 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTractable Sharpness-Aware Learning of Probabilistic Circuits
Aug 07, 2025Probabilistic Circuits (PCs) are a class of generative models that allow exact and tractable inference for a wide range of queries. While recent developments have enabled the learning of deep and expressive PCs, this increased capacity can often lead to overfitting, especially when data is limited. We analyze PC overfitting from a log-likelihood-landscape perspective and show that it is often caused by convergence to sharp optima that generalize poorly. Inspired by sharpness aware minimization in neural networks, we propose a Hessian-based regularizer for training PCs. As a key contribution, we show that the trace of the Hessian of the log-likelihood-a sharpness proxy that is typically intractable in deep neural networks-can be computed efficiently for PCs. Minimizing this Hessian trace induces a gradient-norm-based regularizer that yields simple closed-form parameter updates for EM, and integrates seamlessly with gradient based learning methods. Experiments on synthetic and real-world datasets demonstrate that our method consistently guides PCs toward flatter minima, improves generalization performance.
Understanding Calibration of Deep Neural Networks for Medical Image Classification
Sep 22, 2023



In the field of medical image analysis, achieving high accuracy is not enough; ensuring well-calibrated predictions is also crucial. Confidence scores of a deep neural network play a pivotal role in explainability by providing insights into the model's certainty, identifying cases that require attention, and establishing trust in its predictions. Consequently, the significance of a well-calibrated model becomes paramount in the medical imaging domain, where accurate and reliable predictions are of utmost importance. While there has been a significant effort towards training modern deep neural networks to achieve high accuracy on medical imaging tasks, model calibration and factors that affect it remain under-explored. To address this, we conducted a comprehensive empirical study that explores model performance and calibration under different training regimes. We considered fully supervised training, which is the prevailing approach in the community, as well as rotation-based self-supervised method with and without transfer learning, across various datasets and architecture sizes. Multiple calibration metrics were employed to gain a holistic understanding of model calibration. Our study reveals that factors such as weight distributions and the similarity of learned representations correlate with the calibration trends observed in the models. Notably, models trained using rotation-based self-supervised pretrained regime exhibit significantly better calibration while achieving comparable or even superior performance compared to fully supervised models across different medical imaging datasets. These findings shed light on the importance of model calibration in medical image analysis and highlight the benefits of incorporating self-supervised learning approach to improve both performance and calibration.
Generalized Cross-domain Multi-label Few-shot Learning for Chest X-rays
Sep 08, 2023



Real-world application of chest X-ray abnormality classification requires dealing with several challenges: (i) limited training data; (ii) training and evaluation sets that are derived from different domains; and (iii) classes that appear during training may have partial overlap with classes of interest during evaluation. To address these challenges, we present an integrated framework called Generalized Cross-Domain Multi-Label Few-Shot Learning (GenCDML-FSL). The framework supports overlap in classes during training and evaluation, cross-domain transfer, adopts meta-learning to learn using few training samples, and assumes each chest X-ray image is either normal or associated with one or more abnormalities. Furthermore, we propose Generalized Episodic Training (GenET), a training strategy that equips models to operate with multiple challenges observed in the GenCDML-FSL scenario. Comparisons with well-established methods such as transfer learning, hybrid transfer learning, and multi-label meta-learning on multiple datasets show the superiority of our approach.
Towards Reducing Aleatoric Uncertainty for Medical Imaging Tasks
Oct 21, 2021

In safety-critical applications like medical diagnosis, certainty associated with a model's prediction is just as important as its accuracy. Consequently, uncertainty estimation and reduction play a crucial role. Uncertainty in predictions can be attributed to noise or randomness in data (aleatoric) and incorrect model inferences (epistemic). While model uncertainty can be reduced with more data or bigger models, aleatoric uncertainty is more intricate. This work proposes a novel approach that interprets data uncertainty estimated from a self-supervised task as noise inherent to the data and utilizes it to reduce aleatoric uncertainty in another task related to the same dataset via data augmentation. The proposed method was evaluated on a benchmark medical imaging dataset with image reconstruction as the self-supervised task and segmentation as the image analysis task. Our findings demonstrate the effectiveness of the proposed approach in significantly reducing the aleatoric uncertainty in the image segmentation task while achieving better or on-par performance compared to the standard augmentation techniques.
Efficient Algorithms For Fair Clustering with a New Fairness Notion
Sep 03, 2021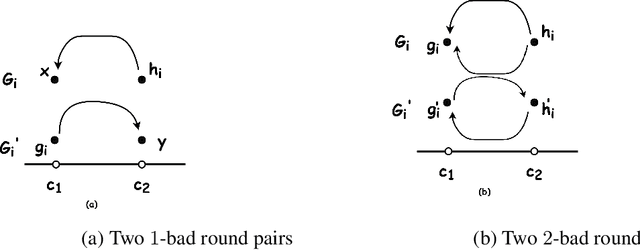
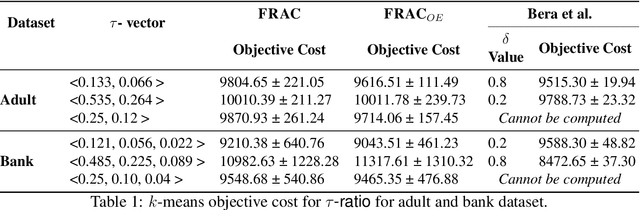
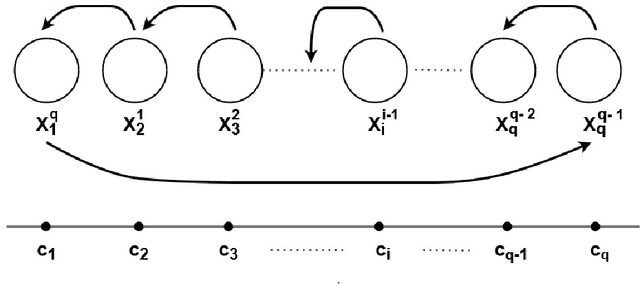
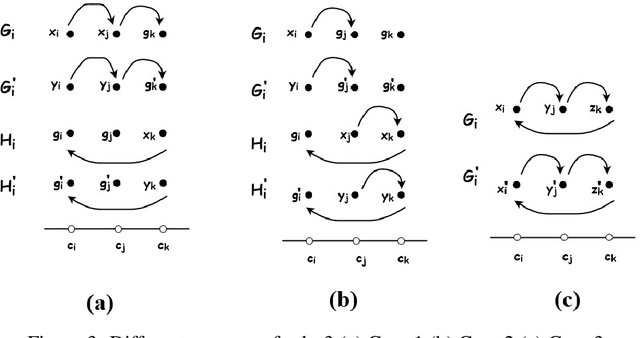
We revisit the problem of fair clustering, first introduced by Chierichetti et al., that requires each protected attribute to have approximately equal representation in every cluster; i.e., a balance property. Existing solutions to fair clustering are either not scalable or do not achieve an optimal trade-off between clustering objective and fairness. In this paper, we propose a new notion of fairness, which we call $tau$-fair fairness, that strictly generalizes the balance property and enables a fine-grained efficiency vs. fairness trade-off. Furthermore, we show that simple greedy round-robin based algorithms achieve this trade-off efficiently. Under a more general setting of multi-valued protected attributes, we rigorously analyze the theoretical properties of the our algorithms. Our experimental results suggest that the proposed solution outperforms all the state-of-the-art algorithms and works exceptionally well even for a large number of clusters.
Deep Geospatial Interpolation Networks
Aug 15, 2021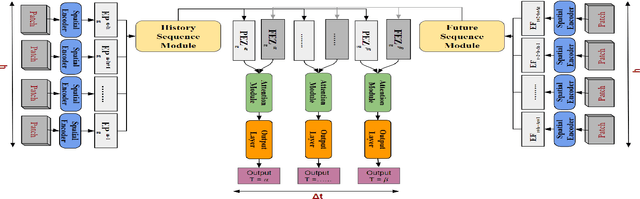
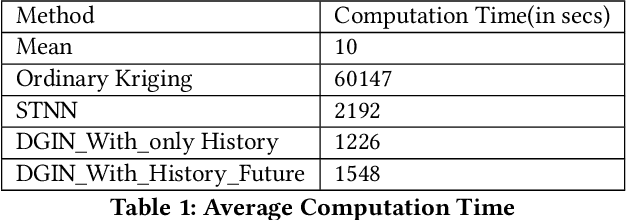
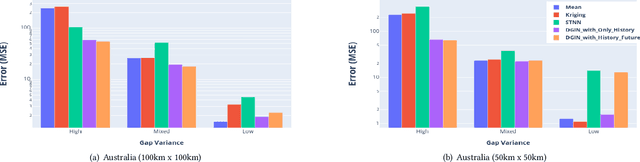
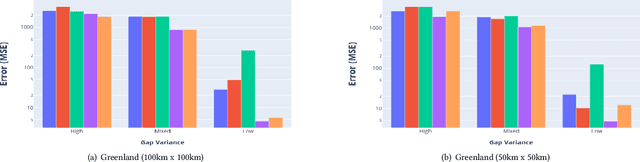
Interpolation in Spatio-temporal data has applications in various domains such as climate, transportation, and mining. Spatio-Temporal interpolation is highly challenging due to the complex spatial and temporal relationships. However, traditional techniques such as Kriging suffer from high running time and poor performance on data that exhibit high variance across space and time dimensions. To this end, we propose a novel deep neural network called as Deep Geospatial Interpolation Network(DGIN), which incorporates both spatial and temporal relationships and has significantly lower training time. DGIN consists of three major components: Spatial Encoder to capture the spatial dependencies, Sequential module to incorporate the temporal dynamics, and an Attention block to learn the importance of the temporal neighborhood around the gap. We evaluate DGIN on the MODIS reflectance dataset from two different regions. Our experimental results indicate that DGIN has two advantages: (a) it outperforms alternative approaches (has lower MSE with p-value < 0.01) and, (b) it has significantly low execution time than Kriging.
Task Attended Meta-Learning for Few-Shot Learning
Jun 20, 2021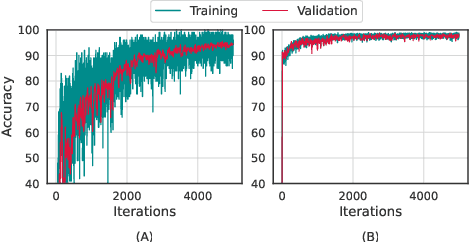
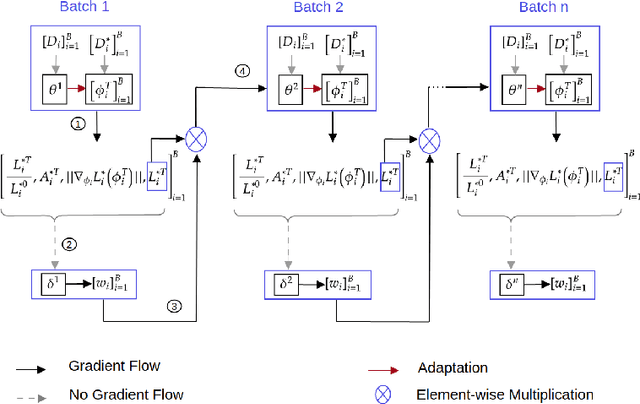
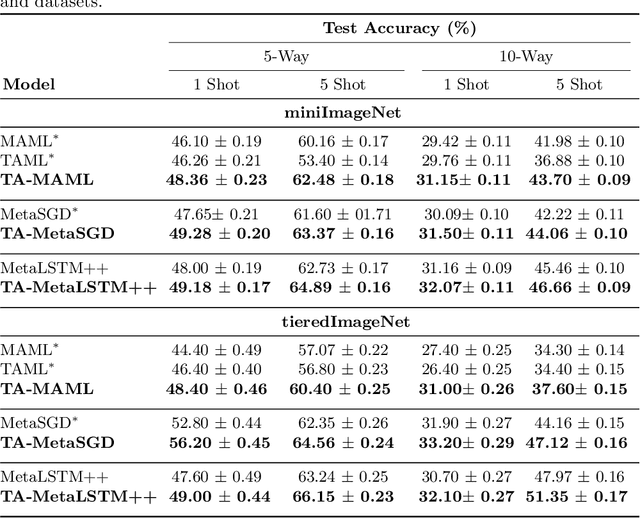
Meta-learning (ML) has emerged as a promising direction in learning models under constrained resource settings like few-shot learning. The popular approaches for ML either learn a generalizable initial model or a generic parametric optimizer through episodic training. The former approaches leverage the knowledge from a batch of tasks to learn an optimal prior. In this work, we study the importance of a batch for ML. Specifically, we first incorporate a batch episodic training regimen to improve the learning of the generic parametric optimizer. We also hypothesize that the common assumption in batch episodic training that each task in a batch has an equal contribution to learning an optimal meta-model need not be true. We propose to weight the tasks in a batch according to their "importance" in improving the meta-model's learning. To this end, we introduce a training curriculum motivated by selective focus in humans, called task attended meta-training, to weight the tasks in a batch. Task attention is a standalone module that can be integrated with any batch episodic training regimen. The comparisons of the models with their non-task-attended counterparts on complex datasets like miniImageNet and tieredImageNet validate its effectiveness.
PhoNet: An Approach Towards Zero-shot Word Image Recognition in Historical Documents
May 31, 2021
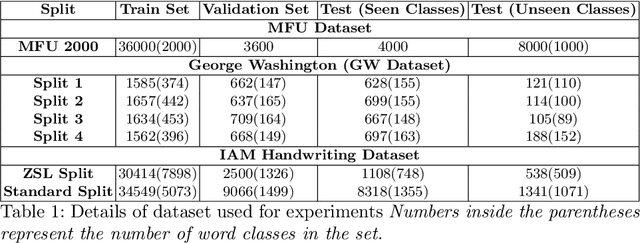

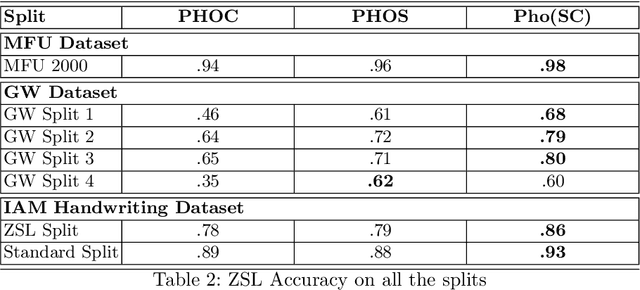
Annotating words in a historical document image archive for word image recognition purpose demands time and skilled human resource (like historians, paleographers). In a real-life scenario, obtaining sample images for all possible words is also not feasible. However, Zero-shot learning methods could aptly be used to recognize unseen/out-of-lexicon words in such historical document images. Based on previous state-of-the-art methods for word spotting and recognition, we propose a hybrid representation that considers the character's shape appearance to differentiate between two different words and has shown to be more effective in recognizing unseen words. This representation has been termed as Pyramidal Histogram of Shapes (PHOS), derived from PHOC, which embeds information about the occurrence and position of characters in the word. Later, the two representations are combined and experiments were conducted to examine the effectiveness of an embedding that has properties of both PHOS and PHOC. Encouraging results were obtained on two publicly available historical document datasets and one synthetic handwritten dataset, which justifies the efficacy of "Phos" and the combined "Pho(SC)" representation.
Characterizing GAN Convergence Through Proximal Duality Gap
May 11, 2021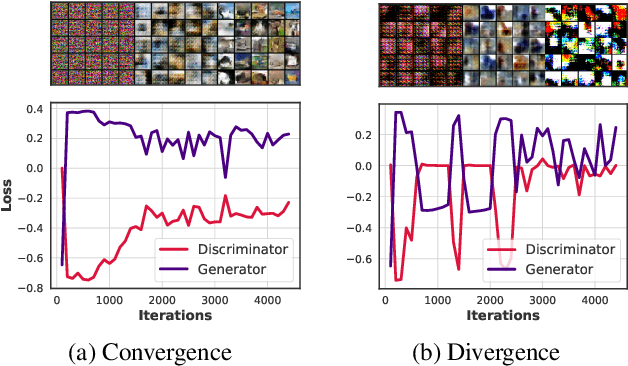
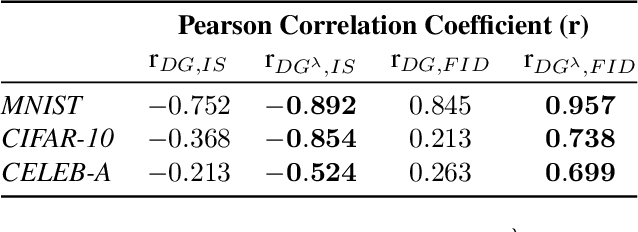
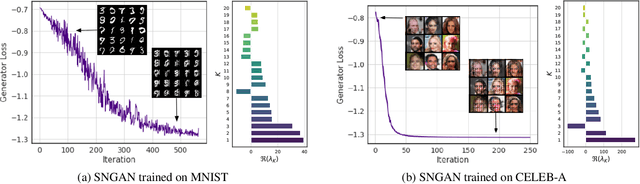
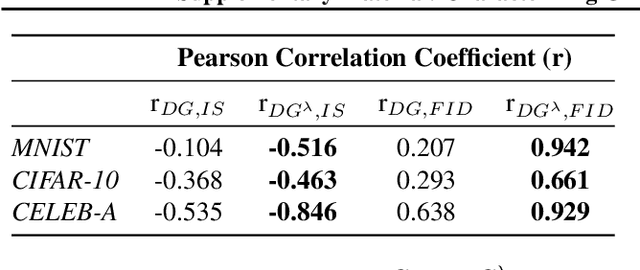
Despite the accomplishments of Generative Adversarial Networks (GANs) in modeling data distributions, training them remains a challenging task. A contributing factor to this difficulty is the non-intuitive nature of the GAN loss curves, which necessitates a subjective evaluation of the generated output to infer training progress. Recently, motivated by game theory, duality gap has been proposed as a domain agnostic measure to monitor GAN training. However, it is restricted to the setting when the GAN converges to a Nash equilibrium. But GANs need not always converge to a Nash equilibrium to model the data distribution. In this work, we extend the notion of duality gap to proximal duality gap that is applicable to the general context of training GANs where Nash equilibria may not exist. We show theoretically that the proximal duality gap is capable of monitoring the convergence of GANs to a wider spectrum of equilibria that subsumes Nash equilibria. We also theoretically establish the relationship between the proximal duality gap and the divergence between the real and generated data distributions for different GAN formulations. Our results provide new insights into the nature of GAN convergence. Finally, we validate experimentally the usefulness of proximal duality gap for monitoring and influencing GAN training.
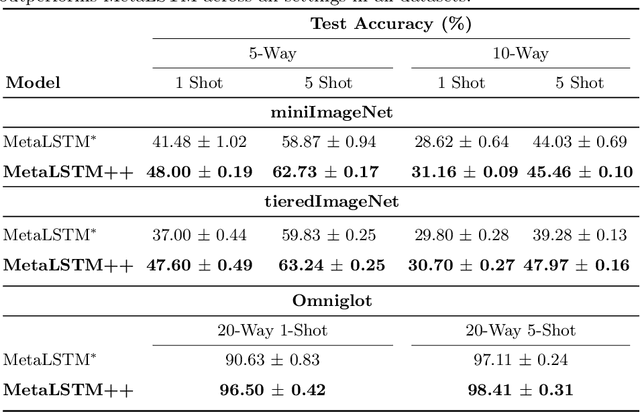
Stress Testing of Meta-learning Approaches for Few-shot Learning
Jan 21, 2021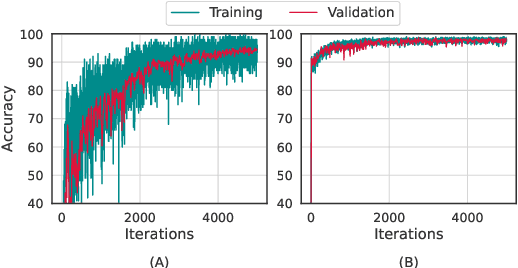
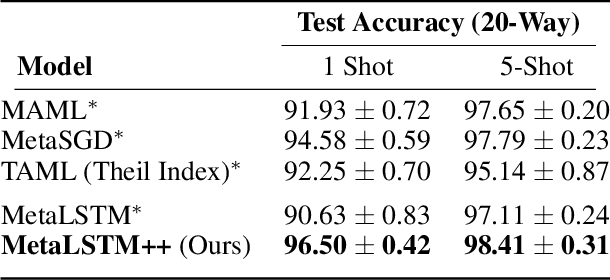
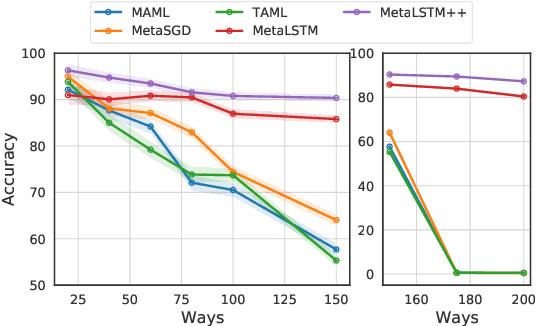
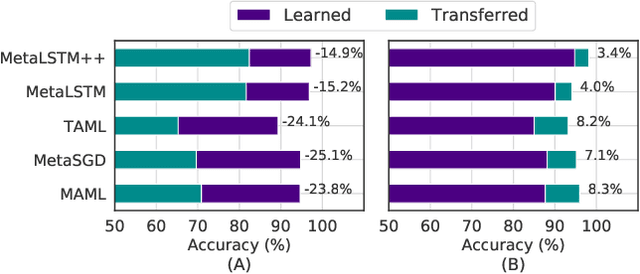
Meta-learning (ML) has emerged as a promising learning method under resource constraints such as few-shot learning. ML approaches typically propose a methodology to learn generalizable models. In this work-in-progress paper, we put the recent ML approaches to a stress test to discover their limitations. Precisely, we measure the performance of ML approaches for few-shot learning against increasing task complexity. Our results show a quick degradation in the performance of initialization strategies for ML (MAML, TAML, and MetaSGD), while surprisingly, approaches that use an optimization strategy (MetaLSTM) perform significantly better. We further demonstrate the effectiveness of an optimization strategy for ML (MetaLSTM++) trained in a MAML manner over a pure optimization strategy. Our experiments also show that the optimization strategies for ML achieve higher transferability from simple to complex tasks.