 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Material Gaussian Model for Relightable 3D Generation
Sep 26, 2025
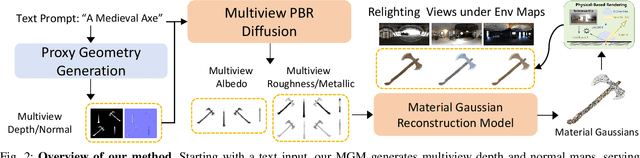
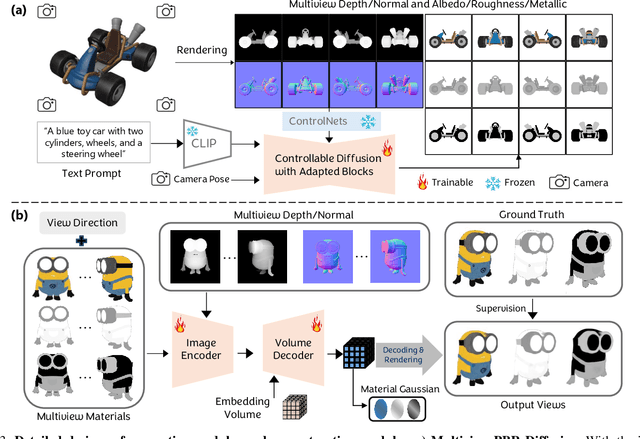

The increasing demand for 3D assets across various industries necessitates efficient and automated methods for 3D content creation. Leveraging 3D Gaussian Splatting, recent large reconstruction models (LRMs) have demonstrated the ability to efficiently achieve high-quality 3D rendering by integrating multiview diffusion for generation and scalable transformers for reconstruction. However, existing models fail to produce the material properties of assets, which is crucial for realistic rendering in diverse lighting environments. In this paper, we introduce the Large Material Gaussian Model (MGM), a novel framework designed to generate high-quality 3D content with Physically Based Rendering (PBR) materials, ie, albedo, roughness, and metallic properties, rather than merely producing RGB textures with uncontrolled light baking. Specifically, we first fine-tune a new multiview material diffusion model conditioned on input depth and normal maps. Utilizing the generated multiview PBR images, we explore a Gaussian material representation that not only aligns with 2D Gaussian Splatting but also models each channel of the PBR materials. The reconstructed point clouds can then be rendered to acquire PBR attributes, enabling dynamic relighting by applying various ambient light maps. Extensive experiments demonstrate that the materials produced by our method not only exhibit greater visual appeal compared to baseline methods but also enhance material modeling, thereby enabling practical downstream rendering applications.
WarpAdam: A new Adam optimizer based on Meta-Learning approach
Sep 06, 2024Optimal selection of optimization algorithms is crucial for training deep learning models. The Adam optimizer has gained significant attention due to its efficiency and wide applicability. However, to enhance the adaptability of optimizers across diverse datasets, we propose an innovative optimization strategy by integrating the 'warped gradient descend'concept from Meta Learning into the Adam optimizer. In the conventional Adam optimizer, gradients are utilized to compute estimates of gradient mean and variance, subsequently updating model parameters. Our approach introduces a learnable distortion matrix, denoted as P, which is employed for linearly transforming gradients. This transformation slightly adjusts gradients during each iteration, enabling the optimizer to better adapt to distinct dataset characteristics. By learning an appropriate distortion matrix P, our method aims to adaptively adjust gradient information across different data distributions, thereby enhancing optimization performance. Our research showcases the potential of this novel approach through theoretical insights and empirical evaluations. Experimental results across various tasks and datasets validate the superiority of our optimizer that integrates the 'warped gradient descend' concept in terms of adaptability. Furthermore, we explore effective strategies for training the adaptation matrix P and identify scenarios where this method can yield optimal results. In summary, this study introduces an innovative approach that merges the 'warped gradient descend' concept from Meta Learning with the Adam optimizer. By introducing a learnable distortion matrix P within the optimizer, we aim to enhance the model's generalization capability across diverse data distributions, thus opening up new possibilities in the field of deep learning optimization.
SMPLX-Lite: A Realistic and Drivable Avatar Benchmark with Rich Geometry and Texture Annotations
May 30, 2024



Recovering photorealistic and drivable full-body avatars is crucial for numerous applications, including virtual reality, 3D games, and tele-presence. Most methods, whether reconstruction or generation, require large numbers of human motion sequences and corresponding textured meshes. To easily learn a drivable avatar, a reasonable parametric body model with unified topology is paramount. However, existing human body datasets either have images or textured models and lack parametric models which fit clothes well. We propose a new parametric model SMPLX-Lite-D, which can fit detailed geometry of the scanned mesh while maintaining stable geometry in the face, hand and foot regions. We present SMPLX-Lite dataset, the most comprehensive clothing avatar dataset with multi-view RGB sequences, keypoints annotations, textured scanned meshes, and textured SMPLX-Lite-D models. With the SMPLX-Lite dataset, we train a conditional variational autoencoder model that takes human pose and facial keypoints as input, and generates a photorealistic drivable human avatar.
OccGaussian: 3D Gaussian Splatting for Occluded Human Rendering
Apr 15, 2024Rendering dynamic 3D human from monocular videos is crucial for various applications such as virtual reality and digital entertainment. Most methods assume the people is in an unobstructed scene, while various objects may cause the occlusion of body parts in real-life scenarios. Previous method utilizing NeRF for surface rendering to recover the occluded areas, but it requiring more than one day to train and several seconds to render, failing to meet the requirements of real-time interactive applications. To address these issues, we propose OccGaussian based on 3D Gaussian Splatting, which can be trained within 6 minutes and produces high-quality human renderings up to 160 FPS with occluded input. OccGaussian initializes 3D Gaussian distributions in the canonical space, and we perform occlusion feature query at occluded regions, the aggregated pixel-align feature is extracted to compensate for the missing information. Then we use Gaussian Feature MLP to further process the feature along with the occlusion-aware loss functions to better perceive the occluded area. Extensive experiments both in simulated and real-world occlusions, demonstrate that our method achieves comparable or even superior performance compared to the state-of-the-art method. And we improving training and inference speeds by 250x and 800x, respectively. Our code will be available for research purposes.