 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-specific Credibility-aware Multimodal Fusion with Conditional Probabilistic Circuits
Mar 27, 2026Multimodal fusion requires integrating information from multiple sources that may conflict depending on context. Existing fusion approaches typically rely on static assumptions about source reliability, limiting their ability to resolve conflicts when a modality becomes unreliable due to situational factors such as sensor degradation or class-specific corruption. We introduce C$^2$MF, a context-specfic credibility-aware multimodal fusion framework that models per-instance source reliability using a Conditional Probabilistic Circuit (CPC). We formalize instance-level reliability through Context-Specific Information Credibility (CSIC), a KL-divergence-based measure computed exactly from the CPC. CSIC generalizes conventional static credibility estimates as a special case, enabling principled and adaptive reliability assessment. To evaluate robustness under cross-modal conflicts, we propose the Conflict benchmark, in which class-specific corruptions deliberately induce discrepancies between different modalities. Experimental results show that C$^2$MF improves predictive accuracy by up to 29% over static-reliability baselines in high-noise settings, while preserving the interpretability advantages of probabilistic circuit-based fusion.
Geometry-Aware Probabilistic Circuits via Voronoi Tessellations
Mar 12, 2026Probabilistic circuits (PCs) enable exact and tractable inference but employ data independent mixture weights that limit their ability to capture local geometry of the data manifold. We propose Voronoi tessellations (VT) as a natural way to incorporate geometric structure directly into the sum nodes of a PC. However, naïvely introducing such structure breaks tractability. We formalize this incompatibility and develop two complementary solutions: (1) an approximate inference framework that provides guaranteed lower and upper bounds for inference, and (2) a structural condition for VT under which exact tractable inference is recovered. Finally, we introduce a differentiable relaxation for VT that enables gradient-based learning and empirically validate the resulting approach on standard density estimation tasks.
Tractable Sharpness-Aware Learning of Probabilistic Circuits
Aug 07, 2025Probabilistic Circuits (PCs) are a class of generative models that allow exact and tractable inference for a wide range of queries. While recent developments have enabled the learning of deep and expressive PCs, this increased capacity can often lead to overfitting, especially when data is limited. We analyze PC overfitting from a log-likelihood-landscape perspective and show that it is often caused by convergence to sharp optima that generalize poorly. Inspired by sharpness aware minimization in neural networks, we propose a Hessian-based regularizer for training PCs. As a key contribution, we show that the trace of the Hessian of the log-likelihood-a sharpness proxy that is typically intractable in deep neural networks-can be computed efficiently for PCs. Minimizing this Hessian trace induces a gradient-norm-based regularizer that yields simple closed-form parameter updates for EM, and integrates seamlessly with gradient based learning methods. Experiments on synthetic and real-world datasets demonstrate that our method consistently guides PCs toward flatter minima, improves generalization performance.
A Unified Framework for Human-Allied Learning of Probabilistic Circuits
May 03, 2024



Probabilistic Circuits (PCs) have emerged as an efficient framework for representing and learning complex probability distributions. Nevertheless, the existing body of research on PCs predominantly concentrates on data-driven parameter learning, often neglecting the potential of knowledge-intensive learning, a particular issue in data-scarce/knowledge-rich domains such as healthcare. To bridge this gap, we propose a novel unified framework that can systematically integrate diverse domain knowledge into the parameter learning process of PCs. Experiments on several benchmarks as well as real world datasets show that our proposed framework can both effectively and efficiently leverage domain knowledge to achieve superior performance compared to purely data-driven learning approaches.
Credibility-Aware Multi-Modal Fusion Using Probabilistic Circuits
Mar 05, 2024
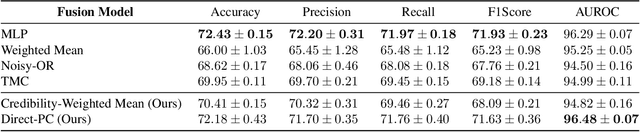
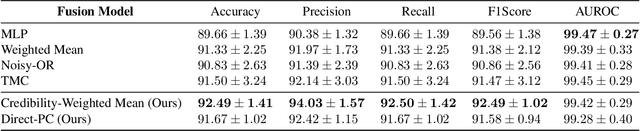
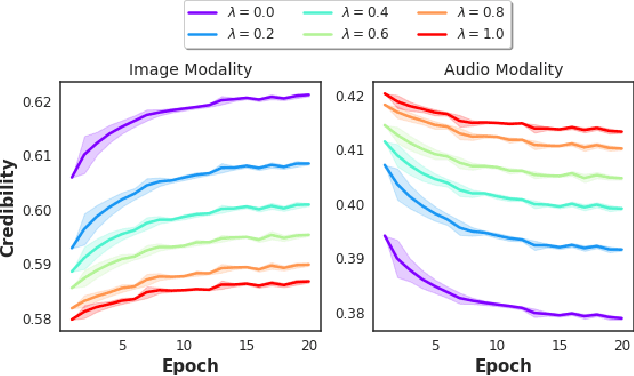
We consider the problem of late multi-modal fusion for discriminative learning. Motivated by noisy, multi-source domains that require understanding the reliability of each data source, we explore the notion of credibility in the context of multi-modal fusion. We propose a combination function that uses probabilistic circuits (PCs) to combine predictive distributions over individual modalities. We also define a probabilistic measure to evaluate the credibility of each modality via inference queries over the PC. Our experimental evaluation demonstrates that our fusion method can reliably infer credibility while maintaining competitive performance with the state-of-the-art.
Building Expressive and Tractable Probabilistic Generative Models: A Review
Feb 01, 2024We present a comprehensive survey of the advancements and techniques in the field of tractable probabilistic generative modeling, primarily focusing on Probabilistic Circuits (PCs). We provide a unified perspective on the inherent trade-offs between expressivity and the tractability, highlighting the design principles and algorithmic extensions that have enabled building expressive and efficient PCs, and provide a taxonomy of the field. We also discuss recent efforts to build deep and hybrid PCs by fusing notions from deep neural models, and outline the challenges and open questions that can guide future research in this evolving field.
VQ-Flows: Vector Quantized Local Normalizing Flows
Mar 22, 2022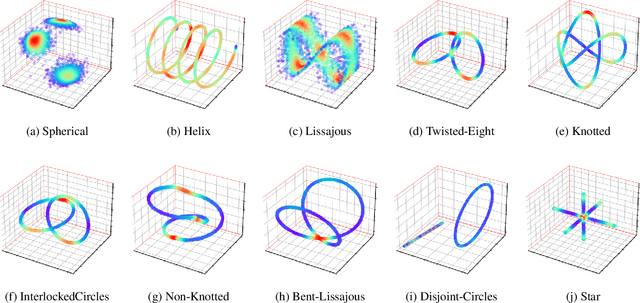
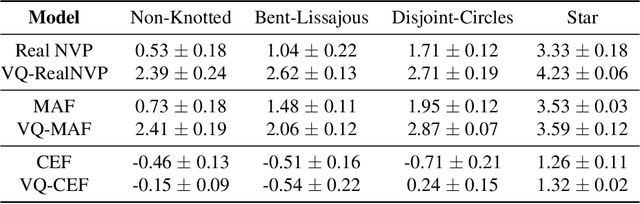
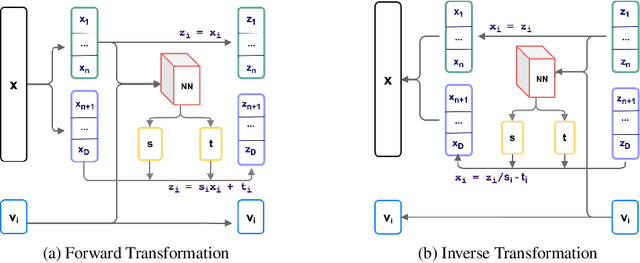
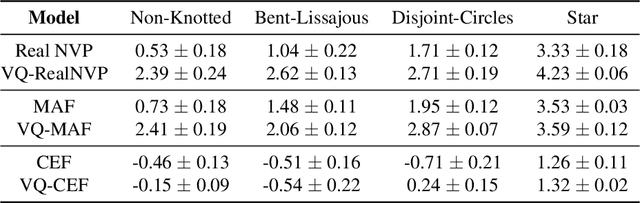
Normalizing flows provide an elegant approach to generative modeling that allows for efficient sampling and exact density evaluation of unknown data distributions. However, current techniques have significant limitations in their expressivity when the data distribution is supported on a low-dimensional manifold or has a non-trivial topology. We introduce a novel statistical framework for learning a mixture of local normalizing flows as "chart maps" over the data manifold. Our framework augments the expressivity of recent approaches while preserving the signature property of normalizing flows, that they admit exact density evaluation. We learn a suitable atlas of charts for the data manifold via a vector quantized auto-encoder (VQ-AE) and the distributions over them using a conditional flow. We validate experimentally that our probabilistic framework enables existing approaches to better model data distributions over complex manifolds.
Attentive Contractive Flow: Improved Contractive Flows with Lipschitz-constrained Self-Attention
Sep 24, 2021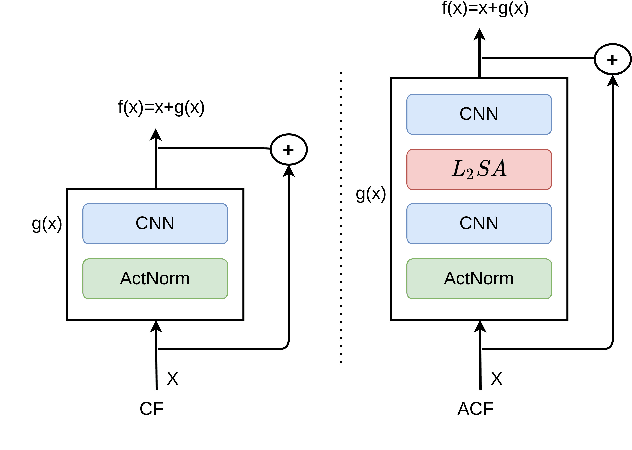

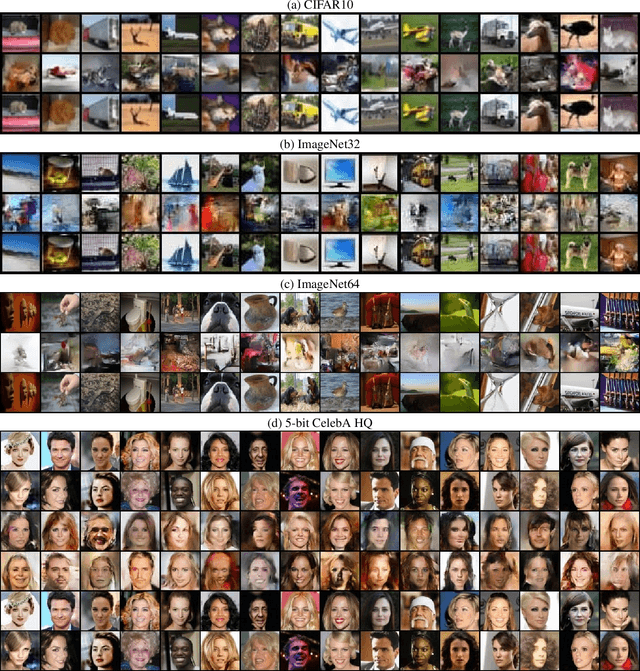
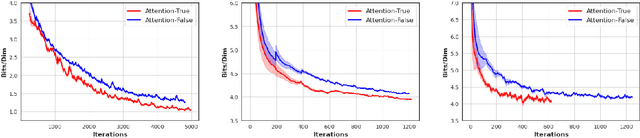
Normalizing flows provide an elegant method for obtaining tractable density estimates from distributions by using invertible transformations. The main challenge is to improve the expressivity of the models while keeping the invertibility constraints intact. We propose to do so via the incorporation of localized self-attention. However, conventional self-attention mechanisms don't satisfy the requirements to obtain invertible flows and can't be naively incorporated into normalizing flows. To address this, we introduce a novel approach called Attentive Contractive Flow (ACF) which utilizes a special category of flow-based generative models - contractive flows. We demonstrate that ACF can be introduced into a variety of state of the art flow models in a plug-and-play manner. This is demonstrated to not only improve the representation power of these models (improving on the bits per dim metric), but also to results in significantly faster convergence in training them. Qualitative results, including interpolations between test images, demonstrate that samples are more realistic and capture local correlations in the data well. We evaluate the results further by performing perturbation analysis using AWGN demonstrating that ACF models (especially the dot-product variant) show better and more consistent resilience to additive noise.
Task Attended Meta-Learning for Few-Shot Learning
Jun 20, 2021
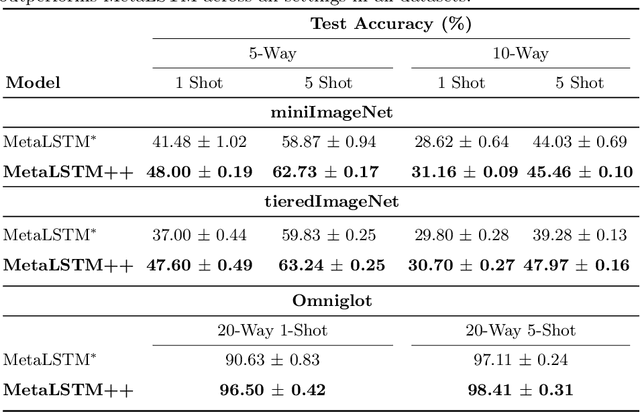
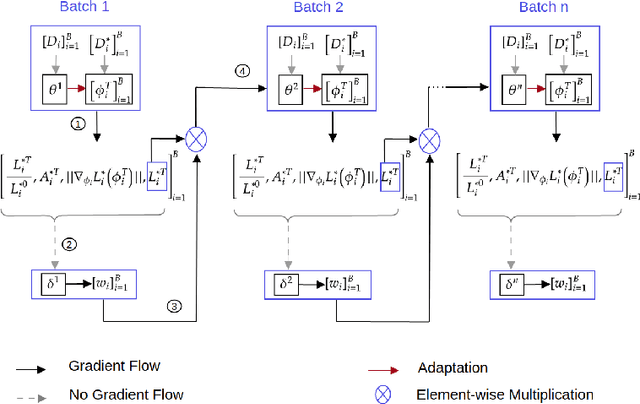
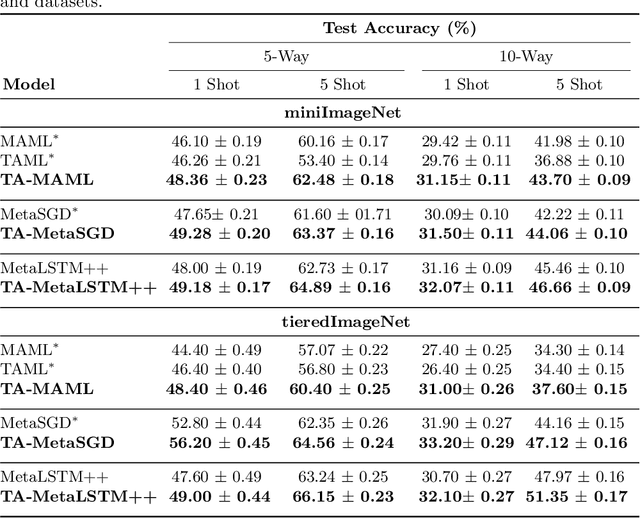
Meta-learning (ML) has emerged as a promising direction in learning models under constrained resource settings like few-shot learning. The popular approaches for ML either learn a generalizable initial model or a generic parametric optimizer through episodic training. The former approaches leverage the knowledge from a batch of tasks to learn an optimal prior. In this work, we study the importance of a batch for ML. Specifically, we first incorporate a batch episodic training regimen to improve the learning of the generic parametric optimizer. We also hypothesize that the common assumption in batch episodic training that each task in a batch has an equal contribution to learning an optimal meta-model need not be true. We propose to weight the tasks in a batch according to their "importance" in improving the meta-model's learning. To this end, we introduce a training curriculum motivated by selective focus in humans, called task attended meta-training, to weight the tasks in a batch. Task attention is a standalone module that can be integrated with any batch episodic training regimen. The comparisons of the models with their non-task-attended counterparts on complex datasets like miniImageNet and tieredImageNet validate its effectiveness.
Characterizing GAN Convergence Through Proximal Duality Gap
May 11, 2021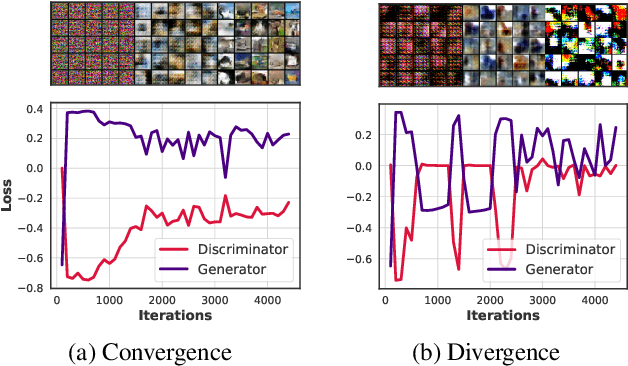
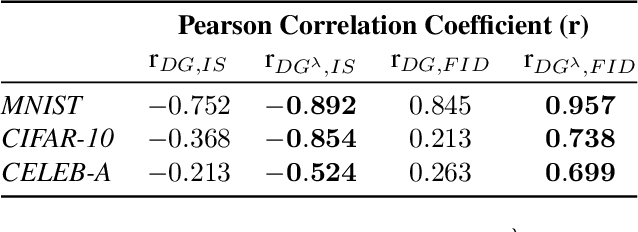
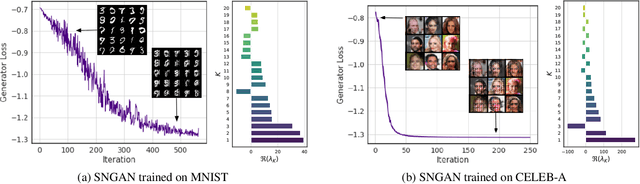
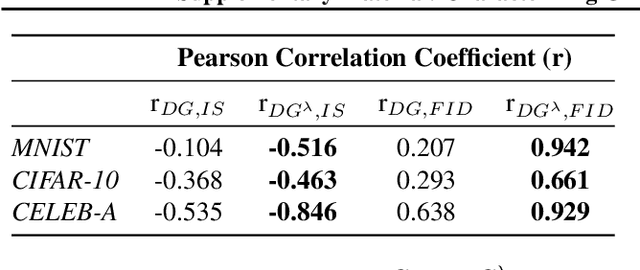
Despite the accomplishments of Generative Adversarial Networks (GANs) in modeling data distributions, training them remains a challenging task. A contributing factor to this difficulty is the non-intuitive nature of the GAN loss curves, which necessitates a subjective evaluation of the generated output to infer training progress. Recently, motivated by game theory, duality gap has been proposed as a domain agnostic measure to monitor GAN training. However, it is restricted to the setting when the GAN converges to a Nash equilibrium. But GANs need not always converge to a Nash equilibrium to model the data distribution. In this work, we extend the notion of duality gap to proximal duality gap that is applicable to the general context of training GANs where Nash equilibria may not exist. We show theoretically that the proximal duality gap is capable of monitoring the convergence of GANs to a wider spectrum of equilibria that subsumes Nash equilibria. We also theoretically establish the relationship between the proximal duality gap and the divergence between the real and generated data distributions for different GAN formulations. Our results provide new insights into the nature of GAN convergence. Finally, we validate experimentally the usefulness of proximal duality gap for monitoring and influencing GAN training.