 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Entity Discovery from Web Tables
Paper and Code
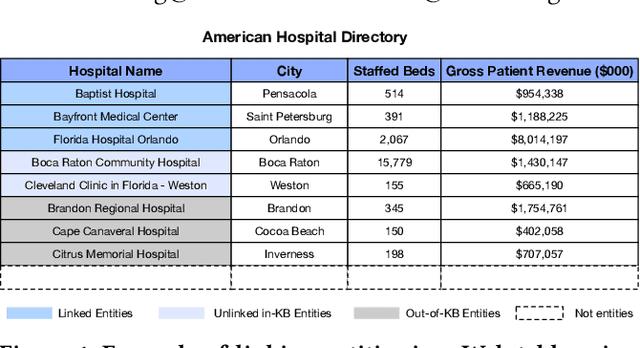

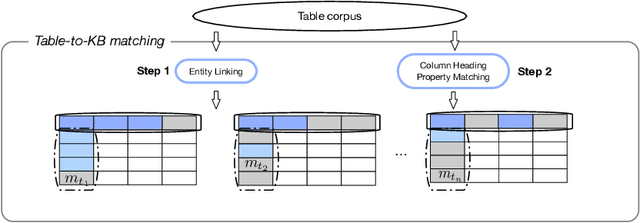
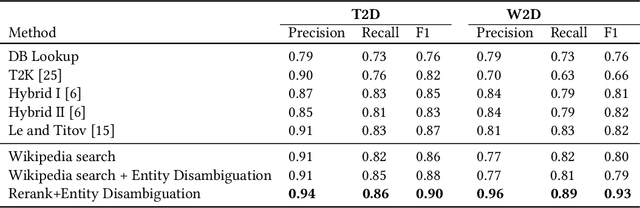
When working with any sort of knowledge base (KB) one has to make sure it is as complete and also as up-to-date as possible. Both tasks are non-trivial as they require recall-oriented efforts to determine which entities and relationships are missing from the KB. As such they require a significant amount of labor. Tables on the Web, on the other hand, are abundant and have the distinct potential to assist with these tasks. In particular, we can leverage the content in such tables to discover new entities, properties, and relationships. Because web tables typically only contain raw textual content we first need to determine which cells refer to which known entities---a task we dub table-to-KB matching. This first task aims to infer table semantics by linking table cells and heading columns to elements of a KB. Then second task builds upon these linked entities and properties to not only identify novel ones in the same table but also to bootstrap their type and additional relationships. We refer to this process as novel entity discovery and, to the best of our knowledge, it is the first endeavor on mining the unlinked cells in web tables. Our method identifies not only out-of-KB (``novel'') information but also novel aliases for in-KB (``known'') entities. When evaluated using three purpose-built test collections, we find that our proposed approaches obtain a marked improvement in terms of precision over our baselines whilst keeping recall stable.