 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveFuse-AL: Cyclical and Performance-Adaptive Multi-Strategy Active Learning for Medical Images
Nov 19, 2025Active learning reduces annotation costs in medical imaging by strategically selecting the most informative samples for labeling. However, individual acquisition strategies often exhibit inconsistent behavior across different stages of the active learning cycle. We propose Cyclical and Performance-Adaptive Multi-Strategy Active Learning (WaveFuse-AL), a novel framework that adaptively fuses multiple established acquisition strategies-BALD, BADGE, Entropy, and CoreSet throughout the learning process. WaveFuse-AL integrates cyclical (sinusoidal) temporal priors with performance-driven adaptation to dynamically adjust strategy importance over time. We evaluate WaveFuse-AL on three medical imaging benchmarks: APTOS-2019 (multi-class classification), RSNA Pneumonia Detection (binary classification), and ISIC-2018 (skin lesion segmentation). Experimental results demonstrate that WaveFuse-AL consistently outperforms both single-strategy and alternating-strategy baselines, achieving statistically significant performance improvements (on ten out of twelve metric measurements) while maximizing the utility of limited annotation budgets.
Understanding Calibration of Deep Neural Networks for Medical Image Classification
Sep 22, 2023



In the field of medical image analysis, achieving high accuracy is not enough; ensuring well-calibrated predictions is also crucial. Confidence scores of a deep neural network play a pivotal role in explainability by providing insights into the model's certainty, identifying cases that require attention, and establishing trust in its predictions. Consequently, the significance of a well-calibrated model becomes paramount in the medical imaging domain, where accurate and reliable predictions are of utmost importance. While there has been a significant effort towards training modern deep neural networks to achieve high accuracy on medical imaging tasks, model calibration and factors that affect it remain under-explored. To address this, we conducted a comprehensive empirical study that explores model performance and calibration under different training regimes. We considered fully supervised training, which is the prevailing approach in the community, as well as rotation-based self-supervised method with and without transfer learning, across various datasets and architecture sizes. Multiple calibration metrics were employed to gain a holistic understanding of model calibration. Our study reveals that factors such as weight distributions and the similarity of learned representations correlate with the calibration trends observed in the models. Notably, models trained using rotation-based self-supervised pretrained regime exhibit significantly better calibration while achieving comparable or even superior performance compared to fully supervised models across different medical imaging datasets. These findings shed light on the importance of model calibration in medical image analysis and highlight the benefits of incorporating self-supervised learning approach to improve both performance and calibration.
Leveraging Different Learning Styles for Improved Knowledge Distillation
Dec 06, 2022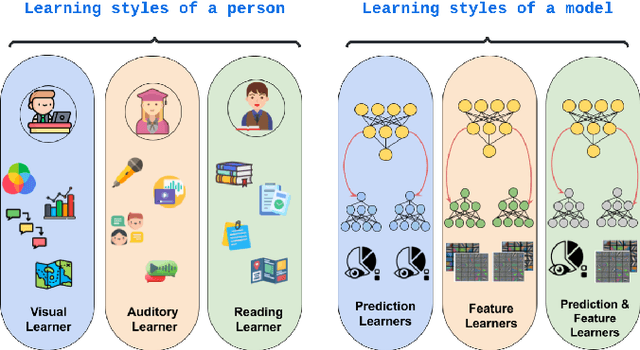
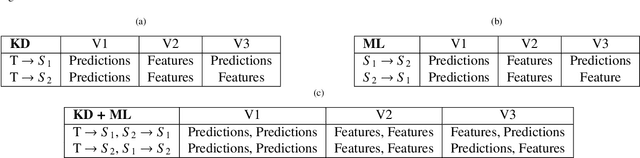
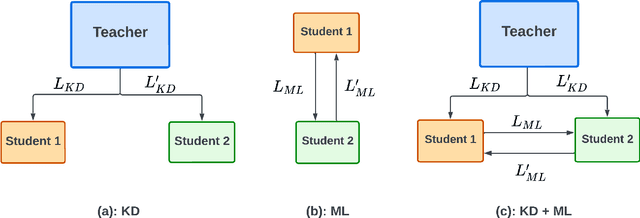
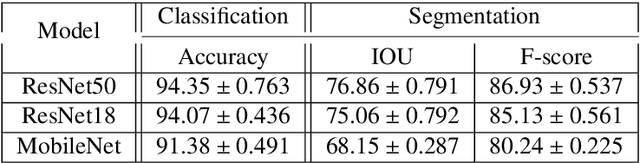
Learning style refers to a type of training mechanism adopted by an individual to gain new knowledge. As suggested by the VARK model, humans have different learning preferences like visual, auditory, etc., for acquiring and effectively processing information. Inspired by this concept, our work explores the idea of mixed information sharing with model compression in the context of Knowledge Distillation (KD) and Mutual Learning (ML). Unlike conventional techniques that share the same type of knowledge with all networks, we propose to train individual networks with different forms of information to enhance the learning process. We formulate a combined KD and ML framework with one teacher and two student networks that share or exchange information in the form of predictions and feature maps. Our comprehensive experiments with benchmark classification and segmentation datasets demonstrate that with 15% compression, the ensemble performance of networks trained with diverse forms of knowledge outperforms the conventional techniques both quantitatively and qualitatively.
IPNET:Influential Prototypical Networks for Few Shot Learning
Aug 19, 2022Prototypical network (PN) is a simple yet effective few shot learning strategy. It is a metric-based meta-learning technique where classification is performed by computing Euclidean distances to prototypical representations of each class. Conventional PN attributes equal importance to all samples and generates prototypes by simply averaging the support sample embeddings belonging to each class. In this work, we propose a novel version of PN that attributes weights to support samples corresponding to their influence on the support sample distribution. Influence weights of samples are calculated based on maximum mean discrepancy (MMD) between the mean embeddings of sample distributions including and excluding the sample. Further, the influence factor of a sample is measured using MMD based on the shift in the distribution in the absence of that sample.
Influential Prototypical Networks for Few Shot Learning: A Dermatological Case Study
Nov 11, 2021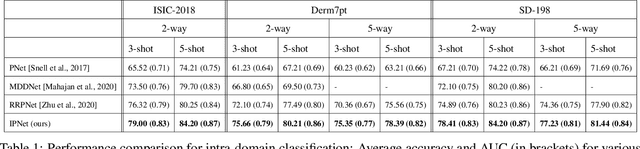
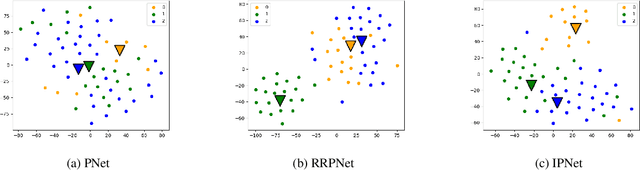
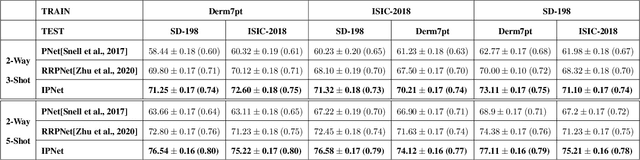
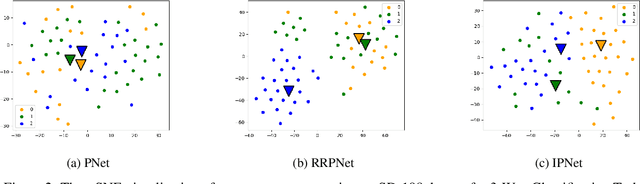
Prototypical network (PN) is a simple yet effective few shot learning strategy. It is a metric-based meta-learning technique where classification is performed by computing Euclidean distances to prototypical representations of each class. Conventional PN attributes equal importance to all samples and generates prototypes by simply averaging the support sample embeddings belonging to each class. In this work, we propose a novel version of PN that attributes weights to support samples corresponding to their influence on the support sample distribution. Influence weights of samples are calculated based on maximum mean discrepancy (MMD) between the mean embeddings of sample distributions including and excluding the sample. Comprehensive evaluation of our proposed influential PN (IPNet) is performed by comparing its performance with other baseline PNs on three different benchmark dermatological datasets. IPNet outperforms all baseline models with compelling results across all three datasets and various N-way, K-shot classification tasks. Findings from cross-domain adaptation experiments further establish the robustness and generalizability of IPNet.
Augmenting Knowledge Distillation With Peer-To-Peer Mutual Learning For Model Compression
Oct 22, 2021



Knowledge distillation (KD) is an effective model compression technique where a compact student network is taught to mimic the behavior of a complex and highly trained teacher network. In contrast, Mutual Learning (ML) provides an alternative strategy where multiple simple student networks benefit from sharing knowledge, even in the absence of a powerful but static teacher network. Motivated by these findings, we propose a single-teacher, multi-student framework that leverages both KD and ML to achieve better performance. Furthermore, an online distillation strategy is utilized to train the teacher and students simultaneously. To evaluate the performance of the proposed approach, extensive experiments were conducted using three different versions of teacher-student networks on benchmark biomedical classification (MSI vs. MSS) and object detection (Polyp Detection) tasks. Ensemble of student networks trained in the proposed manner achieved better results than the ensemble of students trained using KD or ML individually, establishing the benefit of augmenting knowledge transfer from teacher to students with peer-to-peer learning between students.
Towards Reducing Aleatoric Uncertainty for Medical Imaging Tasks
Oct 21, 2021

In safety-critical applications like medical diagnosis, certainty associated with a model's prediction is just as important as its accuracy. Consequently, uncertainty estimation and reduction play a crucial role. Uncertainty in predictions can be attributed to noise or randomness in data (aleatoric) and incorrect model inferences (epistemic). While model uncertainty can be reduced with more data or bigger models, aleatoric uncertainty is more intricate. This work proposes a novel approach that interprets data uncertainty estimated from a self-supervised task as noise inherent to the data and utilizes it to reduce aleatoric uncertainty in another task related to the same dataset via data augmentation. The proposed method was evaluated on a benchmark medical imaging dataset with image reconstruction as the self-supervised task and segmentation as the image analysis task. Our findings demonstrate the effectiveness of the proposed approach in significantly reducing the aleatoric uncertainty in the image segmentation task while achieving better or on-par performance compared to the standard augmentation techniques.
MRI to PET Cross-Modality Translation using Globally and Locally Aware GAN for Multi-Modal Diagnosis of Alzheimer's Disease
Aug 04, 2021



Medical imaging datasets are inherently high dimensional with large variability and low sample sizes that limit the effectiveness of deep learning algorithms. Recently, generative adversarial networks (GANs) with the ability to synthesize realist images have shown great potential as an alternative to standard data augmentation techniques. Our work focuses on cross-modality synthesis of fluorodeoxyglucose~(FDG) Positron Emission Tomography~(PET) scans from structural Magnetic Resonance~(MR) images using generative models to facilitate multi-modal diagnosis of Alzheimer's disease (AD). Specifically, we propose a novel end-to-end, globally and locally aware image-to-image translation GAN (GLA-GAN) with a multi-path architecture that enforces both global structural integrity and fidelity to local details. We further supplement the standard adversarial loss with voxel-level intensity, multi-scale structural similarity (MS-SSIM) and region-of-interest (ROI) based loss components that reduce reconstruction error, enforce structural consistency at different scales and perceive variation in regional sensitivity to AD respectively. Experimental results demonstrate that our GLA-GAN not only generates synthesized FDG-PET scans with enhanced image quality but also superior clinical utility in improving AD diagnosis compared to state-of-the-art models. Finally, we attempt to interpret some of the internal units of the GAN that are closely related to this specific cross-modality generation task.
EEG-ConvTransformer for Single-Trial EEG based Visual Stimuli Classification
Jul 08, 2021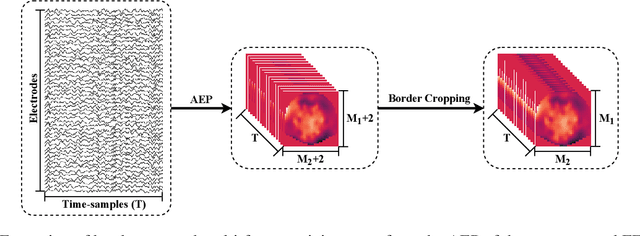
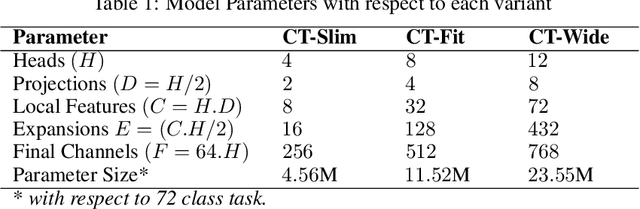
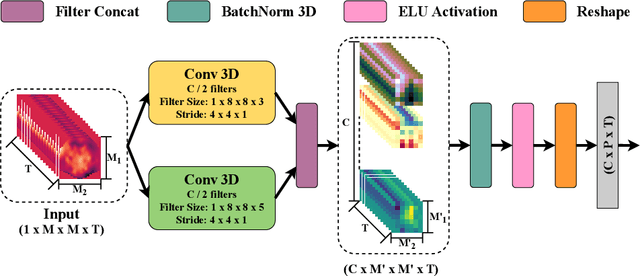

Different categories of visual stimuli activate different responses in the human brain. These signals can be captured with EEG for utilization in applications such as Brain-Computer Interface (BCI). However, accurate classification of single-trial data is challenging due to low signal-to-noise ratio of EEG. This work introduces an EEG-ConvTranformer network that is based on multi-headed self-attention. Unlike other transformers, the model incorporates self-attention to capture inter-region interactions. It further extends to adjunct convolutional filters with multi-head attention as a single module to learn temporal patterns. Experimental results demonstrate that EEG-ConvTransformer achieves improved classification accuracy over the state-of-the-art techniques across five different visual stimuli classification tasks. Finally, quantitative analysis of inter-head diversity also shows low similarity in representational subspaces, emphasizing the implicit diversity of multi-head attention.
Domain Specific, Semi-Supervised Transfer Learning for Medical Imaging
May 24, 2020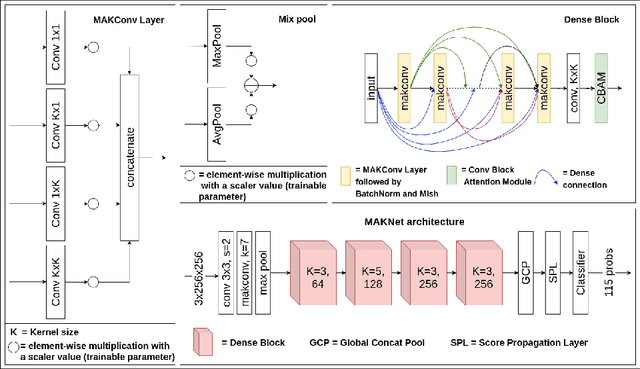

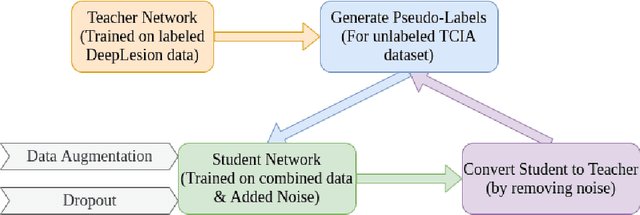

Limited availability of annotated medical imaging data poses a challenge for deep learning algorithms. Although transfer learning minimizes this hurdle in general, knowledge transfer across disparate domains is shown to be less effective. On the other hand, smaller architectures were found to be more compelling in learning better features. Consequently, we propose a lightweight architecture that uses mixed asymmetric kernels (MAKNet) to reduce the number of parameters significantly. Additionally, we train the proposed architecture using semi-supervised learning to provide pseudo-labels for a large medical dataset to assist with transfer learning. The proposed MAKNet provides better classification performance with $60 - 70\%$ less parameters than popular architectures. Experimental results also highlight the importance of domain-specific knowledge for effective transfer learning.