 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOT-MoE: Differentiable Optimal Transport for MoEfication
Jun 01, 2026The scaling of Large Language Models (LLMs) has driven significant performance gains but created substantial challenges in inference efficiency. While Mixture of Experts (MoEs) architectures address this by decoupling model size from inference cost, training MoEs from scratch is often unstable and compute intensive. Conversion of pre-trained dense models into sparse MoEs has emerged as an alternative solution; however, existing methods typically rely on heuristic neuron clustering or random splitting to partition the Feed-Forward Network (FFN) into experts. In this work, we propose DOT-MoE, a novel framework that formulates the decomposition of dense layers as a Differentiable Optimal Transport (DOT) problem. Instead of static heuristics, we model neuron assignment as a balanced transport problem, utilizing differentiable Sinkhorn-Knopp iterations to enforce strict expert capacity constraints. Furthermore, we utilize Straight-Through Estimators (STE) to jointly learn the discrete neuron-to-expert assignment and the token-to-expert routing policy end-to-end. Extensive experiments across multiple architectures and benchmarks demonstrate that DOT-MoE significantly outperforms structured pruning, heuristic clustering, and random-split baselines, retaining 90% of the original dense model's performance while reducing active parameters by 50%.
Overview of TREC 2025 Biomedical Generative Retrieval (BioGen) Track
Mar 23, 2026Recent advances in large language models (LLMs) have made significant progress across multiple biomedical tasks, including biomedical question answering, lay-language summarization of the biomedical literature, and clinical note summarization. These models have demonstrated strong capabilities in processing and synthesizing complex biomedical information and in generating fluent, human-like responses. Despite these advancements, hallucinations or confabulations remain key challenges when using LLMs in biomedical and other high-stakes domains. Inaccuracies may be particularly harmful in high-risk situations, such as medical question answering, making clinical decisions, or appraising biomedical research. Studies on the evaluation of the LLMs' abilities to ground generated statements in verifiable sources have shown that models perform significantly
S2D: Selective Spectral Decay for Quantization-Friendly Conditioning of Neural Activations
Feb 16, 2026Activation outliers in large-scale transformer models pose a fundamental challenge to model quantization, creating excessively large ranges that cause severe accuracy drops during quantization. We empirically observe that outlier severity intensifies with pre-training scale (e.g., progressing from CLIP to the more extensively trained SigLIP and SigLIP2). Through theoretical analysis as well as empirical correlation studies, we establish the direct link between these activation outliers and dominant singular values of the weights. Building on this insight, we propose Selective Spectral Decay ($S^2D$), a geometrically-principled conditioning method that surgically regularizes only the weight components corresponding to the largest singular values during fine-tuning. Through extensive experiments, we demonstrate that $S^2D$ significantly reduces activation outliers and produces well-conditioned representations that are inherently quantization-friendly. Models trained with $S^2D$ achieve up to 7% improved PTQ accuracy on ImageNet under W4A4 quantization and 4% gains when combined with QAT. These improvements also generalize across downstream tasks and vision-language models, enabling the scaling of increasingly large and rigorously trained models without sacrificing deployment efficiency.
BioACE: An Automated Framework for Biomedical Answer and Citation Evaluations
Feb 04, 2026With the increasing use of large language models (LLMs) for generating answers to biomedical questions, it is crucial to evaluate the quality of the generated answers and the references provided to support the facts in the generated answers. Evaluation of text generated by LLMs remains a challenge for question answering, retrieval-augmented generation (RAG), summarization, and many other natural language processing tasks in the biomedical domain, due to the requirements of expert assessment to verify consistency with the scientific literature and complex medical terminology. In this work, we propose BioACE, an automated framework for evaluating biomedical answers and citations against the facts stated in the answers. The proposed BioACE framework considers multiple aspects, including completeness, correctness, precision, and recall, in relation to the ground-truth nuggets for answer evaluation. We developed automated approaches to evaluate each of the aforementioned aspects and performed extensive experiments to assess and analyze their correlation with human evaluations. In addition, we considered multiple existing approaches, such as natural language inference (NLI) and pre-trained language models and LLMs, to evaluate the quality of evidence provided to support the generated answers in the form of citations into biomedical literature. With the detailed experiments and analysis, we provide the best approaches for biomedical answer and citation evaluation as a part of BioACE (https://github.com/deepaknlp/BioACE) evaluation package.
A Dataset and Benchmark for Consumer Healthcare Question Summarization
Dec 29, 2025The quest for seeking health information has swamped the web with consumers health-related questions. Generally, consumers use overly descriptive and peripheral information to express their medical condition or other healthcare needs, contributing to the challenges of natural language understanding. One way to address this challenge is to summarize the questions and distill the key information of the original question. Recently, large-scale datasets have significantly propelled the development of several summarization tasks, such as multi-document summarization and dialogue summarization. However, a lack of a domain-expert annotated dataset for the consumer healthcare questions summarization task inhibits the development of an efficient summarization system. To address this issue, we introduce a new dataset, CHQ-Sum,m that contains 1507 domain-expert annotated consumer health questions and corresponding summaries. The dataset is derived from the community question answering forum and therefore provides a valuable resource for understanding consumer health-related posts on social media. We benchmark the dataset on multiple state-of-the-art summarization models to show the effectiveness of the dataset
Wavelet-Accelerated Physics-Informed Quantum Neural Network for Multiscale Partial Differential Equations
Dec 09, 2025This work proposes a wavelet-based physics-informed quantum neural network framework to efficiently address multiscale partial differential equations that involve sharp gradients, stiffness, rapid local variations, and highly oscillatory behavior. Traditional physics-informed neural networks (PINNs) have demonstrated substantial potential in solving differential equations, and their quantum counterparts, quantum-PINNs, exhibit enhanced representational capacity with fewer trainable parameters. However, both approaches face notable challenges in accurately solving multiscale features. Furthermore, their reliance on automatic differentiation for constructing loss functions introduces considerable computational overhead, resulting in longer training times. To overcome these challenges, we developed a wavelet-accelerated physics-informed quantum neural network that eliminates the need for automatic differentiation, significantly reducing computational complexity. The proposed framework incorporates the multiresolution property of wavelets within the quantum neural network architecture, thereby enhancing the network's ability to effectively capture both local and global features of multiscale problems. Numerical experiments demonstrate that our proposed method achieves superior accuracy while requiring less than five percent of the trainable parameters compared to classical wavelet-based PINNs, resulting in faster convergence. Moreover, it offers a speedup of three to five times compared to existing quantum PINNs, highlighting the potential of the proposed approach for efficiently solving challenging multiscale and oscillatory problems.
MoEMoE: Question Guided Dense and Scalable Sparse Mixture-of-Expert for Multi-source Multi-modal Answering
Mar 08, 2025Question Answering (QA) and Visual Question Answering (VQA) are well-studied problems in the language and vision domain. One challenging scenario involves multiple sources of information, each of a different modality, where the answer to the question may exist in one or more sources. This scenario contains richer information but is highly complex to handle. In this work, we formulate a novel question-answer generation (QAG) framework in an environment containing multi-source, multimodal information. The answer may belong to any or all sources; therefore, selecting the most prominent answer source or an optimal combination of all sources for a given question is challenging. To address this issue, we propose a question-guided attention mechanism that learns attention across multiple sources and decodes this information for robust and unbiased answer generation. To learn attention within each source, we introduce an explicit alignment between questions and various information sources, which facilitates identifying the most pertinent parts of the source information relative to the question. Scalability in handling diverse questions poses a challenge. We address this by extending our model to a sparse mixture-of-experts (sparse-MoE) framework, enabling it to handle thousands of question types. Experiments on T5 and Flan-T5 using three datasets demonstrate the model's efficacy, supported by ablation studies.
Overview of TREC 2024 Medical Video Question Answering (MedVidQA) Track
Dec 15, 2024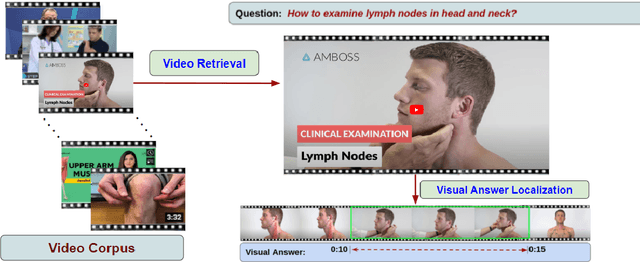
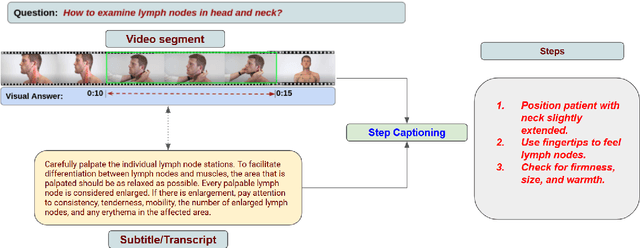
One of the key goals of artificial intelligence (AI) is the development of a multimodal system that facilitates communication with the visual world (image and video) using a natural language query. Earlier works on medical question answering primarily focused on textual and visual (image) modalities, which may be inefficient in answering questions requiring demonstration. In recent years, significant progress has been achieved due to the introduction of large-scale language-vision datasets and the development of efficient deep neural techniques that bridge the gap between language and visual understanding. Improvements have been made in numerous vision-and-language tasks, such as visual captioning visual question answering, and natural language video localization. Most of the existing work on language vision focused on creating datasets and developing solutions for open-domain applications. We believe medical videos may provide the best possible answers to many first aid, medical emergency, and medical education questions. With increasing interest in AI to support clinical decision-making and improve patient engagement, there is a need to explore such challenges and develop efficient algorithms for medical language-video understanding and generation. Toward this, we introduced new tasks to foster research toward designing systems that can understand medical videos to provide visual answers to natural language questions, and are equipped with multimodal capability to generate instruction steps from the medical video. These tasks have the potential to support the development of sophisticated downstream applications that can benefit the public and medical professionals.
Overview of TREC 2024 Biomedical Generative Retrieval (BioGen) Track
Nov 27, 2024



With the advancement of large language models (LLMs), the biomedical domain has seen significant progress and improvement in multiple tasks such as biomedical question answering, lay language summarization of the biomedical literature, clinical note summarization, etc. However, hallucinations or confabulations remain one of the key challenges when using LLMs in the biomedical and other domains. Inaccuracies may be particularly harmful in high-risk situations, such as making clinical decisions or appraising biomedical research. Studies on the evaluation of the LLMs' abilities to ground generated statements in verifiable sources have shown that models perform significantly worse on lay-user generated questions, and often fail to reference relevant sources. This can be problematic when those seeking information want evidence from studies to back up the claims from LLMs[3]. Unsupported statements are a major barrier to using LLMs in any applications that may affect health. Methods for grounding generated statements in reliable sources along with practical evaluation approaches are needed to overcome this barrier. Towards this, in our pilot task organized at TREC 2024, we introduced the task of reference attribution as a means to mitigate the generation of false statements by LLMs answering biomedical questions.
Enhancing Deep Learning based RMT Data Inversion using Gaussian Random Field
Oct 22, 2024Deep learning (DL) methods have emerged as a powerful tool for the inversion of geophysical data. When applied to field data, these models often struggle without additional fine-tuning of the network. This is because they are built on the assumption that the statistical patterns in the training and test datasets are the same. To address this, we propose a DL-based inversion scheme for Radio Magnetotelluric data where the subsurface resistivity models are generated using Gaussian Random Fields (GRF). The network's generalization ability was tested with an out-of-distribution (OOD) dataset comprising a homogeneous background and various rectangular-shaped anomalous bodies. After end-to-end training with the GRF dataset, the pre-trained network successfully identified anomalies in the OOD dataset. Synthetic experiments confirmed that the GRF dataset enhances generalization compared to a homogeneous background OOD dataset. The network accurately recovered structures in a checkerboard resistivity model, and demonstrated robustness to noise, outperforming traditional gradient-based methods. Finally, the developed scheme is tested using exemplary field data from a waste site near Roorkee, India. The proposed scheme enhances generalization in a data-driven supervised learning framework, suggesting a promising direction for OOD generalization in DL methods.