 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Brittleness of Image-Text Retrieval Benchmarks from Vision-Language Models Perspective
Jul 25, 2024
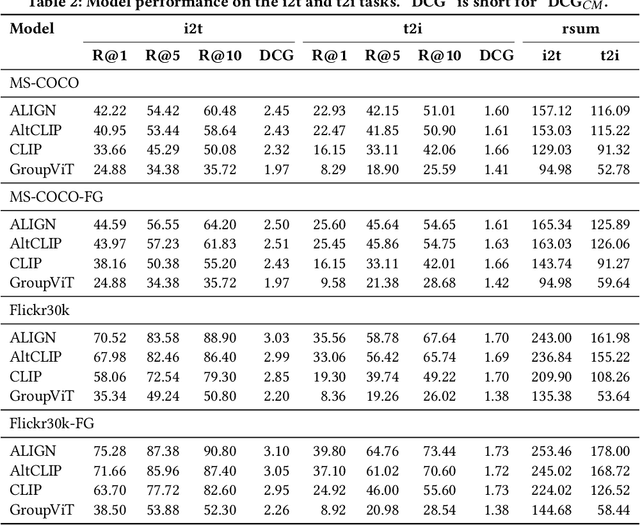
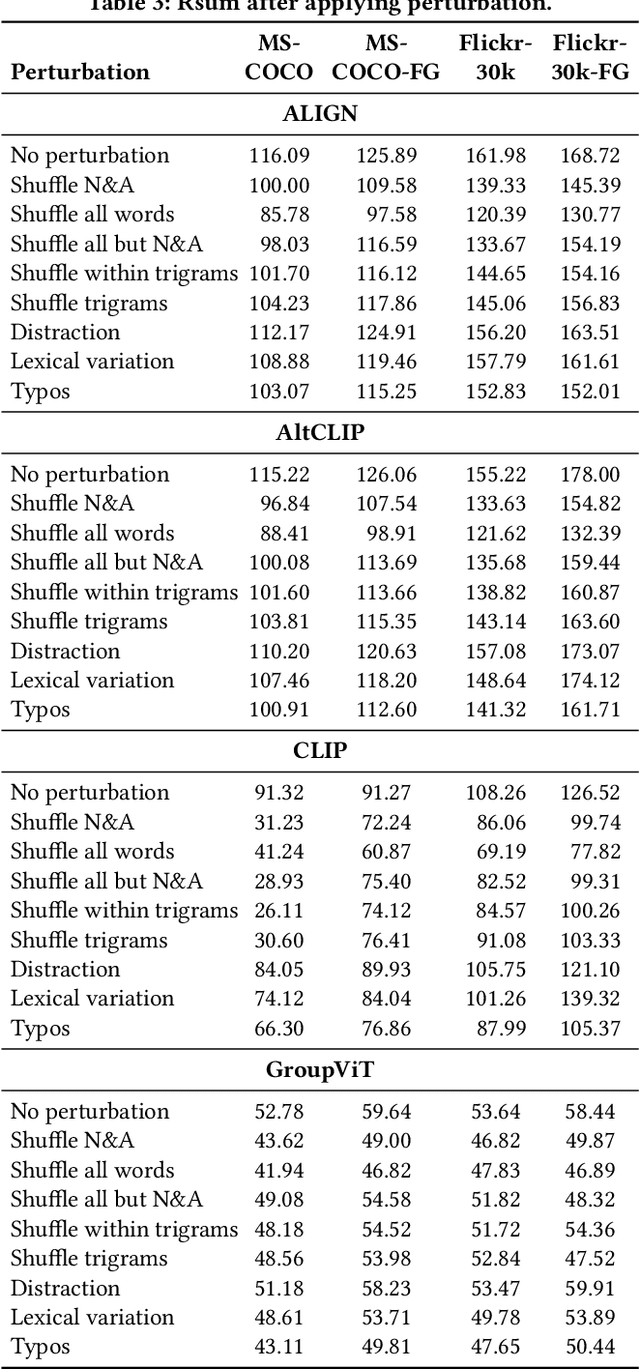

Image-text retrieval (ITR), an important task in information retrieval (IR), is driven by pretrained vision-language models (VLMs) that consistently achieve state-of-the-art performance. However, a significant challenge lies in the brittleness of existing ITR benchmarks. In standard datasets for the task, captions often provide broad summaries of scenes, neglecting detailed information about specific concepts. Additionally, the current evaluation setup assumes simplistic binary matches between images and texts and focuses on intra-modality rather than cross-modal relationships, which can lead to misinterpretations of model performance. Motivated by this gap, in this study, we focus on examining the brittleness of the ITR evaluation pipeline with a focus on concept granularity. We start by analyzing two common benchmarks, MS-COCO and Flickr30k, and compare them with their augmented versions, MS-COCO-FG and Flickr30k-FG, given a specified set of linguistic features capturing concept granularity. We discover that Flickr30k-FG and MS COCO-FG consistently achieve higher scores across all the selected features. To investigate the performance of VLMs on coarse and fine-grained datasets, we introduce a taxonomy of perturbations. We apply these perturbations to the selected datasets. We evaluate four state-of-the-art models - ALIGN, AltCLIP, CLIP, and GroupViT - on the standard and fine-grained datasets under zero-shot conditions, with and without the applied perturbations. The results demonstrate that although perturbations generally degrade model performance, the fine-grained datasets exhibit a smaller performance drop than their standard counterparts. Moreover, the relative performance drop across all setups is consistent across all models and datasets, indicating that the issue lies within the benchmarks. We conclude the paper by providing an agenda for improving ITR evaluation pipelines.
Dense Retrieval Adaptation using Target Domain Description
Jul 06, 2023



In information retrieval (IR), domain adaptation is the process of adapting a retrieval model to a new domain whose data distribution is different from the source domain. Existing methods in this area focus on unsupervised domain adaptation where they have access to the target document collection or supervised (often few-shot) domain adaptation where they additionally have access to (limited) labeled data in the target domain. There also exists research on improving zero-shot performance of retrieval models with no adaptation. This paper introduces a new category of domain adaptation in IR that is as-yet unexplored. Here, similar to the zero-shot setting, we assume the retrieval model does not have access to the target document collection. In contrast, it does have access to a brief textual description that explains the target domain. We define a taxonomy of domain attributes in retrieval tasks to understand different properties of a source domain that can be adapted to a target domain. We introduce a novel automatic data construction pipeline that produces a synthetic document collection, query set, and pseudo relevance labels, given a textual domain description. Extensive experiments on five diverse target domains show that adapting dense retrieval models using the constructed synthetic data leads to effective retrieval performance on the target domain.
News Article Retrieval in Context for Event-centric Narrative Creation
Jun 30, 2021
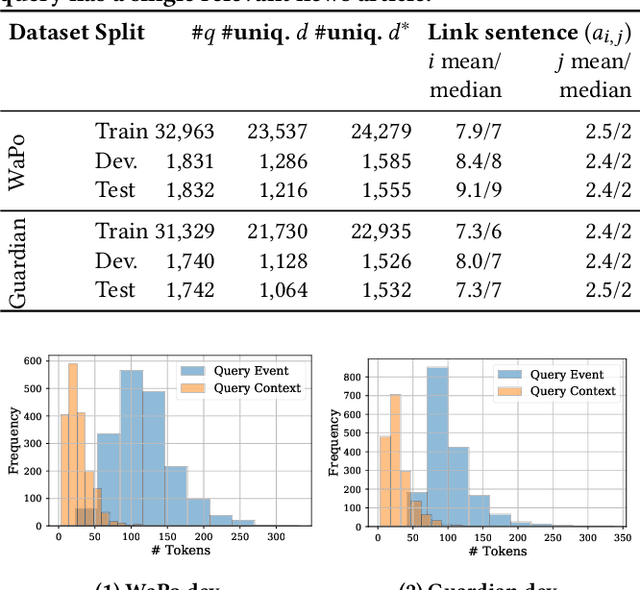
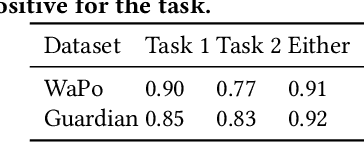
Writers such as journalists often use automatic tools to find relevant content to include in their narratives. In this paper, we focus on supporting writers in the news domain to develop event-centric narratives. Given an incomplete narrative that specifies a main event and a context, we aim to retrieve news articles that discuss relevant events that would enable the continuation of the narrative. We formally define this task and propose a retrieval dataset construction procedure that relies on existing news articles to simulate incomplete narratives and relevant articles. Experiments on two datasets derived from this procedure show that state-of-the-art lexical and semantic rankers are not sufficient for this task. We show that combining those with a ranker that ranks articles by reverse chronological order outperforms those rankers alone. We also perform an in-depth quantitative and qualitative analysis of the results that sheds light on the characteristics of this task.
Uncertainty over Uncertainty: Investigating the Assumptions, Annotations, and Text Measurements of Economic Policy Uncertainty
Oct 09, 2020
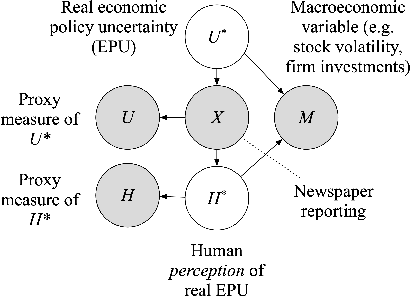

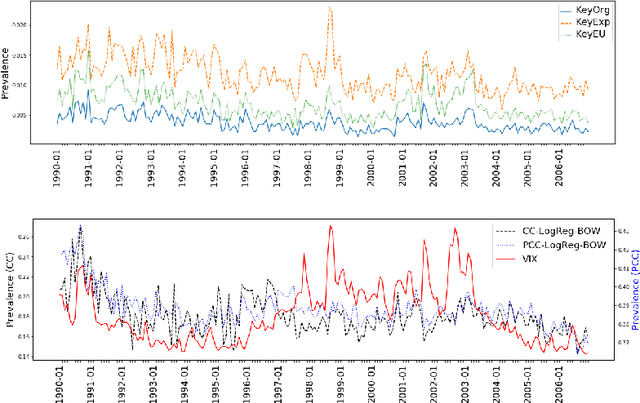
Methods and applications are inextricably linked in science, and in particular in the domain of text-as-data. In this paper, we examine one such text-as-data application, an established economic index that measures economic policy uncertainty from keyword occurrences in news. This index, which is shown to correlate with firm investment, employment, and excess market returns, has had substantive impact in both the private sector and academia. Yet, as we revisit and extend the original authors' annotations and text measurements we find interesting text-as-data methodological research questions: (1) Are annotator disagreements a reflection of ambiguity in language? (2) Do alternative text measurements correlate with one another and with measures of external predictive validity? We find for this application (1) some annotator disagreements of economic policy uncertainty can be attributed to ambiguity in language, and (2) switching measurements from keyword-matching to supervised machine learning classifiers results in low correlation, a concerning implication for the validity of the index.
* Accepted to the 2020 Natural Language Processing + Computational Social Science Workshop (NLP+CSS) at EMNLP
Improving the Utility of Knowledge Graph Embeddings with Calibration
Apr 02, 2020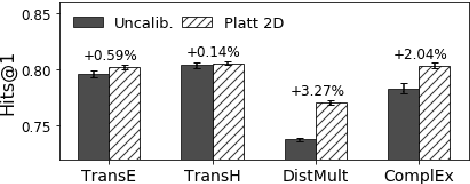
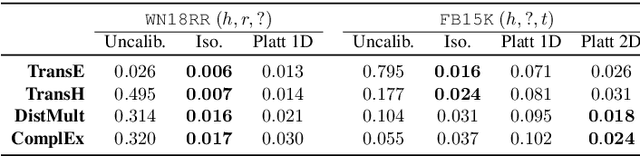


This paper addresses machine learning models that embed knowledge graph entities and relationships toward the goal of predicting unseen triples, which is an important task because most knowledge graphs are by nature incomplete. We posit that while offline link prediction accuracy using embeddings has been steadily improving on benchmark datasets, such embedding models have limited practical utility in real-world knowledge graph completion tasks because it is not clear when their predictions should be accepted or trusted. To this end, we propose to calibrate knowledge graph embedding models to output reliable confidence estimates for predicted triples. In crowdsourcing experiments, we demonstrate that calibrated confidence scores can make knowledge graph embeddings more useful to practitioners and data annotators in knowledge graph completion tasks. We also release two resources from our evaluation tasks: An enriched version of the FB15K benchmark and a new knowledge graph dataset extracted from Wikidata.
Novel Entity Discovery from Web Tables
Feb 01, 2020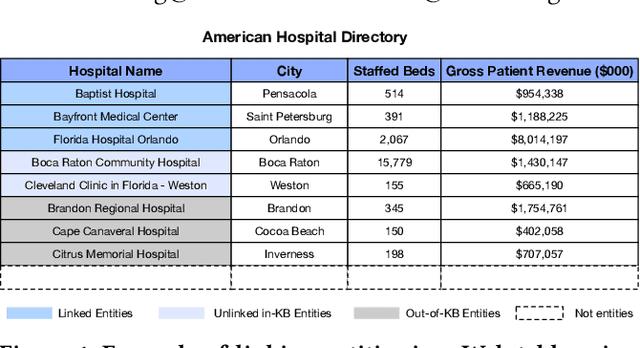

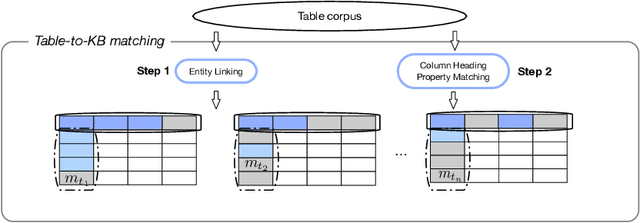
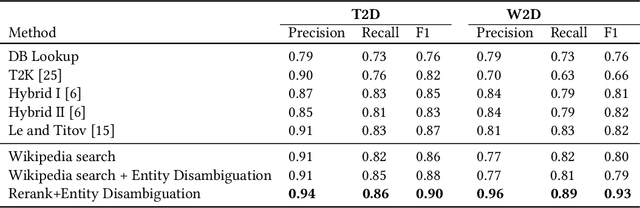
When working with any sort of knowledge base (KB) one has to make sure it is as complete and also as up-to-date as possible. Both tasks are non-trivial as they require recall-oriented efforts to determine which entities and relationships are missing from the KB. As such they require a significant amount of labor. Tables on the Web, on the other hand, are abundant and have the distinct potential to assist with these tasks. In particular, we can leverage the content in such tables to discover new entities, properties, and relationships. Because web tables typically only contain raw textual content we first need to determine which cells refer to which known entities---a task we dub table-to-KB matching. This first task aims to infer table semantics by linking table cells and heading columns to elements of a KB. Then second task builds upon these linked entities and properties to not only identify novel ones in the same table but also to bootstrap their type and additional relationships. We refer to this process as novel entity discovery and, to the best of our knowledge, it is the first endeavor on mining the unlinked cells in web tables. Our method identifies not only out-of-KB (``novel'') information but also novel aliases for in-KB (``known'') entities. When evaluated using three purpose-built test collections, we find that our proposed approaches obtain a marked improvement in terms of precision over our baselines whilst keeping recall stable.
Weakly-supervised Contextualization of Knowledge Graph Facts
Jul 08, 2018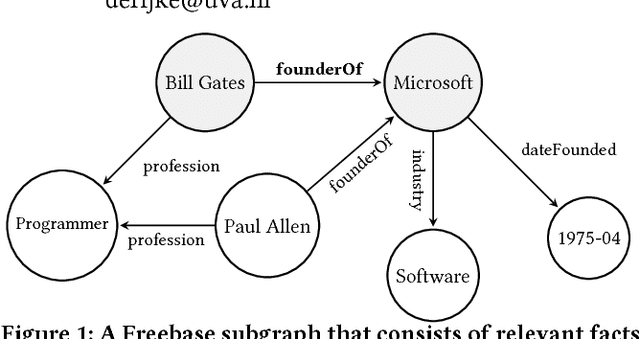
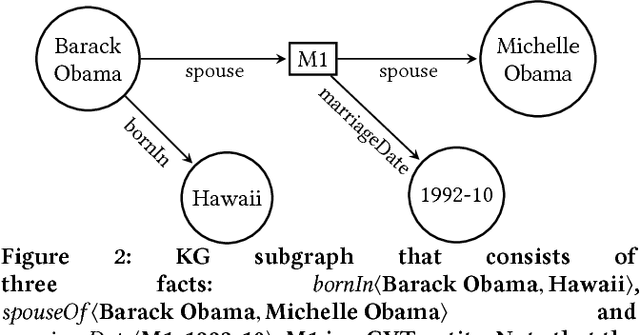
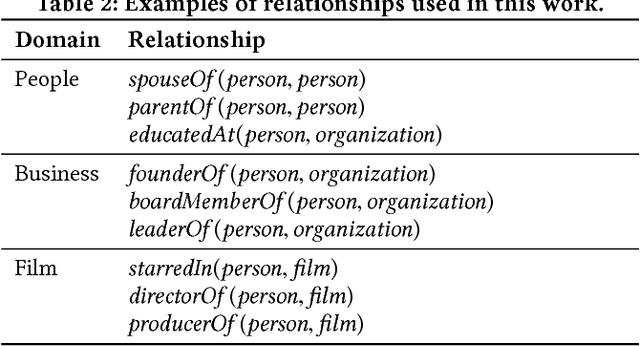
Knowledge graphs (KGs) model facts about the world, they consist of nodes (entities such as companies and people) that are connected by edges (relations such as founderOf). Facts encoded in KGs are frequently used by search applications to augment result pages. When presenting a KG fact to the user, providing other facts that are pertinent to that main fact can enrich the user experience and support exploratory information needs. KG fact contextualization is the task of augmenting a given KG fact with additional and useful KG facts. The task is challenging because of the large size of KGs, discovering other relevant facts even in a small neighborhood of the given fact results in an enormous amount of candidates. We introduce a neural fact contextualization method (NFCM) to address the KG fact contextualization task. NFCM first generates a set of candidate facts in the neighborhood of a given fact and then ranks the candidate facts using a supervised learning to rank model. The ranking model combines features that we automatically learn from data and that represent the query-candidate facts with a set of hand-crafted features we devised or adjusted for this task. In order to obtain the annotations required to train the learning to rank model at scale, we generate training data automatically using distant supervision on a large entity-tagged text corpus. We show that ranking functions learned on this data are effective at contextualizing KG facts. Evaluation using human assessors shows that it significantly outperforms several competitive baselines.