 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Cross-domain Multi-label Few-shot Learning for Chest X-rays
Sep 08, 2023



Real-world application of chest X-ray abnormality classification requires dealing with several challenges: (i) limited training data; (ii) training and evaluation sets that are derived from different domains; and (iii) classes that appear during training may have partial overlap with classes of interest during evaluation. To address these challenges, we present an integrated framework called Generalized Cross-Domain Multi-Label Few-Shot Learning (GenCDML-FSL). The framework supports overlap in classes during training and evaluation, cross-domain transfer, adopts meta-learning to learn using few training samples, and assumes each chest X-ray image is either normal or associated with one or more abnormalities. Furthermore, we propose Generalized Episodic Training (GenET), a training strategy that equips models to operate with multiple challenges observed in the GenCDML-FSL scenario. Comparisons with well-established methods such as transfer learning, hybrid transfer learning, and multi-label meta-learning on multiple datasets show the superiority of our approach.
Task Attended Meta-Learning for Few-Shot Learning
Jun 20, 2021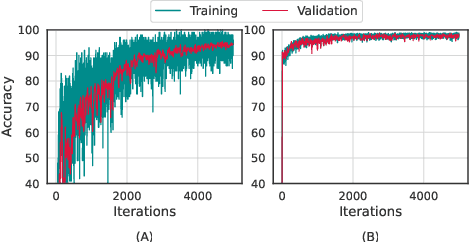
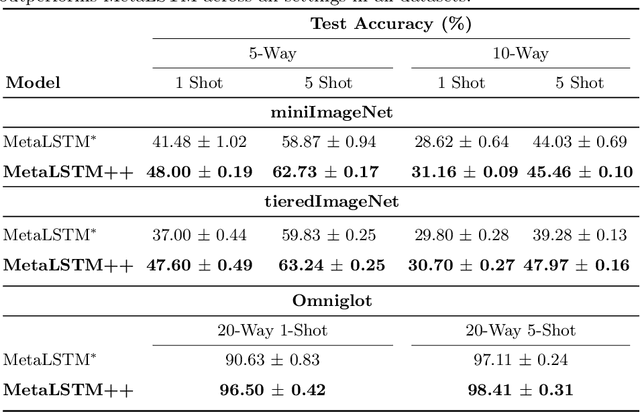
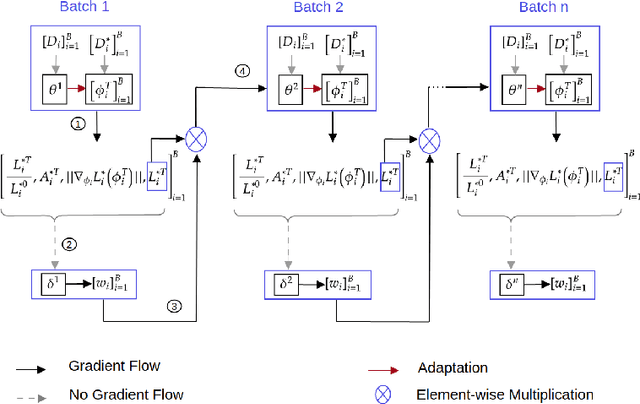
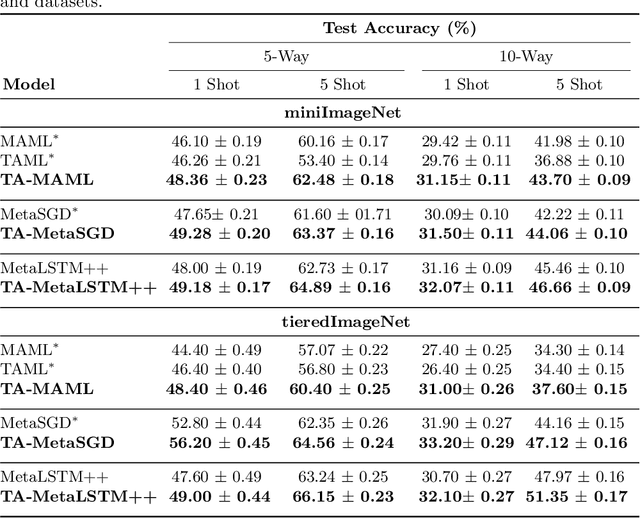
Meta-learning (ML) has emerged as a promising direction in learning models under constrained resource settings like few-shot learning. The popular approaches for ML either learn a generalizable initial model or a generic parametric optimizer through episodic training. The former approaches leverage the knowledge from a batch of tasks to learn an optimal prior. In this work, we study the importance of a batch for ML. Specifically, we first incorporate a batch episodic training regimen to improve the learning of the generic parametric optimizer. We also hypothesize that the common assumption in batch episodic training that each task in a batch has an equal contribution to learning an optimal meta-model need not be true. We propose to weight the tasks in a batch according to their "importance" in improving the meta-model's learning. To this end, we introduce a training curriculum motivated by selective focus in humans, called task attended meta-training, to weight the tasks in a batch. Task attention is a standalone module that can be integrated with any batch episodic training regimen. The comparisons of the models with their non-task-attended counterparts on complex datasets like miniImageNet and tieredImageNet validate its effectiveness.
Characterizing GAN Convergence Through Proximal Duality Gap
May 11, 2021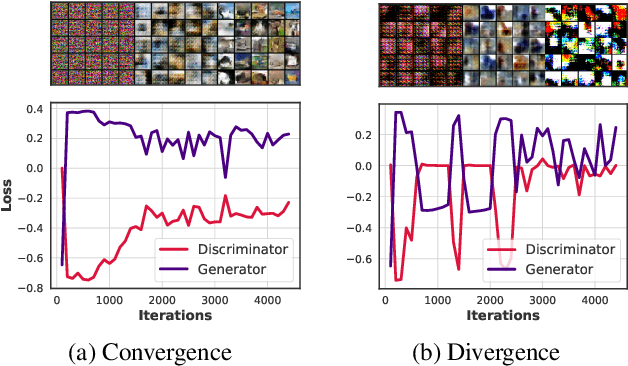
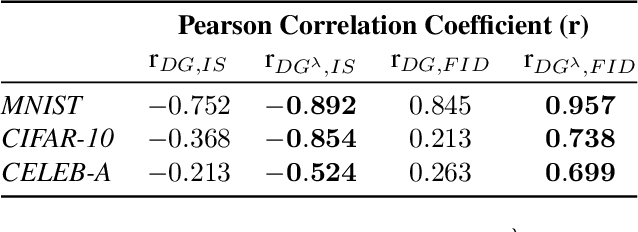
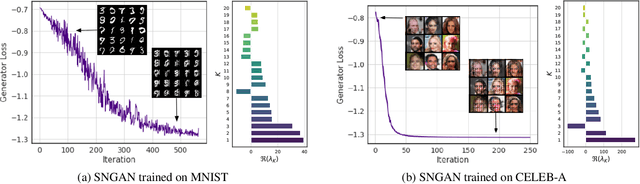
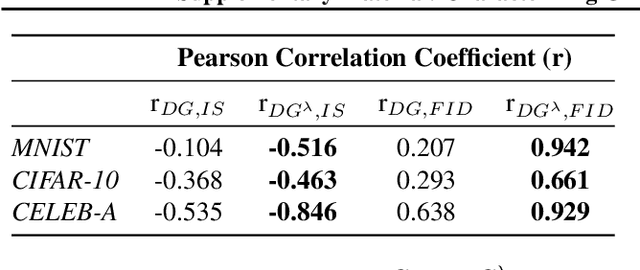
Despite the accomplishments of Generative Adversarial Networks (GANs) in modeling data distributions, training them remains a challenging task. A contributing factor to this difficulty is the non-intuitive nature of the GAN loss curves, which necessitates a subjective evaluation of the generated output to infer training progress. Recently, motivated by game theory, duality gap has been proposed as a domain agnostic measure to monitor GAN training. However, it is restricted to the setting when the GAN converges to a Nash equilibrium. But GANs need not always converge to a Nash equilibrium to model the data distribution. In this work, we extend the notion of duality gap to proximal duality gap that is applicable to the general context of training GANs where Nash equilibria may not exist. We show theoretically that the proximal duality gap is capable of monitoring the convergence of GANs to a wider spectrum of equilibria that subsumes Nash equilibria. We also theoretically establish the relationship between the proximal duality gap and the divergence between the real and generated data distributions for different GAN formulations. Our results provide new insights into the nature of GAN convergence. Finally, we validate experimentally the usefulness of proximal duality gap for monitoring and influencing GAN training.
Stress Testing of Meta-learning Approaches for Few-shot Learning
Jan 21, 2021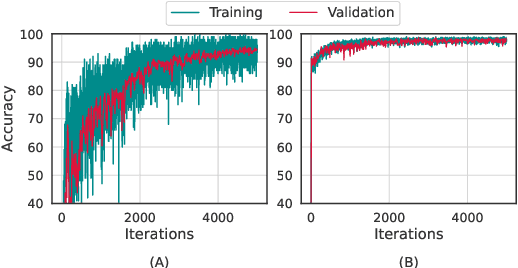
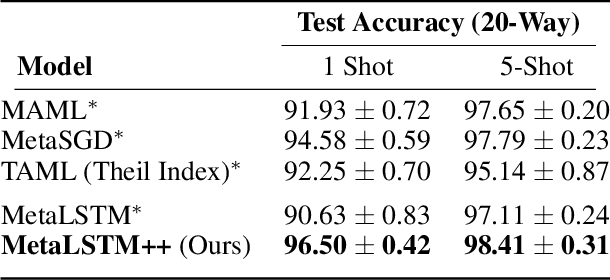
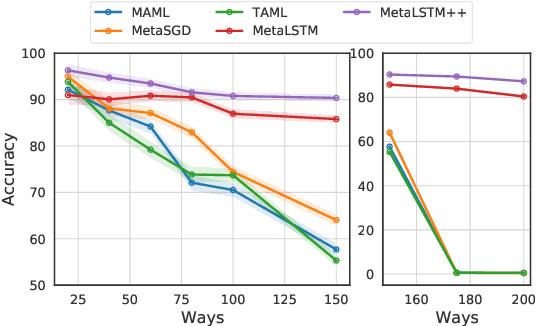
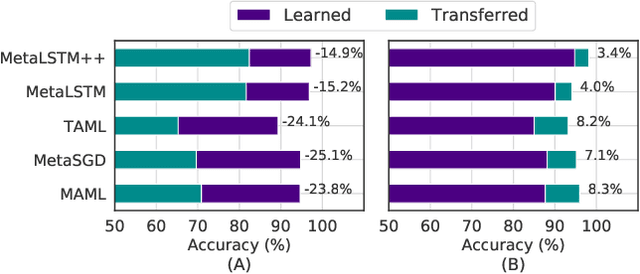
Meta-learning (ML) has emerged as a promising learning method under resource constraints such as few-shot learning. ML approaches typically propose a methodology to learn generalizable models. In this work-in-progress paper, we put the recent ML approaches to a stress test to discover their limitations. Precisely, we measure the performance of ML approaches for few-shot learning against increasing task complexity. Our results show a quick degradation in the performance of initialization strategies for ML (MAML, TAML, and MetaSGD), while surprisingly, approaches that use an optimization strategy (MetaLSTM) perform significantly better. We further demonstrate the effectiveness of an optimization strategy for ML (MetaLSTM++) trained in a MAML manner over a pure optimization strategy. Our experiments also show that the optimization strategies for ML achieve higher transferability from simple to complex tasks.
On Duality Gap as a Measure for Monitoring GAN Training
Dec 12, 2020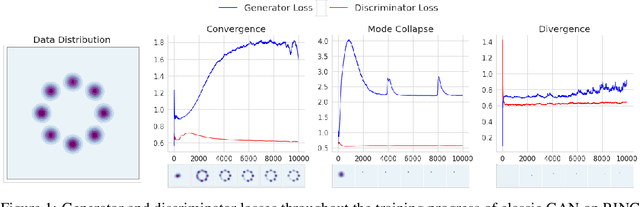
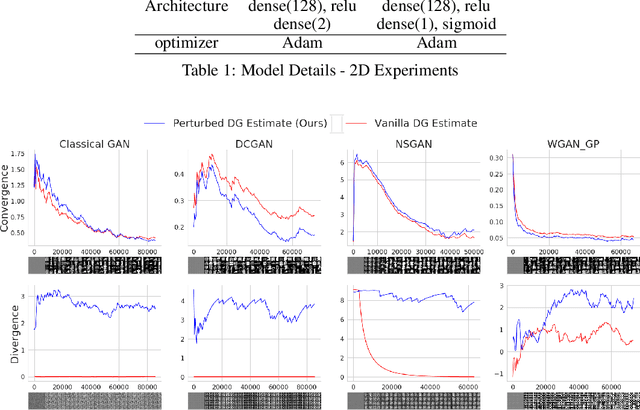
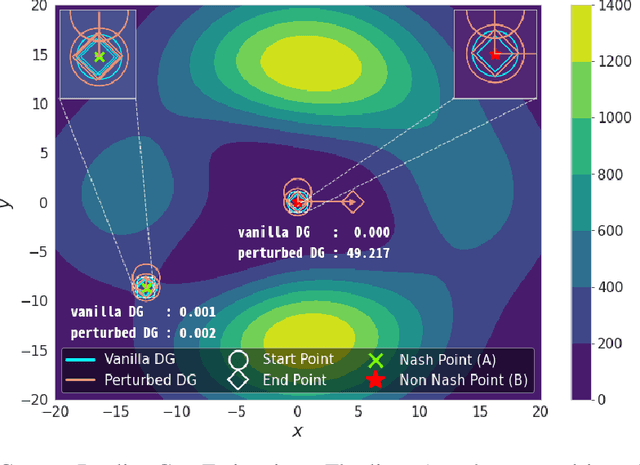
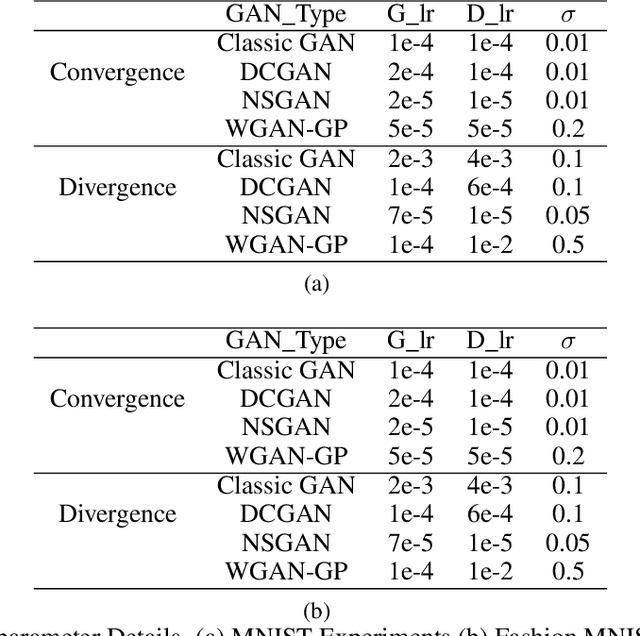
Generative adversarial network (GAN) is among the most popular deep learning models for learning complex data distributions. However, training a GAN is known to be a challenging task. This is often attributed to the lack of correlation between the training progress and the trajectory of the generator and discriminator losses and the need for the GAN's subjective evaluation. A recently proposed measure inspired by game theory - the duality gap, aims to bridge this gap. However, as we demonstrate, the duality gap's capability remains constrained due to limitations posed by its estimation process. This paper presents a theoretical understanding of this limitation and proposes a more dependable estimation process for the duality gap. At the crux of our approach is the idea that local perturbations can help agents in a zero-sum game escape non-Nash saddle points efficiently. Through exhaustive experimentation across GAN models and datasets, we establish the efficacy of our approach in capturing the GAN training progress with minimal increase to the computational complexity. Further, we show that our estimate, with its ability to identify model convergence/divergence, is a potential performance measure that can be used to tune the hyperparameters of a GAN.