 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRISSOLE: Parameter-efficient Diffusion Models via Block-wise Generation and Retrieval-Guidance
Sep 02, 2024



Diffusion-based models demonstrate impressive generation capabilities. However, they also have a massive number of parameters, resulting in enormous model sizes, thus making them unsuitable for deployment on resource-constraint devices. Block-wise generation can be a promising alternative for designing compact-sized (parameter-efficient) deep generative models since the model can generate one block at a time instead of generating the whole image at once. However, block-wise generation is also considerably challenging because ensuring coherence across generated blocks can be non-trivial. To this end, we design a retrieval-augmented generation (RAG) approach and leverage the corresponding blocks of the images retrieved by the RAG module to condition the training and generation stages of a block-wise denoising diffusion model. Our conditioning schemes ensure coherence across the different blocks during training and, consequently, during generation. While we showcase our approach using the latent diffusion model (LDM) as the base model, it can be used with other variants of denoising diffusion models. We validate the solution of the coherence problem through the proposed approach by reporting substantive experiments to demonstrate our approach's effectiveness in compact model size and excellent generation quality.
VERSE: Virtual-Gradient Aware Streaming Lifelong Learning with Anytime Inference
Sep 15, 2023
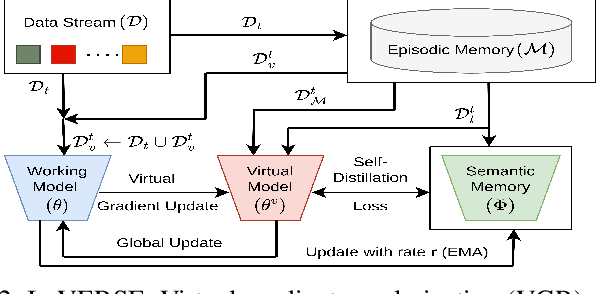
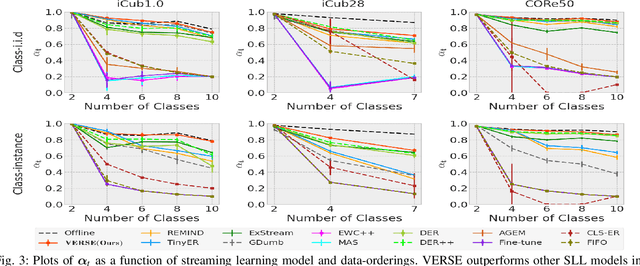
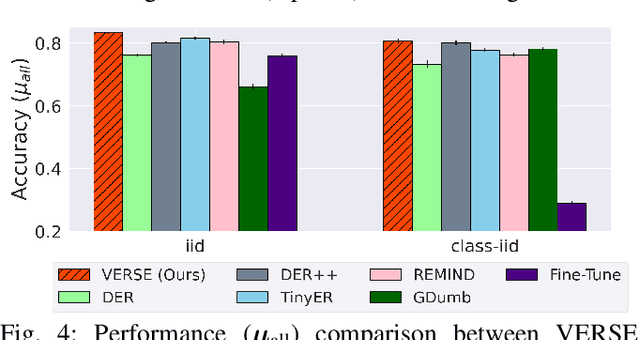
Lifelong learning, also referred to as continual learning, is the problem of training an AI agent continuously while also preventing it from forgetting its previously acquired knowledge. Most of the existing methods primarily focus on lifelong learning within a static environment and lack the ability to mitigate forgetting in a quickly-changing dynamic environment. Streaming lifelong learning is a challenging setting of lifelong learning with the goal of continuous learning in a dynamic non-stationary environment without forgetting. We introduce a novel approach to lifelong learning, which is streaming, requires a single pass over the data, can learn in a class-incremental manner, and can be evaluated on-the-fly (anytime inference). To accomplish these, we propose virtual gradients for continual representation learning to prevent catastrophic forgetting and leverage an exponential-moving-average-based semantic memory to further enhance performance. Extensive experiments on diverse datasets demonstrate our method's efficacy and superior performance over existing methods.
DiffuseVAE: Efficient, Controllable and High-Fidelity Generation from Low-Dimensional Latents
Jan 02, 2022

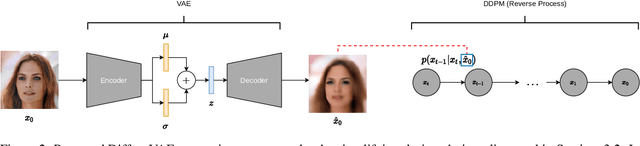
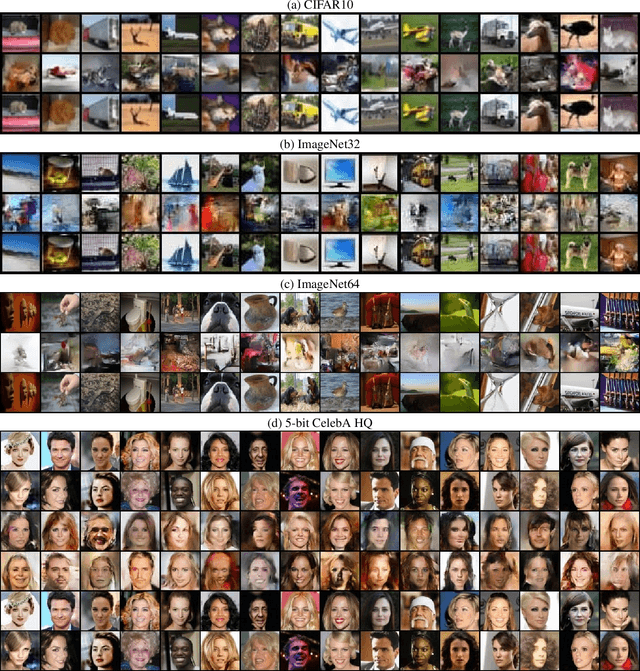
Diffusion Probabilistic models have been shown to generate state-of-the-art results on several competitive image synthesis benchmarks but lack a low-dimensional, interpretable latent space, and are slow at generation. On the other hand, Variational Autoencoders (VAEs) typically have access to a low-dimensional latent space but exhibit poor sample quality. Despite recent advances, VAEs usually require high-dimensional hierarchies of the latent codes to generate high-quality samples. We present DiffuseVAE, a novel generative framework that integrates VAE within a diffusion model framework, and leverage this to design a novel conditional parameterization for diffusion models. We show that the resulting model can improve upon the unconditional diffusion model in terms of sampling efficiency while also equipping diffusion models with the low-dimensional VAE inferred latent code. Furthermore, we show that the proposed model can generate high-resolution samples and exhibits synthesis quality comparable to state-of-the-art models on standard benchmarks. Lastly, we show that the proposed method can be used for controllable image synthesis and also exhibits out-of-the-box capabilities for downstream tasks like image super-resolution and denoising. For reproducibility, our source code is publicly available at \url{https://github.com/kpandey008/DiffuseVAE}.
Attentive Contractive Flow: Improved Contractive Flows with Lipschitz-constrained Self-Attention
Sep 24, 2021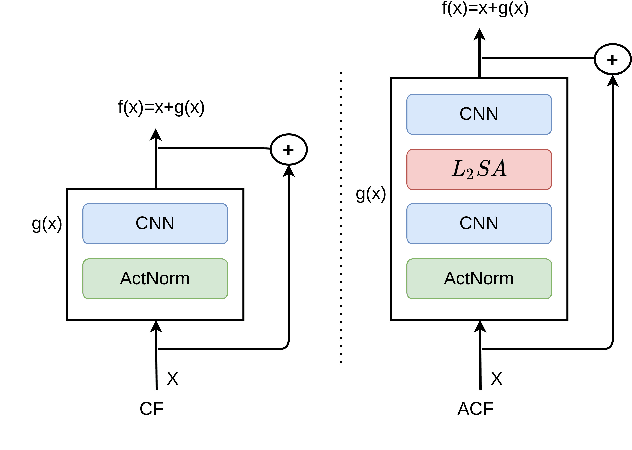

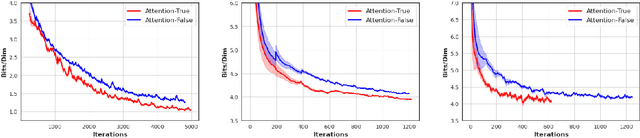
Normalizing flows provide an elegant method for obtaining tractable density estimates from distributions by using invertible transformations. The main challenge is to improve the expressivity of the models while keeping the invertibility constraints intact. We propose to do so via the incorporation of localized self-attention. However, conventional self-attention mechanisms don't satisfy the requirements to obtain invertible flows and can't be naively incorporated into normalizing flows. To address this, we introduce a novel approach called Attentive Contractive Flow (ACF) which utilizes a special category of flow-based generative models - contractive flows. We demonstrate that ACF can be introduced into a variety of state of the art flow models in a plug-and-play manner. This is demonstrated to not only improve the representation power of these models (improving on the bits per dim metric), but also to results in significantly faster convergence in training them. Qualitative results, including interpolations between test images, demonstrate that samples are more realistic and capture local correlations in the data well. We evaluate the results further by performing perturbation analysis using AWGN demonstrating that ACF models (especially the dot-product variant) show better and more consistent resilience to additive noise.