 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Attended Meta-Learning for Few-Shot Learning
Paper and Code
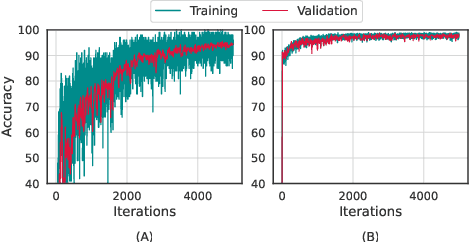
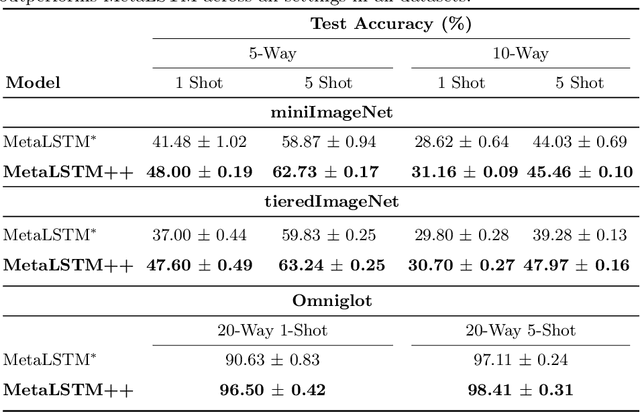
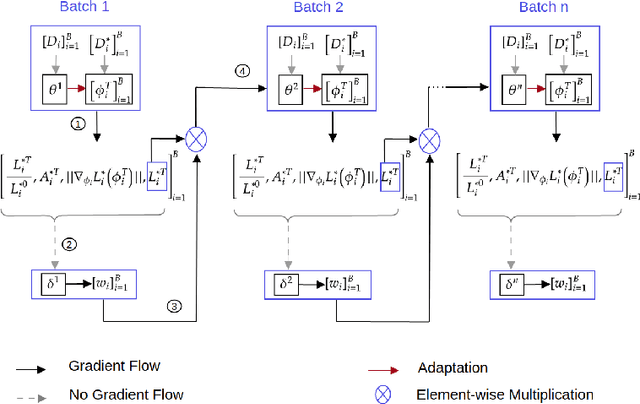
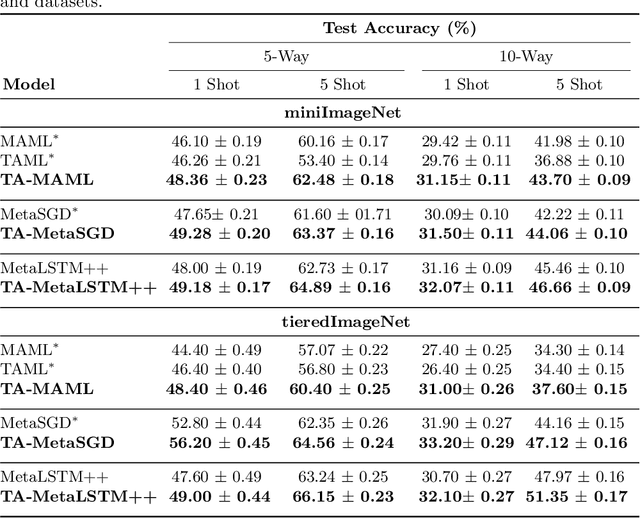
Meta-learning (ML) has emerged as a promising direction in learning models under constrained resource settings like few-shot learning. The popular approaches for ML either learn a generalizable initial model or a generic parametric optimizer through episodic training. The former approaches leverage the knowledge from a batch of tasks to learn an optimal prior. In this work, we study the importance of a batch for ML. Specifically, we first incorporate a batch episodic training regimen to improve the learning of the generic parametric optimizer. We also hypothesize that the common assumption in batch episodic training that each task in a batch has an equal contribution to learning an optimal meta-model need not be true. We propose to weight the tasks in a batch according to their "importance" in improving the meta-model's learning. To this end, we introduce a training curriculum motivated by selective focus in humans, called task attended meta-training, to weight the tasks in a batch. Task attention is a standalone module that can be integrated with any batch episodic training regimen. The comparisons of the models with their non-task-attended counterparts on complex datasets like miniImageNet and tieredImageNet validate its effectiveness.