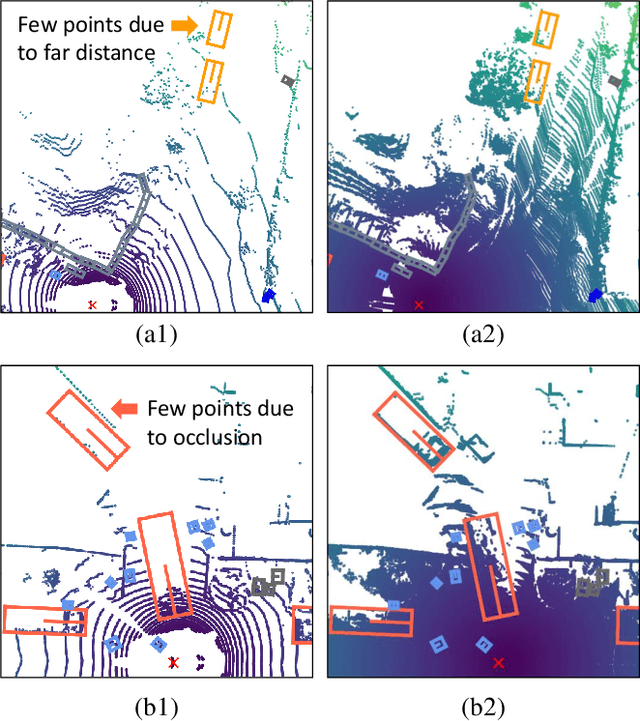
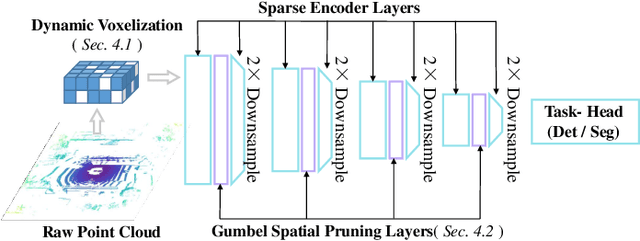
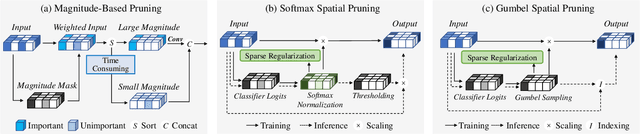
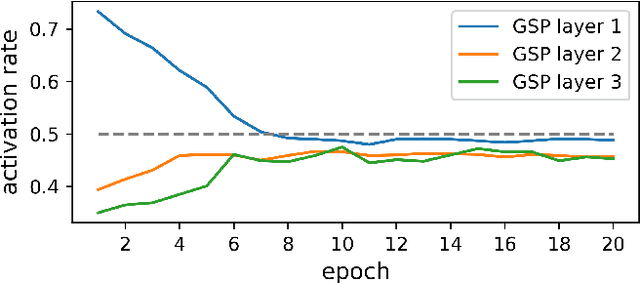
This paper studies point cloud perception within outdoor environments. Existing methods face limitations in recognizing objects located at a distance or occluded, due to the sparse nature of outdoor point clouds. In this work, we observe a significant mitigation of this problem by accumulating multiple temporally consecutive LiDAR sweeps, resulting in a remarkable improvement in perception accuracy. However, the computation cost also increases, hindering previous approaches from utilizing a large number of LiDAR sweeps. To tackle this challenge, we find that a considerable portion of points in the accumulated point cloud is redundant, and discarding these points has minimal impact on perception accuracy. We introduce a simple yet effective Gumbel Spatial Pruning (GSP) layer that dynamically prunes points based on a learned end-to-end sampling. The GSP layer is decoupled from other network components and thus can be seamlessly integrated into existing point cloud network architectures. Without incurring additional computational overhead, we increase the number of LiDAR sweeps from 10, a common practice, to as many as 40. Consequently, there is a significant enhancement in perception performance. For instance, in nuScenes 3D object detection and BEV map segmentation tasks, our pruning strategy improves the vanilla TransL baseline and other baseline methods.
QuadMamba: Learning Quadtree-based Selective Scan for Visual State Space Model
Oct 10, 2024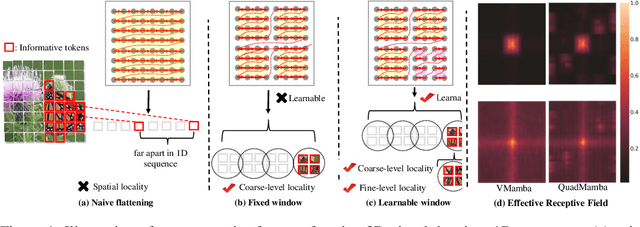
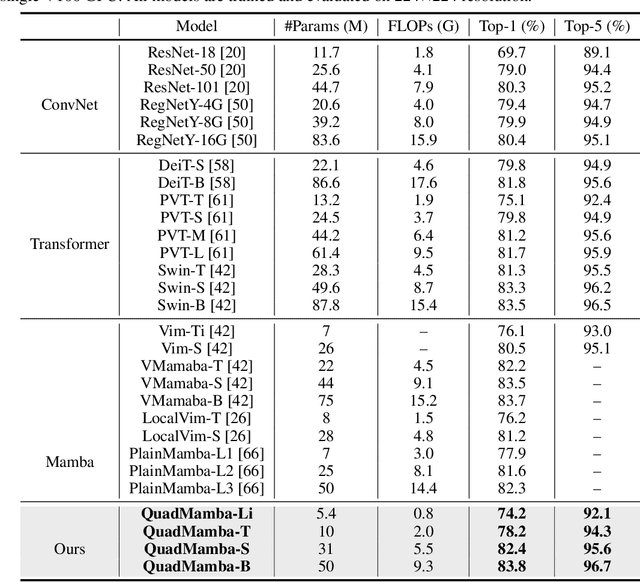
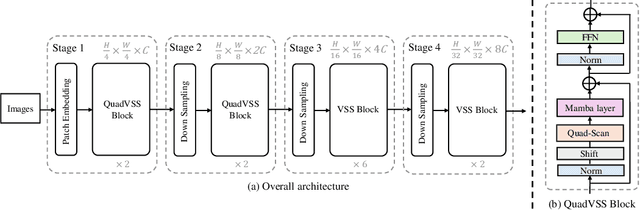
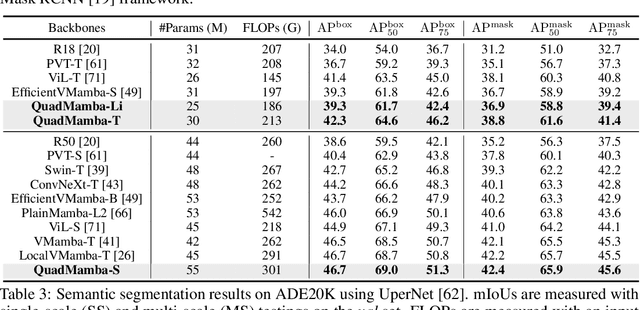
Recent advancements in State Space Models, notably Mamba, have demonstrated superior performance over the dominant Transformer models, particularly in reducing the computational complexity from quadratic to linear. Yet, difficulties in adapting Mamba from language to vision tasks arise due to the distinct characteristics of visual data, such as the spatial locality and adjacency within images and large variations in information granularity across visual tokens. Existing vision Mamba approaches either flatten tokens into sequences in a raster scan fashion, which breaks the local adjacency of images, or manually partition tokens into windows, which limits their long-range modeling and generalization capabilities. To address these limitations, we present a new vision Mamba model, coined QuadMamba, that effectively captures local dependencies of varying granularities via quadtree-based image partition and scan. Concretely, our lightweight quadtree-based scan module learns to preserve the 2D locality of spatial regions within learned window quadrants. The module estimates the locality score of each token from their features, before adaptively partitioning tokens into window quadrants. An omnidirectional window shifting scheme is also introduced to capture more intact and informative features across different local regions. To make the discretized quadtree partition end-to-end trainable, we further devise a sequence masking strategy based on Gumbel-Softmax and its straight-through gradient estimator. Extensive experiments demonstrate that QuadMamba achieves state-of-the-art performance in various vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. The code is in https://github.com/VISION-SJTU/QuadMamba.