 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWider or Deeper: Revisiting the ResNet Model for Visual Recognition
Paper and Code
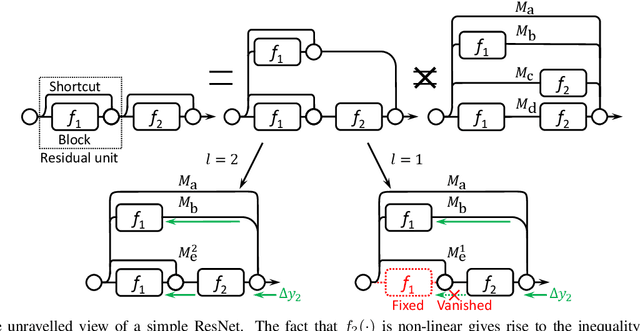

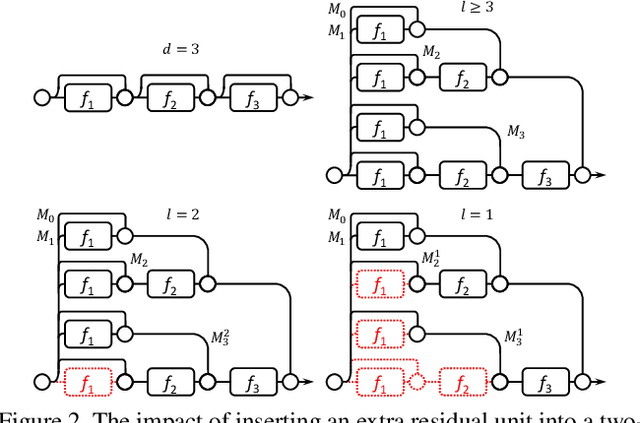

The trend towards increasingly deep neural networks has been driven by a general observation that increasing depth increases the performance of a network. Recently, however, evidence has been amassing that simply increasing depth may not be the best way to increase performance, particularly given other limitations. Investigations into deep residual networks have also suggested that they may not in fact be operating as a single deep network, but rather as an ensemble of many relatively shallow networks. We examine these issues, and in doing so arrive at a new interpretation of the unravelled view of deep residual networks which explains some of the behaviours that have been observed experimentally. As a result, we are able to derive a new, shallower, architecture of residual networks which significantly outperforms much deeper models such as ResNet-200 on the ImageNet classification dataset. We also show that this performance is transferable to other problem domains by developing a semantic segmentation approach which outperforms the state-of-the-art by a remarkable margin on datasets including PASCAL VOC, PASCAL Context, and Cityscapes. The architecture that we propose thus outperforms its comparators, including very deep ResNets, and yet is more efficient in memory use and sometimes also in training time. The code and models are available at https://github.com/itijyou/ademxapp