 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Brittleness of Image-Text Retrieval Benchmarks from Vision-Language Models Perspective
Jul 25, 2024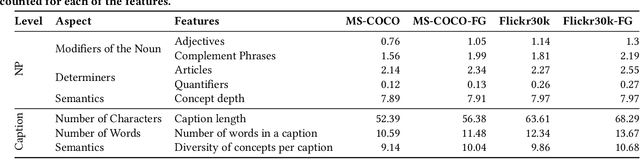
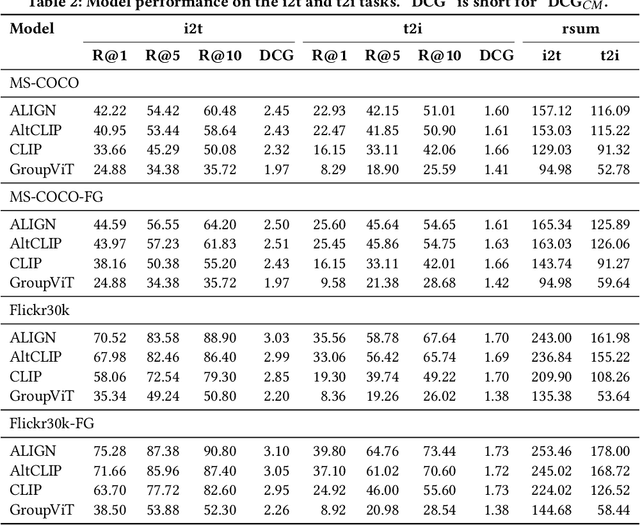
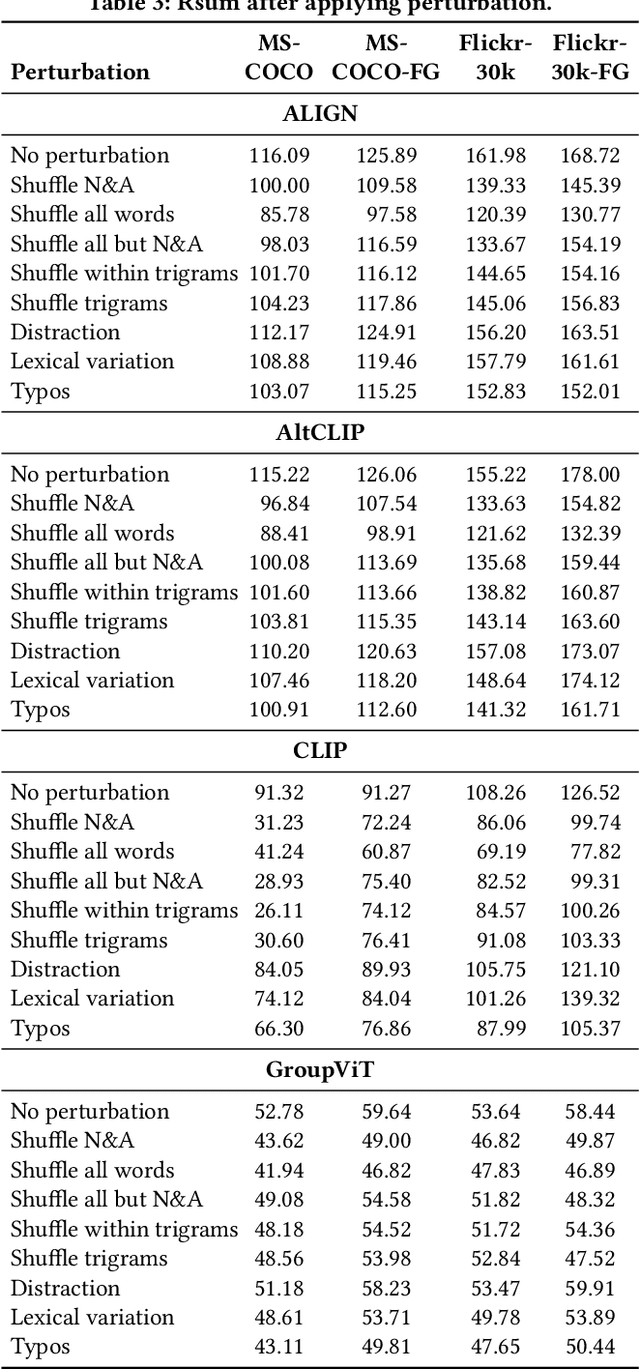

Image-text retrieval (ITR), an important task in information retrieval (IR), is driven by pretrained vision-language models (VLMs) that consistently achieve state-of-the-art performance. However, a significant challenge lies in the brittleness of existing ITR benchmarks. In standard datasets for the task, captions often provide broad summaries of scenes, neglecting detailed information about specific concepts. Additionally, the current evaluation setup assumes simplistic binary matches between images and texts and focuses on intra-modality rather than cross-modal relationships, which can lead to misinterpretations of model performance. Motivated by this gap, in this study, we focus on examining the brittleness of the ITR evaluation pipeline with a focus on concept granularity. We start by analyzing two common benchmarks, MS-COCO and Flickr30k, and compare them with their augmented versions, MS-COCO-FG and Flickr30k-FG, given a specified set of linguistic features capturing concept granularity. We discover that Flickr30k-FG and MS COCO-FG consistently achieve higher scores across all the selected features. To investigate the performance of VLMs on coarse and fine-grained datasets, we introduce a taxonomy of perturbations. We apply these perturbations to the selected datasets. We evaluate four state-of-the-art models - ALIGN, AltCLIP, CLIP, and GroupViT - on the standard and fine-grained datasets under zero-shot conditions, with and without the applied perturbations. The results demonstrate that although perturbations generally degrade model performance, the fine-grained datasets exhibit a smaller performance drop than their standard counterparts. Moreover, the relative performance drop across all setups is consistent across all models and datasets, indicating that the issue lies within the benchmarks. We conclude the paper by providing an agenda for improving ITR evaluation pipelines.
TempTabQA: Temporal Question Answering for Semi-Structured Tables
Nov 14, 2023
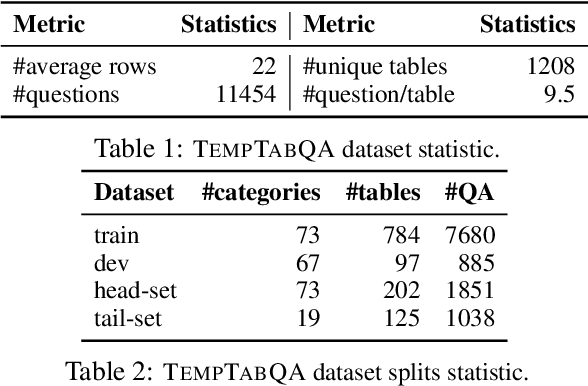


Semi-structured data, such as Infobox tables, often include temporal information about entities, either implicitly or explicitly. Can current NLP systems reason about such information in semi-structured tables? To tackle this question, we introduce the task of temporal question answering on semi-structured tables. We present a dataset, TempTabQA, which comprises 11,454 question-answer pairs extracted from 1,208 Wikipedia Infobox tables spanning more than 90 distinct domains. Using this dataset, we evaluate several state-of-the-art models for temporal reasoning. We observe that even the top-performing LLMs lag behind human performance by more than 13.5 F1 points. Given these results, our dataset has the potential to serve as a challenging benchmark to improve the temporal reasoning capabilities of NLP models.
Novel Entity Discovery from Web Tables
Feb 01, 2020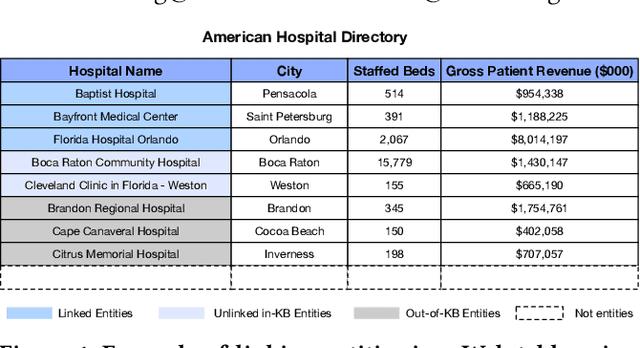

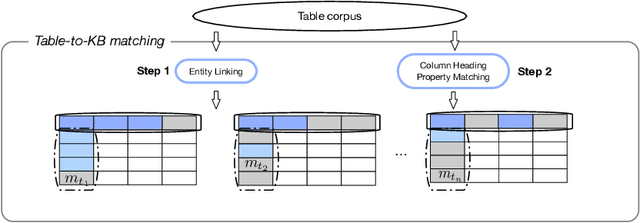
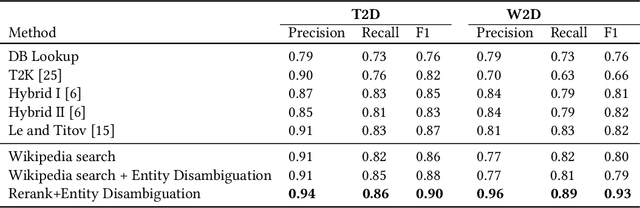
When working with any sort of knowledge base (KB) one has to make sure it is as complete and also as up-to-date as possible. Both tasks are non-trivial as they require recall-oriented efforts to determine which entities and relationships are missing from the KB. As such they require a significant amount of labor. Tables on the Web, on the other hand, are abundant and have the distinct potential to assist with these tasks. In particular, we can leverage the content in such tables to discover new entities, properties, and relationships. Because web tables typically only contain raw textual content we first need to determine which cells refer to which known entities---a task we dub table-to-KB matching. This first task aims to infer table semantics by linking table cells and heading columns to elements of a KB. Then second task builds upon these linked entities and properties to not only identify novel ones in the same table but also to bootstrap their type and additional relationships. We refer to this process as novel entity discovery and, to the best of our knowledge, it is the first endeavor on mining the unlinked cells in web tables. Our method identifies not only out-of-KB (``novel'') information but also novel aliases for in-KB (``known'') entities. When evaluated using three purpose-built test collections, we find that our proposed approaches obtain a marked improvement in terms of precision over our baselines whilst keeping recall stable.
Weakly-supervised Contextualization of Knowledge Graph Facts
Jul 08, 2018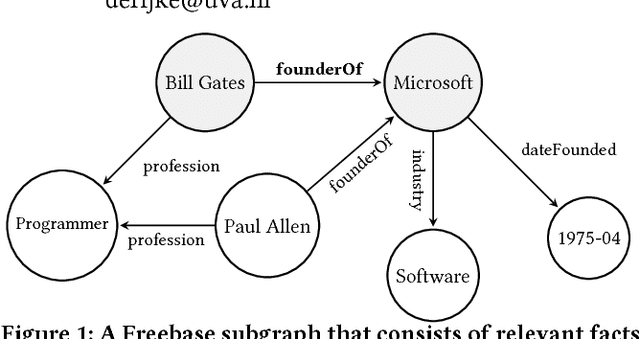
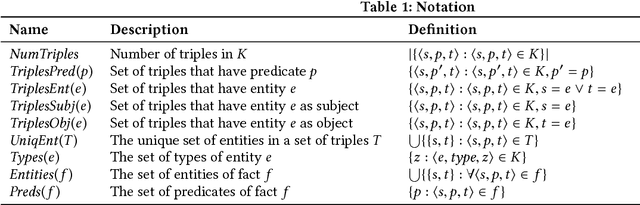
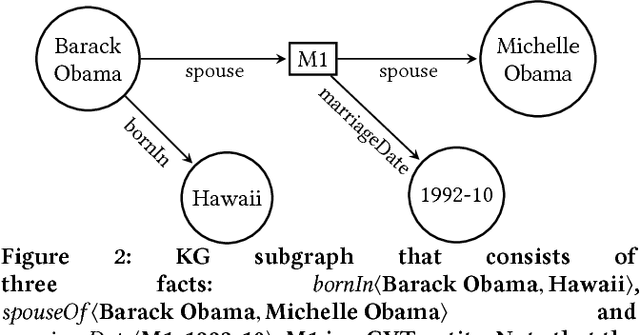
Knowledge graphs (KGs) model facts about the world, they consist of nodes (entities such as companies and people) that are connected by edges (relations such as founderOf). Facts encoded in KGs are frequently used by search applications to augment result pages. When presenting a KG fact to the user, providing other facts that are pertinent to that main fact can enrich the user experience and support exploratory information needs. KG fact contextualization is the task of augmenting a given KG fact with additional and useful KG facts. The task is challenging because of the large size of KGs, discovering other relevant facts even in a small neighborhood of the given fact results in an enormous amount of candidates. We introduce a neural fact contextualization method (NFCM) to address the KG fact contextualization task. NFCM first generates a set of candidate facts in the neighborhood of a given fact and then ranks the candidate facts using a supervised learning to rank model. The ranking model combines features that we automatically learn from data and that represent the query-candidate facts with a set of hand-crafted features we devised or adjusted for this task. In order to obtain the annotations required to train the learning to rank model at scale, we generate training data automatically using distant supervision on a large entity-tagged text corpus. We show that ranking functions learned on this data are effective at contextualizing KG facts. Evaluation using human assessors shows that it significantly outperforms several competitive baselines.