 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable User Satisfaction Estimation for Conversational Systems with Large Language Models
Mar 19, 2024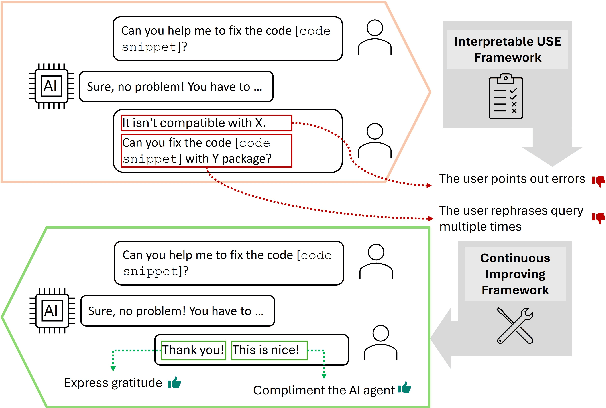
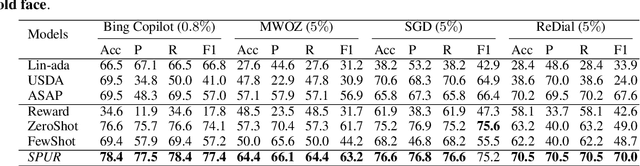
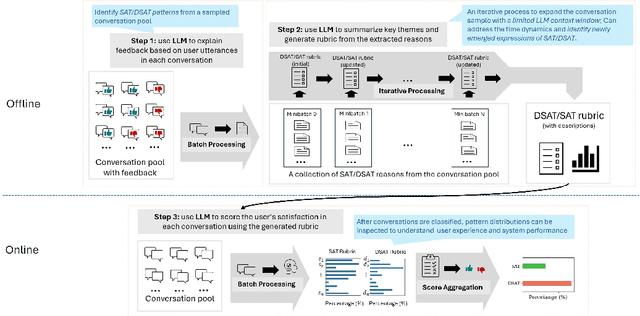
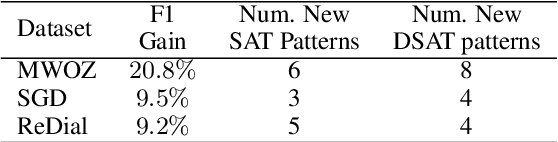
Accurate and interpretable user satisfaction estimation (USE) is critical for understanding, evaluating, and continuously improving conversational systems. Users express their satisfaction or dissatisfaction with diverse conversational patterns in both general-purpose (ChatGPT and Bing Copilot) and task-oriented (customer service chatbot) conversational systems. Existing approaches based on featurized ML models or text embeddings fall short in extracting generalizable patterns and are hard to interpret. In this work, we show that LLMs can extract interpretable signals of user satisfaction from their natural language utterances more effectively than embedding-based approaches. Moreover, an LLM can be tailored for USE via an iterative prompting framework using supervision from labeled examples. The resulting method, Supervised Prompting for User satisfaction Rubrics (SPUR), not only has higher accuracy but is more interpretable as it scores user satisfaction via learned rubrics with a detailed breakdown.
TnT-LLM: Text Mining at Scale with Large Language Models
Mar 18, 2024Transforming unstructured text into structured and meaningful forms, organized by useful category labels, is a fundamental step in text mining for downstream analysis and application. However, most existing methods for producing label taxonomies and building text-based label classifiers still rely heavily on domain expertise and manual curation, making the process expensive and time-consuming. This is particularly challenging when the label space is under-specified and large-scale data annotations are unavailable. In this paper, we address these challenges with Large Language Models (LLMs), whose prompt-based interface facilitates the induction and use of large-scale pseudo labels. We propose TnT-LLM, a two-phase framework that employs LLMs to automate the process of end-to-end label generation and assignment with minimal human effort for any given use-case. In the first phase, we introduce a zero-shot, multi-stage reasoning approach which enables LLMs to produce and refine a label taxonomy iteratively. In the second phase, LLMs are used as data labelers that yield training samples so that lightweight supervised classifiers can be reliably built, deployed, and served at scale. We apply TnT-LLM to the analysis of user intent and conversational domain for Bing Copilot (formerly Bing Chat), an open-domain chat-based search engine. Extensive experiments using both human and automatic evaluation metrics demonstrate that TnT-LLM generates more accurate and relevant label taxonomies when compared against state-of-the-art baselines, and achieves a favorable balance between accuracy and efficiency for classification at scale. We also share our practical experiences and insights on the challenges and opportunities of using LLMs for large-scale text mining in real-world applications.
PEARL: Personalizing Large Language Model Writing Assistants with Generation-Calibrated Retrievers
Nov 15, 2023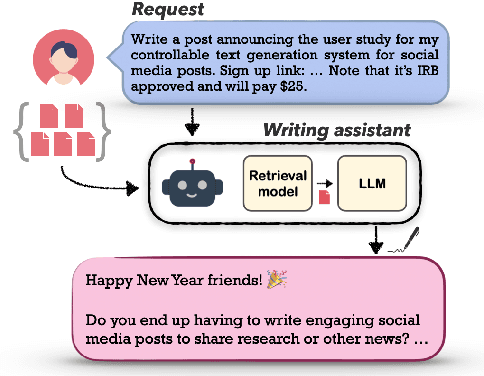
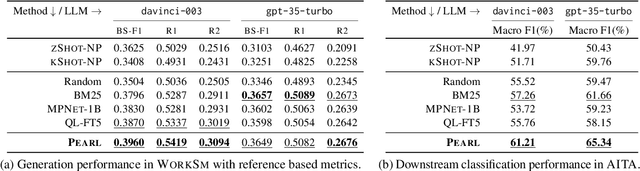
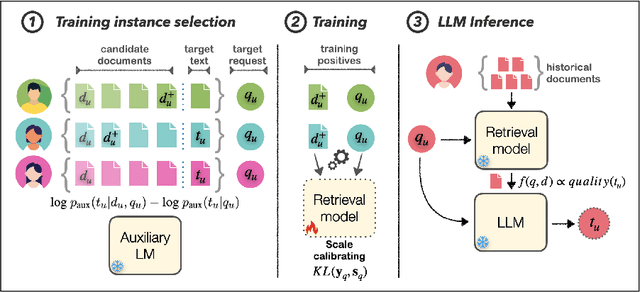

Powerful large language models have facilitated the development of writing assistants that promise to significantly improve the quality and efficiency of composition and communication. However, a barrier to effective assistance is the lack of personalization in LLM outputs to the author's communication style and specialized knowledge. In this paper, we address this challenge by proposing PEARL, a retrieval-augmented LLM writing assistant personalized with a generation-calibrated retriever. Our retriever is trained to select historic user-authored documents for prompt augmentation, such that they are likely to best personalize LLM generations for a user request. We propose two key novelties for training our retriever: 1) A training data selection method that identifies user requests likely to benefit from personalization and documents that provide that benefit; and 2) A scale-calibrating KL-divergence objective that ensures that our retriever closely tracks the benefit of a document for personalized generation. We demonstrate the effectiveness of PEARL in generating personalized workplace social media posts and Reddit comments. Finally, we showcase the potential of a generation-calibrated retriever to double as a performance predictor and further improve low-quality generations via LLM chaining.
S3-DST: Structured Open-Domain Dialogue Segmentation and State Tracking in the Era of LLMs
Sep 16, 2023
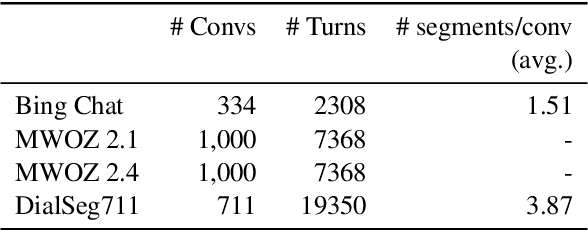

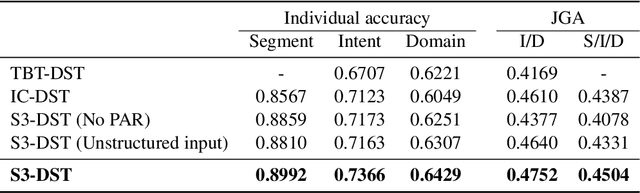
The traditional Dialogue State Tracking (DST) problem aims to track user preferences and intents in user-agent conversations. While sufficient for task-oriented dialogue systems supporting narrow domain applications, the advent of Large Language Model (LLM)-based chat systems has introduced many real-world intricacies in open-domain dialogues. These intricacies manifest in the form of increased complexity in contextual interactions, extended dialogue sessions encompassing a diverse array of topics, and more frequent contextual shifts. To handle these intricacies arising from evolving LLM-based chat systems, we propose joint dialogue segmentation and state tracking per segment in open-domain dialogue systems. Assuming a zero-shot setting appropriate to a true open-domain dialogue system, we propose S3-DST, a structured prompting technique that harnesses Pre-Analytical Recollection, a novel grounding mechanism we designed for improving long context tracking. To demonstrate the efficacy of our proposed approach in joint segmentation and state tracking, we evaluate S3-DST on a proprietary anonymized open-domain dialogue dataset, as well as publicly available DST and segmentation datasets. Across all datasets and settings, S3-DST consistently outperforms the state-of-the-art, demonstrating its potency and robustness the next generation of LLM-based chat systems.
Using Large Language Models to Generate, Validate, and Apply User Intent Taxonomies
Sep 14, 2023



Log data can reveal valuable information about how users interact with web search services, what they want, and how satisfied they are. However, analyzing user intents in log data is not easy, especially for new forms of web search such as AI-driven chat. To understand user intents from log data, we need a way to label them with meaningful categories that capture their diversity and dynamics. Existing methods rely on manual or ML-based labeling, which are either expensive or inflexible for large and changing datasets. We propose a novel solution using large language models (LLMs), which can generate rich and relevant concepts, descriptions, and examples for user intents. However, using LLMs to generate a user intent taxonomy and apply it to do log analysis can be problematic for two main reasons: such a taxonomy is not externally validated, and there may be an undesirable feedback loop. To overcome these issues, we propose a new methodology with human experts and assessors to verify the quality of the LLM-generated taxonomy. We also present an end-to-end pipeline that uses an LLM with human-in-the-loop to produce, refine, and use labels for user intent analysis in log data. Our method offers a scalable and adaptable way to analyze user intents in web-scale log data with minimal human effort. We demonstrate its effectiveness by uncovering new insights into user intents from search and chat logs from Bing.
CascadER: Cross-Modal Cascading for Knowledge Graph Link Prediction
May 16, 2022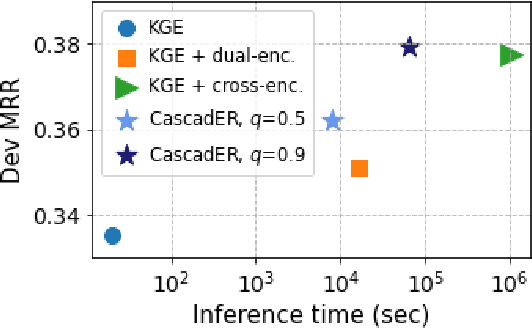
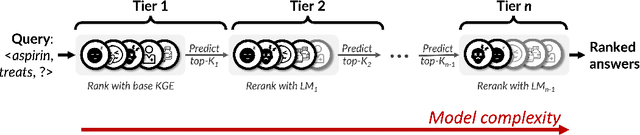
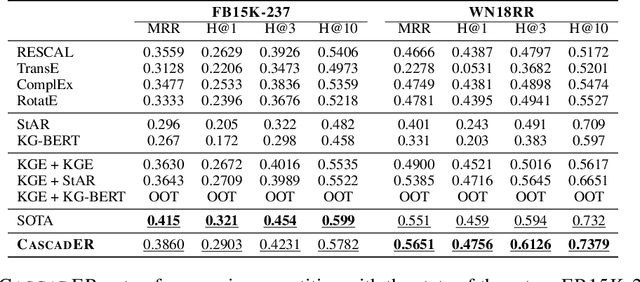
Knowledge graph (KG) link prediction is a fundamental task in artificial intelligence, with applications in natural language processing, information retrieval, and biomedicine. Recently, promising results have been achieved by leveraging cross-modal information in KGs, using ensembles that combine knowledge graph embeddings (KGEs) and contextual language models (LMs). However, existing ensembles are either (1) not consistently effective in terms of ranking accuracy gains or (2) impractically inefficient on larger datasets due to the combinatorial explosion problem of pairwise ranking with deep language models. In this paper, we propose a novel tiered ranking architecture CascadER to maintain the ranking accuracy of full ensembling while improving efficiency considerably. CascadER uses LMs to rerank the outputs of more efficient base KGEs, relying on an adaptive subset selection scheme aimed at invoking the LMs minimally while maximizing accuracy gain over the KGE. Extensive experiments demonstrate that CascadER improves MRR by up to 9 points over KGE baselines, setting new state-of-the-art performance on four benchmarks while improving efficiency by one or more orders of magnitude over competitive cross-modal baselines. Our empirical analyses reveal that diversity of models across modalities and preservation of individual models' confidence signals help explain the effectiveness of CascadER, and suggest promising directions for cross-modal cascaded architectures. Code and pretrained models are available at https://github.com/tsafavi/cascader.
Relational world knowledge representation in contextual language models: A review
Apr 12, 2021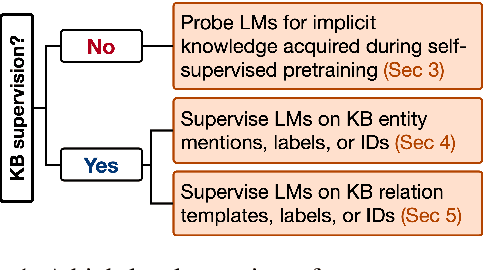
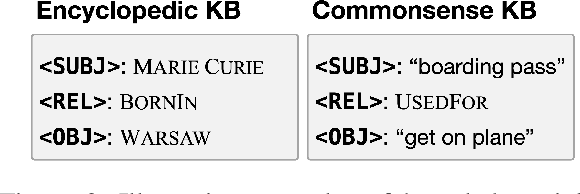
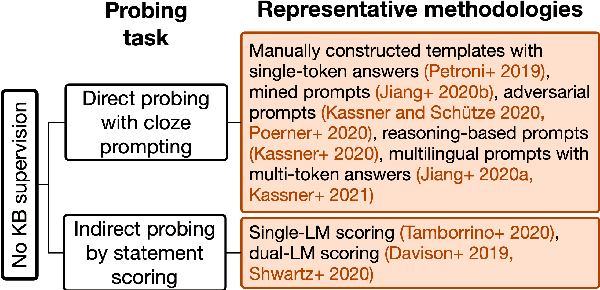

Relational knowledge bases (KBs) are established tools for world knowledge representation in machines. While they are advantageous for their precision and interpretability, they usually sacrifice some data modeling flexibility for these advantages because they adhere to a manually engineered schema. In this review, we take a natural language processing perspective to the limitations of KBs, examining how they may be addressed in part by training neural contextual language models (LMs) to internalize and express relational knowledge in free-text form. We propose a novel taxonomy for relational knowledge representation in contextual LMs based on the level of KB supervision provided, considering both works that probe LMs for implicit relational knowledge acquired during self-supervised pretraining on unstructured text alone, and works that explicitly supervise LMs at the level of KB entities and/or relations. We conclude that LMs and KBs are complementary representation tools, as KBs provide a high standard of factual precision which can in turn be flexibly and expressively modeled by LMs, and provide suggestions for future research in this direction.
Generating Negative Commonsense Knowledge
Nov 15, 2020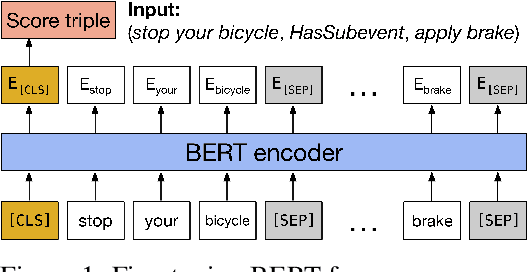
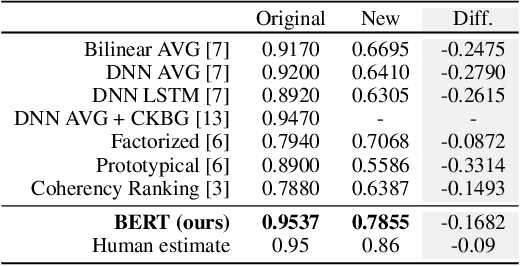
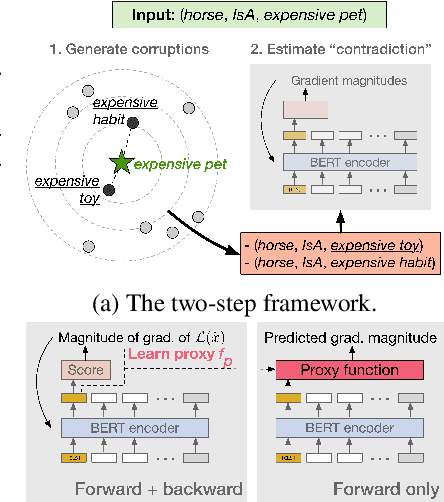

The acquisition of commonsense knowledge is an important open challenge in artificial intelligence. In this work-in-progress paper, we study the task of automatically augmenting commonsense knowledge bases (KBs) with novel statements. We show empirically that obtaining meaningful negative samples for the completion task is nontrivial, and propose NegatER, a framework for generating negative commonsense knowledge, to address this challenge. In our evaluation we demonstrate the intrinsic value and extrinsic utility of the knowledge generated by NegatER, opening up new avenues for future research in this direction.
CoDEx: A Comprehensive Knowledge Graph Completion Benchmark
Oct 06, 2020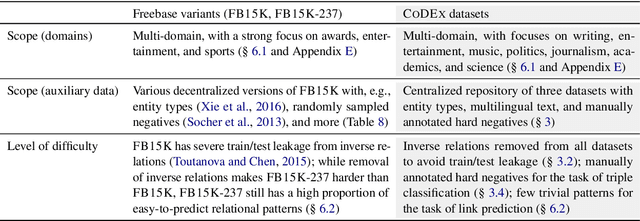
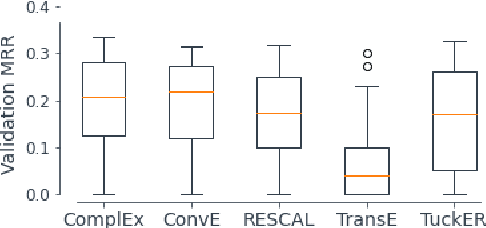


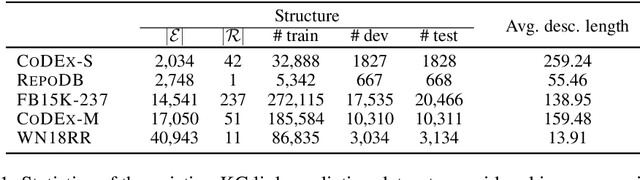
We present CoDEx, a set of knowledge graph completion datasets extracted from Wikidata and Wikipedia that improve upon existing knowledge graph completion benchmarks in scope and level of difficulty. In terms of scope, CoDEx comprises three knowledge graphs varying in size and structure, multilingual descriptions of entities and relations, and tens of thousands of hard negative triples that are plausible but verified to be false. To characterize CoDEx, we contribute thorough empirical analyses and benchmarking experiments. First, we analyze each CoDEx dataset in terms of logical relation patterns. Next, we report baseline link prediction and triple classification results on CoDEx for five extensively tuned embedding models. Finally, we differentiate CoDEx from the popular FB15K-237 knowledge graph completion dataset by showing that CoDEx covers more diverse and interpretable content, and is a more difficult link prediction benchmark. Data, code, and pretrained models are available at https://bit.ly/2EPbrJs.
Improving the Utility of Knowledge Graph Embeddings with Calibration
Apr 02, 2020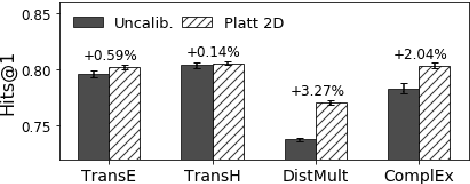
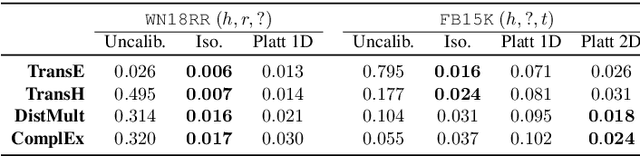


This paper addresses machine learning models that embed knowledge graph entities and relationships toward the goal of predicting unseen triples, which is an important task because most knowledge graphs are by nature incomplete. We posit that while offline link prediction accuracy using embeddings has been steadily improving on benchmark datasets, such embedding models have limited practical utility in real-world knowledge graph completion tasks because it is not clear when their predictions should be accepted or trusted. To this end, we propose to calibrate knowledge graph embedding models to output reliable confidence estimates for predicted triples. In crowdsourcing experiments, we demonstrate that calibrated confidence scores can make knowledge graph embeddings more useful to practitioners and data annotators in knowledge graph completion tasks. We also release two resources from our evaluation tasks: An enriched version of the FB15K benchmark and a new knowledge graph dataset extracted from Wikidata.