 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothSync: Dual-Stream Diffusion Transformers for Jitter-Robust Beat-Synchronized Gesture Generation from Quantized Audio
Jan 04, 2026Co-speech gesture generation is a critical area of research aimed at synthesizing speech-synchronized human-like gestures. Existing methods often suffer from issues such as rhythmic inconsistency, motion jitter, foot sliding and limited multi-sampling diversity. In this paper, we present SmoothSync, a novel framework that leverages quantized audio tokens in a novel dual-stream Diffusion Transformer (DiT) architecture to synthesis holistic gestures and enhance sampling variation. Specifically, we (1) fuse audio-motion features via complementary transformer streams to achieve superior synchronization, (2) introduce a jitter-suppression loss to improve temporal smoothness, (3) implement probabilistic audio quantization to generate distinct gesture sequences from identical inputs. To reliably evaluate beat synchronization under jitter, we introduce Smooth-BC, a robust variant of the beat consistency metric less sensitive to motion noise. Comprehensive experiments on the BEAT2 and SHOW datasets demonstrate SmoothSync's superiority, outperforming state-of-the-art methods by -30.6% FGD, 10.3% Smooth-BC, and 8.4% Diversity on BEAT2, while reducing jitter and foot sliding by -62.9% and -17.1% respectively. The code will be released to facilitate future research.
Learning When to Look: A Disentangled Curriculum for Strategic Perception in Multimodal Reasoning
Dec 19, 2025Multimodal Large Language Models (MLLMs) demonstrate significant potential but remain brittle in complex, long-chain visual reasoning tasks. A critical failure mode is "visual forgetting", where models progressively lose visual grounding as reasoning extends, a phenomenon aptly described as "think longer, see less". We posit this failure stems from current training paradigms prematurely entangling two distinct cognitive skills: (1) abstract logical reasoning "how-to-think") and (2) strategic visual perception ("when-to-look"). This creates a foundational cold-start deficiency -- weakening abstract reasoning -- and a strategic perception deficit, as models lack a policy for when to perceive. In this paper, we propose a novel curriculum-based framework to disentangle these skills. First, we introduce a disentangled Supervised Fine-Tuning (SFT) curriculum that builds a robust abstract reasoning backbone on text-only data before anchoring it to vision with a novel Perception-Grounded Chain-of-Thought (PG-CoT) paradigm. Second, we resolve the strategic perception deficit by formulating timing as a reinforcement learning problem. We design a Pivotal Perception Reward that teaches the model when to look by coupling perceptual actions to linguistic markers of cognitive uncertainty (e.g., "wait", "verify"), thereby learning an autonomous grounding policy. Our contributions include the formalization of these two deficiencies and the development of a principled, two-stage framework to address them, transforming the model from a heuristic-driven observer to a strategic, grounded reasoner. \textbf{Code}: \url{https://github.com/gaozilve-max/learning-when-to-look}.
AgentExpt: Automating AI Experiment Design with LLM-based Resource Retrieval Agent
Nov 07, 2025

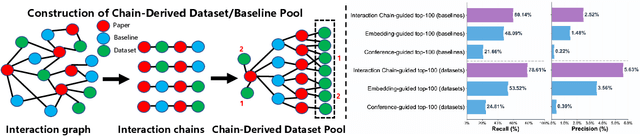
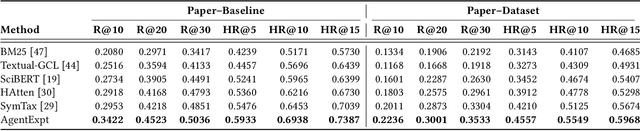
Large language model agents are becoming increasingly capable at web-centric tasks such as information retrieval, complex reasoning. These emerging capabilities have given rise to surge research interests in developing LLM agent for facilitating scientific quest. One key application in AI research is to automate experiment design through agentic dataset and baseline retrieval. However, prior efforts suffer from limited data coverage, as recommendation datasets primarily harvest candidates from public portals and omit many datasets actually used in published papers, and from an overreliance on content similarity that biases model toward superficial similarity and overlooks experimental suitability. Harnessing collective perception embedded in the baseline and dataset citation network, we present a comprehensive framework for baseline and dataset recommendation. First, we design an automated data-collection pipeline that links roughly one hundred thousand accepted papers to the baselines and datasets they actually used. Second, we propose a collective perception enhanced retriever. To represent the position of each dataset or baseline within the scholarly network, it concatenates self-descriptions with aggregated citation contexts. To achieve efficient candidate recall, we finetune an embedding model on these representations. Finally, we develop a reasoning-augmented reranker that exact interaction chains to construct explicit reasoning chains and finetunes a large language model to produce interpretable justifications and refined rankings. The dataset we curated covers 85\% of the datasets and baselines used at top AI conferences over the past five years. On our dataset, the proposed method outperforms the strongest prior baseline with average gains of +5.85\% in Recall@20, +8.30\% in HitRate@5. Taken together, our results advance reliable, interpretable automation of experimental design.
Large Material Gaussian Model for Relightable 3D Generation
Sep 26, 2025
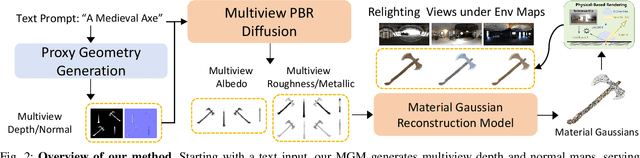
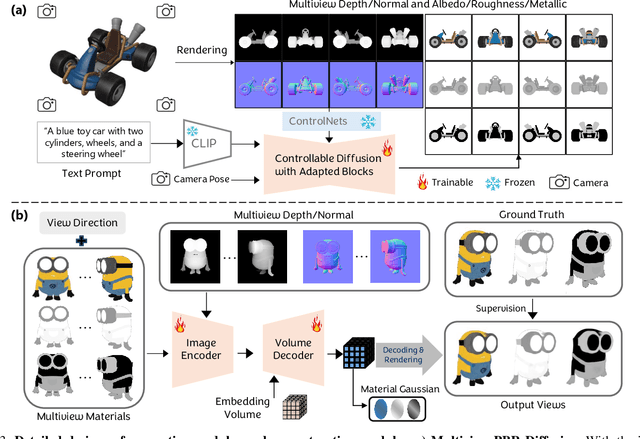

The increasing demand for 3D assets across various industries necessitates efficient and automated methods for 3D content creation. Leveraging 3D Gaussian Splatting, recent large reconstruction models (LRMs) have demonstrated the ability to efficiently achieve high-quality 3D rendering by integrating multiview diffusion for generation and scalable transformers for reconstruction. However, existing models fail to produce the material properties of assets, which is crucial for realistic rendering in diverse lighting environments. In this paper, we introduce the Large Material Gaussian Model (MGM), a novel framework designed to generate high-quality 3D content with Physically Based Rendering (PBR) materials, ie, albedo, roughness, and metallic properties, rather than merely producing RGB textures with uncontrolled light baking. Specifically, we first fine-tune a new multiview material diffusion model conditioned on input depth and normal maps. Utilizing the generated multiview PBR images, we explore a Gaussian material representation that not only aligns with 2D Gaussian Splatting but also models each channel of the PBR materials. The reconstructed point clouds can then be rendered to acquire PBR attributes, enabling dynamic relighting by applying various ambient light maps. Extensive experiments demonstrate that the materials produced by our method not only exhibit greater visual appeal compared to baseline methods but also enhance material modeling, thereby enabling practical downstream rendering applications.
AgentSwift: Efficient LLM Agent Design via Value-guided Hierarchical Search
Jun 06, 2025Large language model (LLM) agents have demonstrated strong capabilities across diverse domains. However, designing high-performing agentic systems remains challenging. Existing agent search methods suffer from three major limitations: (1) an emphasis on optimizing agentic workflows while under-utilizing proven human-designed components such as memory, planning, and tool use; (2) high evaluation costs, as each newly generated agent must be fully evaluated on benchmarks; and (3) inefficient search in large search space. In this work, we introduce a comprehensive framework to address these challenges. First, We propose a hierarchical search space that jointly models agentic workflow and composable functional components, enabling richer agentic system designs. Building on this structured design space, we introduce a predictive value model that estimates agent performance given agentic system and task description, allowing for efficient, low-cost evaluation during the search process. Finally, we present a hierarchical Monte Carlo Tree Search (MCTS) strategy informed by uncertainty to guide the search. Experiments on seven benchmarks, covering embodied, math, web, tool, and game, show that our method achieves an average performance gain of 8.34\% over state-of-the-art baselines and exhibits faster search progress with steeper improvement trajectories. Code repo is available at https://github.com/Ericccc02/AgentSwift.
TACO: Think-Answer Consistency for Optimized Long-Chain Reasoning and Efficient Data Learning via Reinforcement Learning in LVLMs
May 27, 2025DeepSeek R1 has significantly advanced complex reasoning for large language models (LLMs). While recent methods have attempted to replicate R1's reasoning capabilities in multimodal settings, they face limitations, including inconsistencies between reasoning and final answers, model instability and crashes during long-chain exploration, and low data learning efficiency. To address these challenges, we propose TACO, a novel reinforcement learning algorithm for visual reasoning. Building on Generalized Reinforcement Policy Optimization (GRPO), TACO introduces Think-Answer Consistency, which tightly couples reasoning with answer consistency to ensure answers are grounded in thoughtful reasoning. We also introduce the Rollback Resample Strategy, which adaptively removes problematic samples and reintroduces them to the sampler, enabling stable long-chain exploration and future learning opportunities. Additionally, TACO employs an adaptive learning schedule that focuses on moderate difficulty samples to optimize data efficiency. Furthermore, we propose the Test-Time-Resolution-Scaling scheme to address performance degradation due to varying resolutions during reasoning while balancing computational overhead. Extensive experiments on in-distribution and out-of-distribution benchmarks for REC and VQA tasks show that fine-tuning LVLMs leads to significant performance improvements.
What Can RL Bring to VLA Generalization? An Empirical Study
May 26, 2025Large Vision-Language Action (VLA) models have shown significant potential for embodied AI. However, their predominant training via supervised fine-tuning (SFT) limits generalization due to susceptibility to compounding errors under distribution shifts. Reinforcement learning (RL) offers a path to overcome these limitations by optimizing for task objectives via trial-and-error, yet a systematic understanding of its specific generalization benefits for VLAs compared to SFT is lacking. To address this, our study introduces a comprehensive benchmark for evaluating VLA generalization and systematically investigates the impact of RL fine-tuning across diverse visual, semantic, and execution dimensions. Our extensive experiments reveal that RL fine-tuning, particularly with PPO, significantly enhances generalization in semantic understanding and execution robustness over SFT, while maintaining comparable visual robustness. We identify PPO as a more effective RL algorithm for VLAs than LLM-derived methods like DPO and GRPO. We also develop a simple recipe for efficient PPO training on VLAs, and demonstrate its practical utility for improving VLA generalization. The project page is at https://rlvla.github.io
Multiple Weaks Win Single Strong: Large Language Models Ensemble Weak Reinforcement Learning Agents into a Supreme One
May 21, 2025Model ensemble is a useful approach in reinforcement learning (RL) for training effective agents. Despite wide success of RL, training effective agents remains difficult due to the multitude of factors requiring careful tuning, such as algorithm selection, hyperparameter settings, and even random seed choices, all of which can significantly influence an agent's performance. Model ensemble helps overcome this challenge by combining multiple weak agents into a single, more powerful one, enhancing overall performance. However, existing ensemble methods, such as majority voting and Boltzmann addition, are designed as fixed strategies and lack a semantic understanding of specific tasks, limiting their adaptability and effectiveness. To address this, we propose LLM-Ens, a novel approach that enhances RL model ensemble with task-specific semantic understandings driven by large language models (LLMs). Given a task, we first design an LLM to categorize states in this task into distinct 'situations', incorporating high-level descriptions of the task conditions. Then, we statistically analyze the strengths and weaknesses of each individual agent to be used in the ensemble in each situation. During the inference time, LLM-Ens dynamically identifies the changing task situation and switches to the agent that performs best in the current situation, ensuring dynamic model selection in the evolving task condition. Our approach is designed to be compatible with agents trained with different random seeds, hyperparameter settings, and various RL algorithms. Extensive experiments on the Atari benchmark show that LLM-Ens significantly improves the RL model ensemble, surpassing well-known baselines by up to 20.9%. For reproducibility, our code is open-source at https://anonymous.4open.science/r/LLM4RLensemble-F7EE.
LLM-Explorer: A Plug-in Reinforcement Learning Policy Exploration Enhancement Driven by Large Language Models
May 21, 2025Policy exploration is critical in reinforcement learning (RL), where existing approaches include greedy, Gaussian process, etc. However, these approaches utilize preset stochastic processes and are indiscriminately applied in all kinds of RL tasks without considering task-specific features that influence policy exploration. Moreover, during RL training, the evolution of such stochastic processes is rigid, which typically only incorporates a decay in the variance, failing to adjust flexibly according to the agent's real-time learning status. Inspired by the analyzing and reasoning capability of large language models (LLMs), we design LLM-Explorer to adaptively generate task-specific exploration strategies with LLMs, enhancing the policy exploration in RL. In our design, we sample the learning trajectory of the agent during the RL training in a given task and prompt the LLM to analyze the agent's current policy learning status and then generate a probability distribution for future policy exploration. Updating the probability distribution periodically, we derive a stochastic process specialized for the particular task and dynamically adjusted to adapt to the learning process. Our design is a plug-in module compatible with various widely applied RL algorithms, including the DQN series, DDPG, TD3, and any possible variants developed based on them. Through extensive experiments on the Atari and MuJoCo benchmarks, we demonstrate LLM-Explorer's capability to enhance RL policy exploration, achieving an average performance improvement up to 37.27%. Our code is open-source at https://anonymous.4open.science/r/LLM-Explorer-19BE for reproducibility.
UP-Person: Unified Parameter-Efficient Transfer Learning for Text-based Person Retrieval
Apr 14, 2025Text-based Person Retrieval (TPR) as a multi-modal task, which aims to retrieve the target person from a pool of candidate images given a text description, has recently garnered considerable attention due to the progress of contrastive visual-language pre-trained model. Prior works leverage pre-trained CLIP to extract person visual and textual features and fully fine-tune the entire network, which have shown notable performance improvements compared to uni-modal pre-training models. However, full-tuning a large model is prone to overfitting and hinders the generalization ability. In this paper, we propose a novel Unified Parameter-Efficient Transfer Learning (PETL) method for Text-based Person Retrieval (UP-Person) to thoroughly transfer the multi-modal knowledge from CLIP. Specifically, UP-Person simultaneously integrates three lightweight PETL components including Prefix, LoRA and Adapter, where Prefix and LoRA are devised together to mine local information with task-specific information prompts, and Adapter is designed to adjust global feature representations. Additionally, two vanilla submodules are optimized to adapt to the unified architecture of TPR. For one thing, S-Prefix is proposed to boost attention of prefix and enhance the gradient propagation of prefix tokens, which improves the flexibility and performance of the vanilla prefix. For another thing, L-Adapter is designed in parallel with layer normalization to adjust the overall distribution, which can resolve conflicts caused by overlap and interaction among multiple submodules. Extensive experimental results demonstrate that our UP-Person achieves state-of-the-art results across various person retrieval datasets, including CUHK-PEDES, ICFG-PEDES and RSTPReid while merely fine-tuning 4.7\% parameters. Code is available at https://github.com/Liu-Yating/UP-Person.