 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
Towards 3D Object-Centric Feature Learning for Semantic Scene Completion
Nov 18, 2025Vision-based 3D Semantic Scene Completion (SSC) has received growing attention due to its potential in autonomous driving. While most existing approaches follow an ego-centric paradigm by aggregating and diffusing features over the entire scene, they often overlook fine-grained object-level details, leading to semantic and geometric ambiguities, especially in complex environments. To address this limitation, we propose Ocean, an object-centric prediction framework that decomposes the scene into individual object instances to enable more accurate semantic occupancy prediction. Specifically, we first employ a lightweight segmentation model, MobileSAM, to extract instance masks from the input image. Then, we introduce a 3D Semantic Group Attention module that leverages linear attention to aggregate object-centric features in 3D space. To handle segmentation errors and missing instances, we further design a Global Similarity-Guided Attention module that leverages segmentation features for global interaction. Finally, we propose an Instance-aware Local Diffusion module that improves instance features through a generative process and subsequently refines the scene representation in the BEV space. Extensive experiments on the SemanticKITTI and SSCBench-KITTI360 benchmarks demonstrate that Ocean achieves state-of-the-art performance, with mIoU scores of 17.40 and 20.28, respectively.
SMPLX-Lite: A Realistic and Drivable Avatar Benchmark with Rich Geometry and Texture Annotations
May 30, 2024



Recovering photorealistic and drivable full-body avatars is crucial for numerous applications, including virtual reality, 3D games, and tele-presence. Most methods, whether reconstruction or generation, require large numbers of human motion sequences and corresponding textured meshes. To easily learn a drivable avatar, a reasonable parametric body model with unified topology is paramount. However, existing human body datasets either have images or textured models and lack parametric models which fit clothes well. We propose a new parametric model SMPLX-Lite-D, which can fit detailed geometry of the scanned mesh while maintaining stable geometry in the face, hand and foot regions. We present SMPLX-Lite dataset, the most comprehensive clothing avatar dataset with multi-view RGB sequences, keypoints annotations, textured scanned meshes, and textured SMPLX-Lite-D models. With the SMPLX-Lite dataset, we train a conditional variational autoencoder model that takes human pose and facial keypoints as input, and generates a photorealistic drivable human avatar.
Decoupled Pseudo-labeling for Semi-Supervised Monocular 3D Object Detection
Mar 26, 2024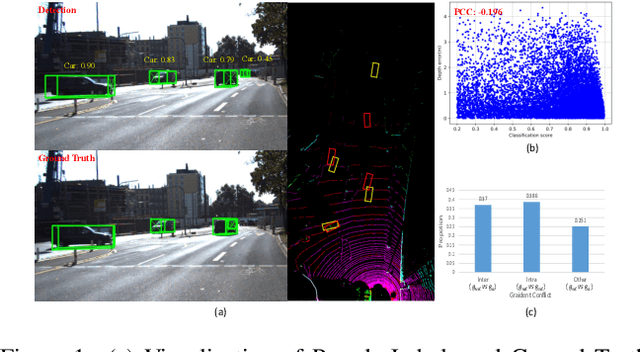
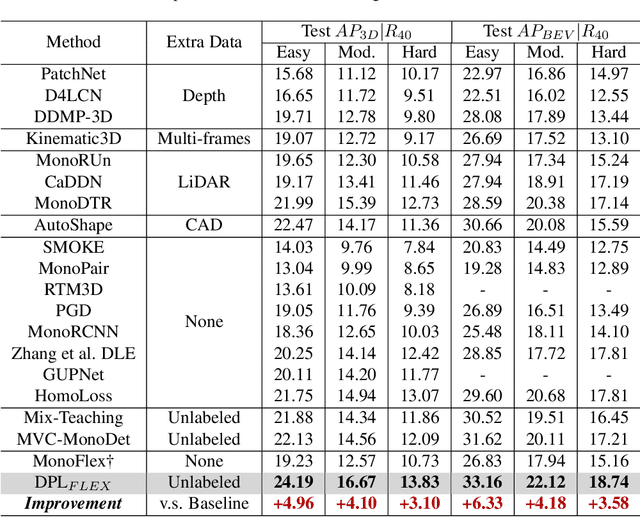
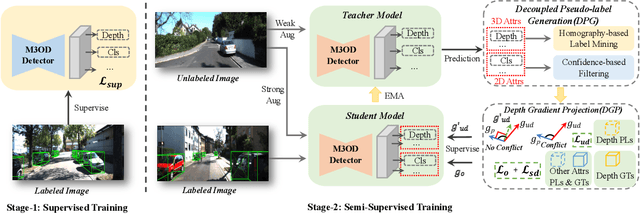

We delve into pseudo-labeling for semi-supervised monocular 3D object detection (SSM3OD) and discover two primary issues: a misalignment between the prediction quality of 3D and 2D attributes and the tendency of depth supervision derived from pseudo-labels to be noisy, leading to significant optimization conflicts with other reliable forms of supervision. We introduce a novel decoupled pseudo-labeling (DPL) approach for SSM3OD. Our approach features a Decoupled Pseudo-label Generation (DPG) module, designed to efficiently generate pseudo-labels by separately processing 2D and 3D attributes. This module incorporates a unique homography-based method for identifying dependable pseudo-labels in BEV space, specifically for 3D attributes. Additionally, we present a DepthGradient Projection (DGP) module to mitigate optimization conflicts caused by noisy depth supervision of pseudo-labels, effectively decoupling the depth gradient and removing conflicting gradients. This dual decoupling strategy-at both the pseudo-label generation and gradient levels-significantly improves the utilization of pseudo-labels in SSM3OD. Our comprehensive experiments on the KITTI benchmark demonstrate the superiority of our method over existing approaches.
Gradient-based Sampling for Class Imbalanced Semi-supervised Object Detection
Mar 22, 2024



Current semi-supervised object detection (SSOD) algorithms typically assume class balanced datasets (PASCAL VOC etc.) or slightly class imbalanced datasets (MS-COCO, etc). This assumption can be easily violated since real world datasets can be extremely class imbalanced in nature, thus making the performance of semi-supervised object detectors far from satisfactory. Besides, the research for this problem in SSOD is severely under-explored. To bridge this research gap, we comprehensively study the class imbalance problem for SSOD under more challenging scenarios, thus forming the first experimental setting for class imbalanced SSOD (CI-SSOD). Moreover, we propose a simple yet effective gradient-based sampling framework that tackles the class imbalance problem from the perspective of two types of confirmation biases. To tackle confirmation bias towards majority classes, the gradient-based reweighting and gradient-based thresholding modules leverage the gradients from each class to fully balance the influence of the majority and minority classes. To tackle the confirmation bias from incorrect pseudo labels of minority classes, the class-rebalancing sampling module resamples unlabeled data following the guidance of the gradient-based reweighting module. Experiments on three proposed sub-tasks, namely MS-COCO, MS-COCO to Object365 and LVIS, suggest that our method outperforms current class imbalanced object detectors by clear margins, serving as a baseline for future research in CI-SSOD. Code will be available at https://github.com/nightkeepers/CI-SSOD.
SplattingAvatar: Realistic Real-Time Human Avatars with Mesh-Embedded Gaussian Splatting
Mar 08, 2024We present SplattingAvatar, a hybrid 3D representation of photorealistic human avatars with Gaussian Splatting embedded on a triangle mesh, which renders over 300 FPS on a modern GPU and 30 FPS on a mobile device. We disentangle the motion and appearance of a virtual human with explicit mesh geometry and implicit appearance modeling with Gaussian Splatting. The Gaussians are defined by barycentric coordinates and displacement on a triangle mesh as Phong surfaces. We extend lifted optimization to simultaneously optimize the parameters of the Gaussians while walking on the triangle mesh. SplattingAvatar is a hybrid representation of virtual humans where the mesh represents low-frequency motion and surface deformation, while the Gaussians take over the high-frequency geometry and detailed appearance. Unlike existing deformation methods that rely on an MLP-based linear blend skinning (LBS) field for motion, we control the rotation and translation of the Gaussians directly by mesh, which empowers its compatibility with various animation techniques, e.g., skeletal animation, blend shapes, and mesh editing. Trainable from monocular videos for both full-body and head avatars, SplattingAvatar shows state-of-the-art rendering quality across multiple datasets.
Semi-DETR: Semi-Supervised Object Detection with Detection Transformers
Jul 16, 2023



We analyze the DETR-based framework on semi-supervised object detection (SSOD) and observe that (1) the one-to-one assignment strategy generates incorrect matching when the pseudo ground-truth bounding box is inaccurate, leading to training inefficiency; (2) DETR-based detectors lack deterministic correspondence between the input query and its prediction output, which hinders the applicability of the consistency-based regularization widely used in current SSOD methods. We present Semi-DETR, the first transformer-based end-to-end semi-supervised object detector, to tackle these problems. Specifically, we propose a Stage-wise Hybrid Matching strategy that combines the one-to-many assignment and one-to-one assignment strategies to improve the training efficiency of the first stage and thus provide high-quality pseudo labels for the training of the second stage. Besides, we introduce a Crossview Query Consistency method to learn the semantic feature invariance of object queries from different views while avoiding the need to find deterministic query correspondence. Furthermore, we propose a Cost-based Pseudo Label Mining module to dynamically mine more pseudo boxes based on the matching cost of pseudo ground truth bounding boxes for consistency training. Extensive experiments on all SSOD settings of both COCO and Pascal VOC benchmark datasets show that our Semi-DETR method outperforms all state-of-the-art methods by clear margins. The PaddlePaddle version code1 is at https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/semi_det/semi_detr.
Ambiguity-Resistant Semi-Supervised Learning for Dense Object Detection
Mar 27, 2023



With basic Semi-Supervised Object Detection (SSOD) techniques, one-stage detectors generally obtain limited promotions compared with two-stage clusters. We experimentally find that the root lies in two kinds of ambiguities: (1) Selection ambiguity that selected pseudo labels are less accurate, since classification scores cannot properly represent the localization quality. (2) Assignment ambiguity that samples are matched with improper labels in pseudo-label assignment, as the strategy is misguided by missed objects and inaccurate pseudo boxes. To tackle these problems, we propose a Ambiguity-Resistant Semi-supervised Learning (ARSL) for one-stage detectors. Specifically, to alleviate the selection ambiguity, Joint-Confidence Estimation (JCE) is proposed to jointly quantifies the classification and localization quality of pseudo labels. As for the assignment ambiguity, Task-Separation Assignment (TSA) is introduced to assign labels based on pixel-level predictions rather than unreliable pseudo boxes. It employs a "divide-and-conquer" strategy and separately exploits positives for the classification and localization task, which is more robust to the assignment ambiguity. Comprehensive experiments demonstrate that ARSL effectively mitigates the ambiguities and achieves state-of-the-art SSOD performance on MS COCO and PASCAL VOC. Codes can be found at https://github.com/PaddlePaddle/PaddleDetection.
I2F: A Unified Image-to-Feature Approach for Domain Adaptive Semantic Segmentation
Jan 03, 2023



Unsupervised domain adaptation (UDA) for semantic segmentation is a promising task freeing people from heavy annotation work. However, domain discrepancies in low-level image statistics and high-level contexts compromise the segmentation performance over the target domain. A key idea to tackle this problem is to perform both image-level and feature-level adaptation jointly. Unfortunately, there is a lack of such unified approaches for UDA tasks in the existing literature. This paper proposes a novel UDA pipeline for semantic segmentation that unifies image-level and feature-level adaptation. Concretely, for image-level domain shifts, we propose a global photometric alignment module and a global texture alignment module that align images in the source and target domains in terms of image-level properties. For feature-level domain shifts, we perform global manifold alignment by projecting pixel features from both domains onto the feature manifold of the source domain; and we further regularize category centers in the source domain through a category-oriented triplet loss and perform target domain consistency regularization over augmented target domain images. Experimental results demonstrate that our pipeline significantly outperforms previous methods. In the commonly tested GTA5$\rightarrow$Cityscapes task, our proposed method using Deeplab V3+ as the backbone surpasses previous SOTA by 8%, achieving 58.2% in mIoU.
Coarse-to-Fine Domain Adaptive Semantic Segmentation with Photometric Alignment and Category-Center Regularization
Mar 24, 2021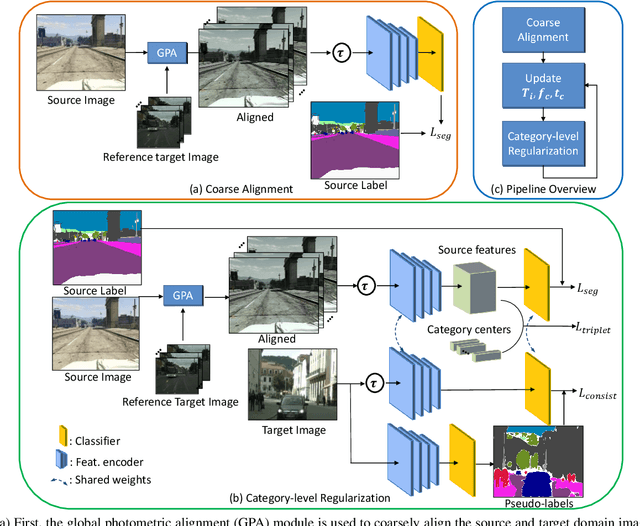
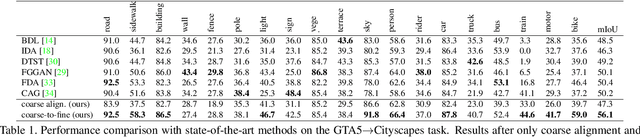
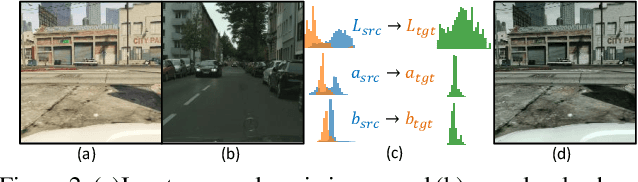
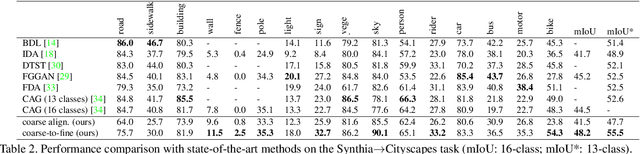
Unsupervised domain adaptation (UDA) in semantic segmentation is a fundamental yet promising task relieving the need for laborious annotation works. However, the domain shifts/discrepancies problem in this task compromise the final segmentation performance. Based on our observation, the main causes of the domain shifts are differences in imaging conditions, called image-level domain shifts, and differences in object category configurations called category-level domain shifts. In this paper, we propose a novel UDA pipeline that unifies image-level alignment and category-level feature distribution regularization in a coarse-to-fine manner. Specifically, on the coarse side, we propose a photometric alignment module that aligns an image in the source domain with a reference image from the target domain using a set of image-level operators; on the fine side, we propose a category-oriented triplet loss that imposes a soft constraint to regularize category centers in the source domain and a self-supervised consistency regularization method in the target domain. Experimental results show that our proposed pipeline improves the generalization capability of the final segmentation model and significantly outperforms all previous state-of-the-arts.