 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Domain Adaptive Semantic Segmentation with Photometric Alignment and Category-Center Regularization
Mar 24, 2021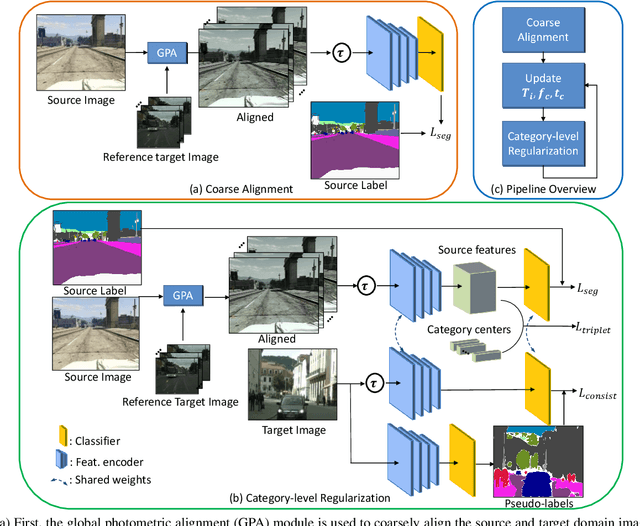
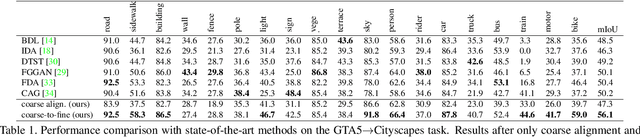
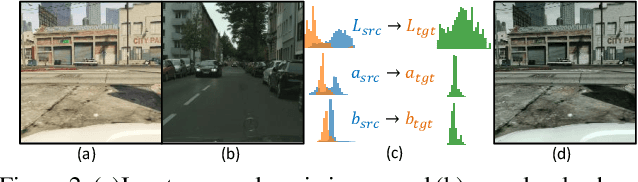
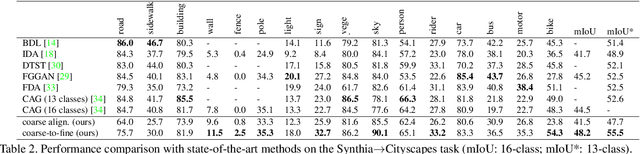
Unsupervised domain adaptation (UDA) in semantic segmentation is a fundamental yet promising task relieving the need for laborious annotation works. However, the domain shifts/discrepancies problem in this task compromise the final segmentation performance. Based on our observation, the main causes of the domain shifts are differences in imaging conditions, called image-level domain shifts, and differences in object category configurations called category-level domain shifts. In this paper, we propose a novel UDA pipeline that unifies image-level alignment and category-level feature distribution regularization in a coarse-to-fine manner. Specifically, on the coarse side, we propose a photometric alignment module that aligns an image in the source domain with a reference image from the target domain using a set of image-level operators; on the fine side, we propose a category-oriented triplet loss that imposes a soft constraint to regularize category centers in the source domain and a self-supervised consistency regularization method in the target domain. Experimental results show that our proposed pipeline improves the generalization capability of the final segmentation model and significantly outperforms all previous state-of-the-arts.
REFUGE Challenge: A Unified Framework for Evaluating Automated Methods for Glaucoma Assessment from Fundus Photographs
Oct 08, 2019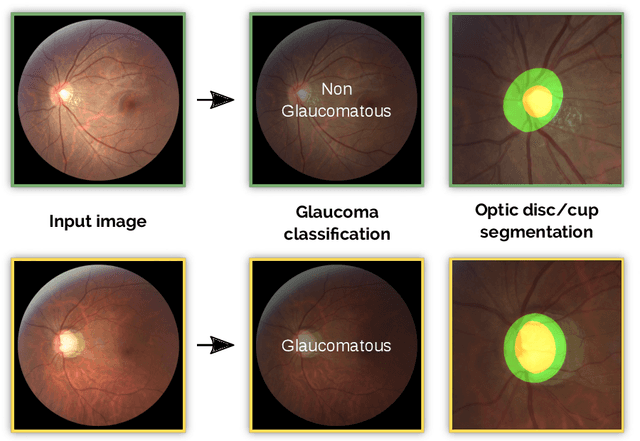
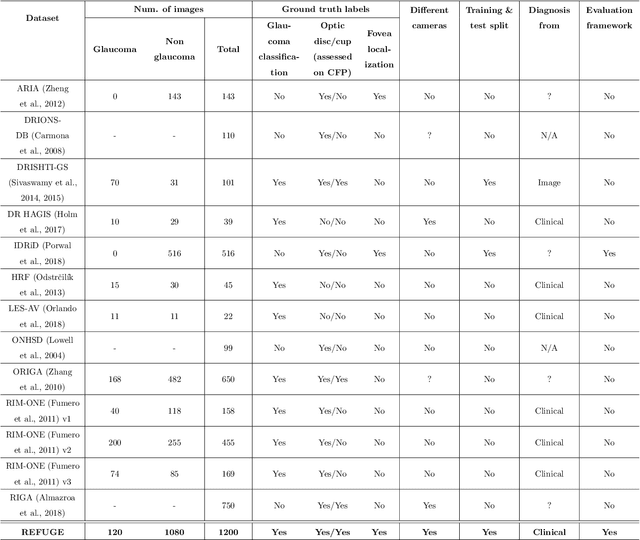

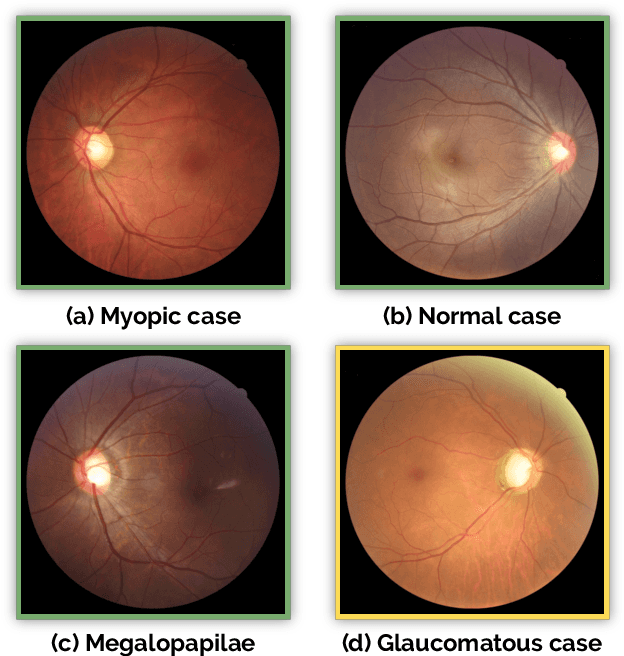
Glaucoma is one of the leading causes of irreversible but preventable blindness in working age populations. Color fundus photography (CFP) is the most cost-effective imaging modality to screen for retinal disorders. However, its application to glaucoma has been limited to the computation of a few related biomarkers such as the vertical cup-to-disc ratio. Deep learning approaches, although widely applied for medical image analysis, have not been extensively used for glaucoma assessment due to the limited size of the available data sets. Furthermore, the lack of a standardize benchmark strategy makes difficult to compare existing methods in a uniform way. In order to overcome these issues we set up the Retinal Fundus Glaucoma Challenge, REFUGE (\url{https://refuge.grand-challenge.org}), held in conjunction with MICCAI 2018. The challenge consisted of two primary tasks, namely optic disc/cup segmentation and glaucoma classification. As part of REFUGE, we have publicly released a data set of 1200 fundus images with ground truth segmentations and clinical glaucoma labels, currently the largest existing one. We have also built an evaluation framework to ease and ensure fairness in the comparison of different models, encouraging the development of novel techniques in the field. 12 teams qualified and participated in the online challenge. This paper summarizes their methods and analyzes their corresponding results. In particular, we observed that two of the top-ranked teams outperformed two human experts in the glaucoma classification task. Furthermore, the segmentation results were in general consistent with the ground truth annotations, with complementary outcomes that can be further exploited by ensembling the results.
Real-time Semantic Image Segmentation via Spatial Sparsity
Dec 01, 2017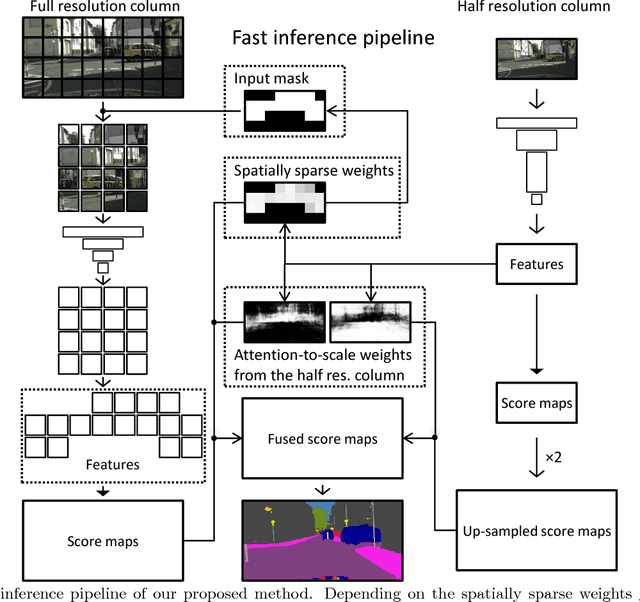

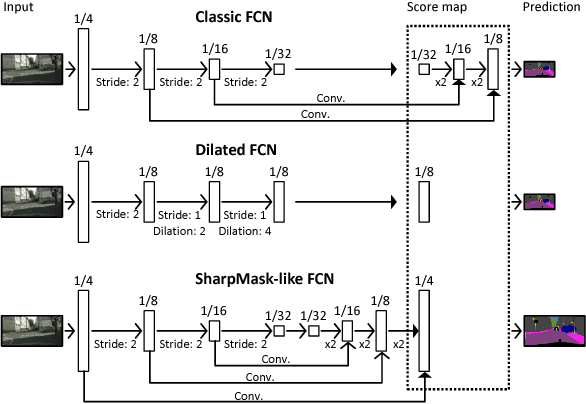
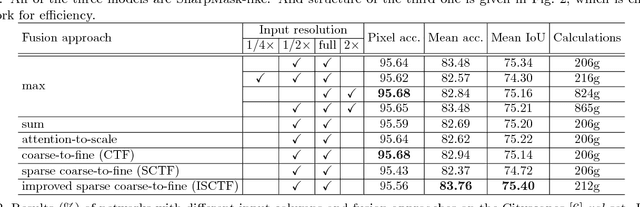
We propose an approach to semantic (image) segmentation that reduces the computational costs by a factor of 25 with limited impact on the quality of results. Semantic segmentation has a number of practical applications, and for most such applications the computational costs are critical. The method follows a typical two-column network structure, where one column accepts an input image, while the other accepts a half-resolution version of that image. By identifying specific regions in the full-resolution image that can be safely ignored, as well as carefully tailoring the network structure, we can process approximately 15 highresolution Cityscapes images (1024x2048) per second using a single GTX 980 video card, while achieving a mean intersection-over-union score of 72.9% on the Cityscapes test set.
Estimating Depth from Monocular Images as Classification Using Deep Fully Convolutional Residual Networks
Aug 11, 2017
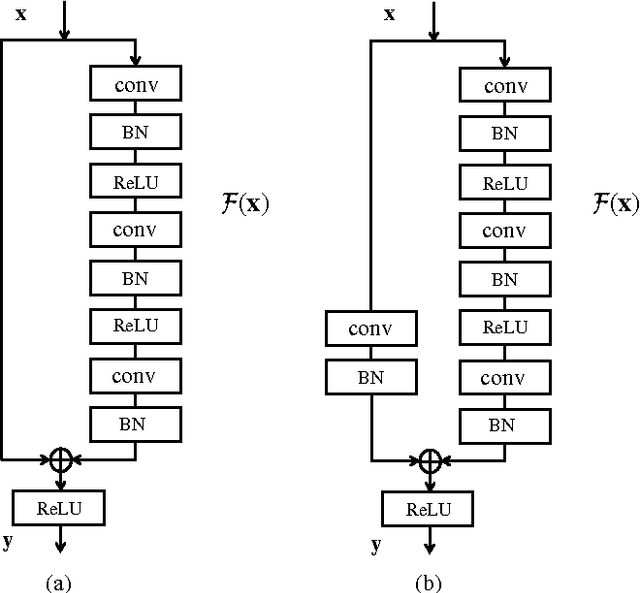
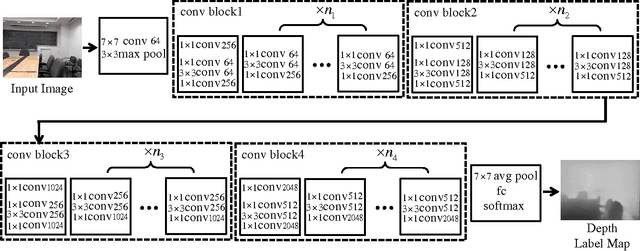
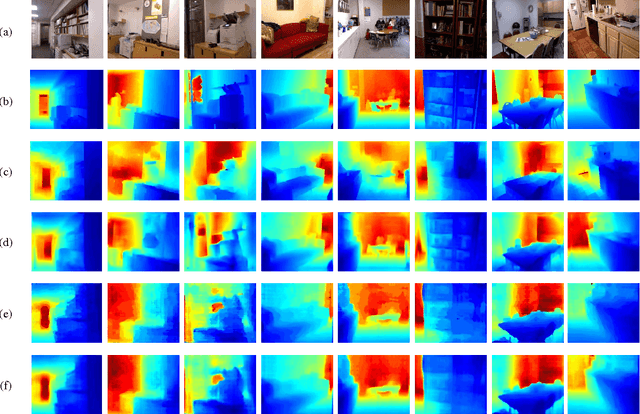
Depth estimation from single monocular images is a key component of scene understanding and has benefited largely from deep convolutional neural networks (CNN) recently. In this article, we take advantage of the recent deep residual networks and propose a simple yet effective approach to this problem. We formulate depth estimation as a pixel-wise classification task. Specifically, we first discretize the continuous depth values into multiple bins and label the bins according to their depth range. Then we train fully convolutional deep residual networks to predict the depth label of each pixel. Performing discrete depth label classification instead of continuous depth value regression allows us to predict a confidence in the form of probability distribution. We further apply fully-connected conditional random fields (CRF) as a post processing step to enforce local smoothness interactions, which improves the results. We evaluate our approach on both indoor and outdoor datasets and achieve state-of-the-art performance.
Wider or Deeper: Revisiting the ResNet Model for Visual Recognition
Nov 30, 2016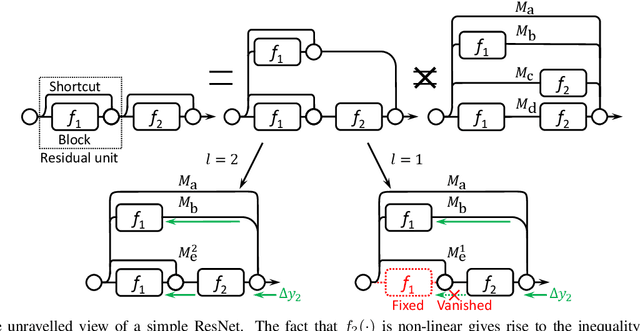

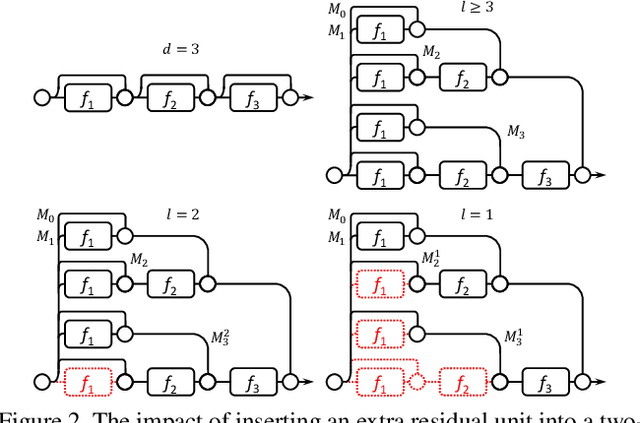

The trend towards increasingly deep neural networks has been driven by a general observation that increasing depth increases the performance of a network. Recently, however, evidence has been amassing that simply increasing depth may not be the best way to increase performance, particularly given other limitations. Investigations into deep residual networks have also suggested that they may not in fact be operating as a single deep network, but rather as an ensemble of many relatively shallow networks. We examine these issues, and in doing so arrive at a new interpretation of the unravelled view of deep residual networks which explains some of the behaviours that have been observed experimentally. As a result, we are able to derive a new, shallower, architecture of residual networks which significantly outperforms much deeper models such as ResNet-200 on the ImageNet classification dataset. We also show that this performance is transferable to other problem domains by developing a semantic segmentation approach which outperforms the state-of-the-art by a remarkable margin on datasets including PASCAL VOC, PASCAL Context, and Cityscapes. The architecture that we propose thus outperforms its comparators, including very deep ResNets, and yet is more efficient in memory use and sometimes also in training time. The code and models are available at https://github.com/itijyou/ademxapp
Bridging Category-level and Instance-level Semantic Image Segmentation
May 23, 2016



We propose an approach to instance-level image segmentation that is built on top of category-level segmentation. Specifically, for each pixel in a semantic category mask, its corresponding instance bounding box is predicted using a deep fully convolutional regression network. Thus it follows a different pipeline to the popular detect-then-segment approaches that first predict instances' bounding boxes, which are the current state-of-the-art in instance segmentation. We show that, by leveraging the strength of our state-of-the-art semantic segmentation models, the proposed method can achieve comparable or even better results to detect-then-segment approaches. We make the following contributions. (i) First, we propose a simple yet effective approach to semantic instance segmentation. (ii) Second, we propose an online bootstrapping method during training, which is critically important for achieving good performance for both semantic category segmentation and instance-level segmentation. (iii) As the performance of semantic category segmentation has a significant impact on the instance-level segmentation, which is the second step of our approach, we train fully convolutional residual networks to achieve the best semantic category segmentation accuracy. On the PASCAL VOC 2012 dataset, we obtain the currently best mean intersection-over-union score of 79.1%. (iv) We also achieve state-of-the-art results for instance-level segmentation.
High-performance Semantic Segmentation Using Very Deep Fully Convolutional Networks
Apr 15, 2016
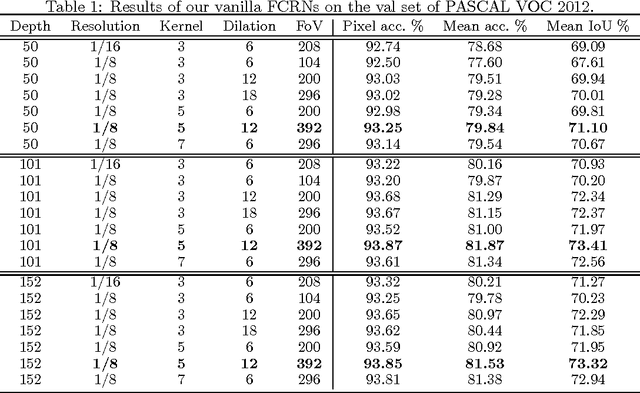


We propose a method for high-performance semantic image segmentation (or semantic pixel labelling) based on very deep residual networks, which achieves the state-of-the-art performance. A few design factors are carefully considered to this end. We make the following contributions. (i) First, we evaluate different variations of a fully convolutional residual network so as to find the best configuration, including the number of layers, the resolution of feature maps, and the size of field-of-view. Our experiments show that further enlarging the field-of-view and increasing the resolution of feature maps are typically beneficial, which however inevitably leads to a higher demand for GPU memories. To walk around the limitation, we propose a new method to simulate a high resolution network with a low resolution network, which can be applied during training and/or testing. (ii) Second, we propose an online bootstrapping method for training. We demonstrate that online bootstrapping is critically important for achieving good accuracy. (iii) Third we apply the traditional dropout to some of the residual blocks, which further improves the performance. (iv) Finally, our method achieves the currently best mean intersection-over-union 78.3\% on the PASCAL VOC 2012 dataset, as well as on the recent dataset Cityscapes.