 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNews Article Retrieval in Context for Event-centric Narrative Creation
Jun 30, 2021
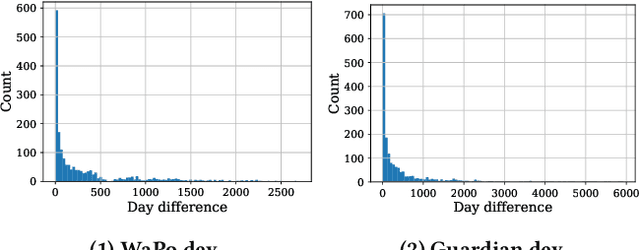
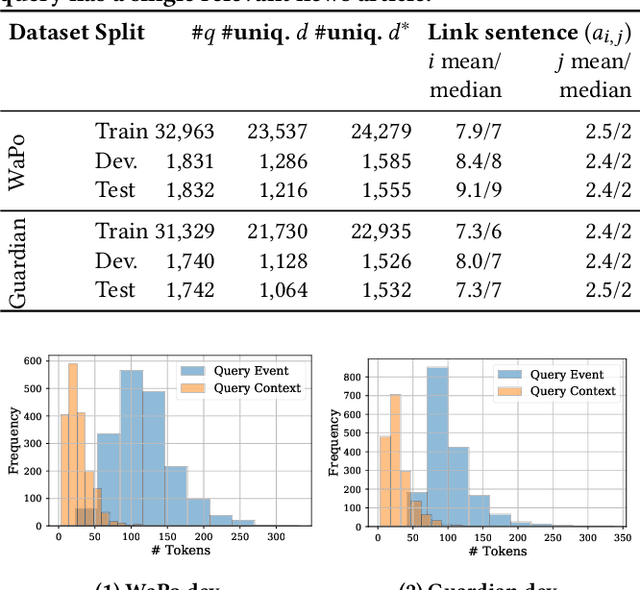
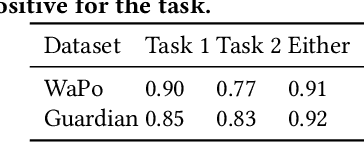
Writers such as journalists often use automatic tools to find relevant content to include in their narratives. In this paper, we focus on supporting writers in the news domain to develop event-centric narratives. Given an incomplete narrative that specifies a main event and a context, we aim to retrieve news articles that discuss relevant events that would enable the continuation of the narrative. We formally define this task and propose a retrieval dataset construction procedure that relies on existing news articles to simulate incomplete narratives and relevant articles. Experiments on two datasets derived from this procedure show that state-of-the-art lexical and semantic rankers are not sufficient for this task. We show that combining those with a ranker that ranks articles by reverse chronological order outperforms those rankers alone. We also perform an in-depth quantitative and qualitative analysis of the results that sheds light on the characteristics of this task.
Analysing Dense Passage Retrieval for Multi-hop Question Answering
Jun 15, 2021
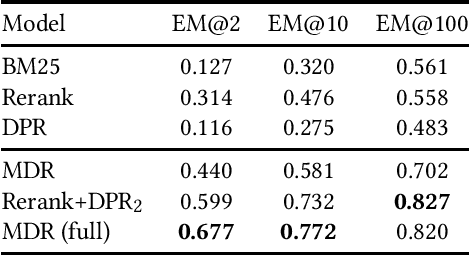

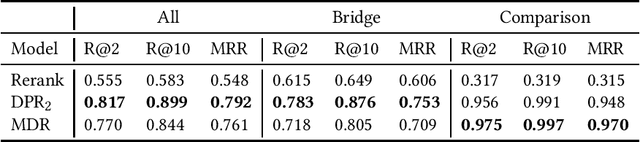
We analyse the performance of passage retrieval models in the presence of complex (multi-hop) questions to provide a better understanding of how retrieval systems behave when multiple hops of reasoning are needed. In simple open-domain question answering (QA), dense passage retrieval has become one of the standard approaches for retrieving the relevant passages to infer an answer. Recently, dense passage retrieval also achieved state-of-the-art results in multi-hop QA, where aggregating information from multiple documents and reasoning over them is required. However, so far, the dense retrieval models are not evaluated properly concerning the multi-hop nature of the problem: models are typically evaluated by the end result of the retrieval pipeline, which leaves unclear where their success lies. In this work, we provide an in-depth evaluation of such models not only unveiling the reasons behind their success but also their limitations. Moreover, we introduce a hybrid (lexical and dense) retrieval approach that is highly competitive with the state-of-the-art dense retrieval model, while requiring substantially less computational resources. Furthermore, we also perform qualitative analysis to better understand the challenges behind passage retrieval for multi-hop QA.
Leveraging Query Resolution and Reading Comprehension for Conversational Passage Retrieval
Feb 17, 2021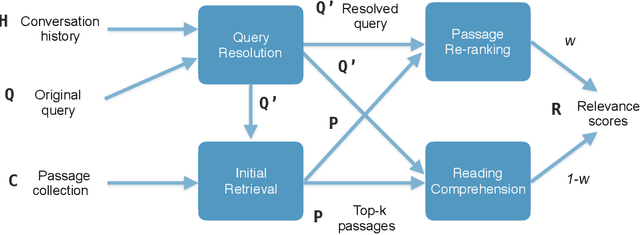
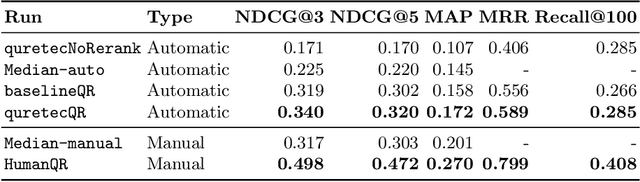

This paper describes the participation of UvA.ILPS group at the TREC CAsT 2020 track. Our passage retrieval pipeline consists of (i) an initial retrieval module that uses BM25, and (ii) a re-ranking module that combines the score of a BERT ranking model with the score of a machine comprehension model adjusted for passage retrieval. An important challenge in conversational passage retrieval is that queries are often under-specified. Thus, we perform query resolution, that is, add missing context from the conversation history to the current turn query using QuReTeC, a term classification query resolution model. We show that our best automatic and manual runs outperform the corresponding median runs by a large margin.
Supporting search engines with knowledge and context
Feb 12, 2021

Search engines leverage knowledge to improve information access. In order to effectively leverage knowledge, search engines should account for context, i.e., information about the user and query. In this thesis, we aim to support search engines in leveraging knowledge while accounting for context. In the first part of this thesis, we study how to make structured knowledge more accessible to the user when the search engine proactively provides such knowledge as context to enrich search results. As a first task, we study how to retrieve descriptions of knowledge facts from a text corpus. Next, we study how to automatically generate knowledge fact descriptions. And finally, we study how to contextualize knowledge facts, that is, to automatically find facts related to a query fact. In the second part of this thesis, we study how to improve interactive knowledge gathering. We focus on conversational search, where the user interacts with the search engine to gather knowledge over large unstructured knowledge repositories. We focus on multi-turn passage retrieval as an instance of conversational search. We propose to model query resolution as a term classification task and propose a method to address it. In the final part of this thesis, we focus on search engine support for professional writers in the news domain. We study how to support such writers create event-narratives by exploring knowledge from a corpus of news articles. We propose a dataset construction procedure for this task that relies on existing news articles to simulate incomplete narratives and relevant articles. We study the performance of multiple rankers, lexical and semantic, and provide insights into the characteristics of this task.
MICROS: Mixed-Initiative ConveRsatiOnal Systems Workshop
Jan 25, 2021The 1st edition of the workshop on Mixed-Initiative ConveRsatiOnal Systems (MICROS@ECIR2021) aims at investigating and collecting novel ideas and contributions in the field of conversational systems. Oftentimes, the users fulfill their information need using smartphones and home assistants. This has revolutionized the way users access online information, thus posing new challenges compared to traditional search and recommendation. The first edition of MICROS will have a particular focus on mixed-initiative conversational systems. Indeed, conversational systems need to be proactive, proposing not only answers but also possible interpretations for ambiguous or vague requests.
A Comparison of Question Rewriting Methods for Conversational Passage Retrieval
Jan 19, 2021
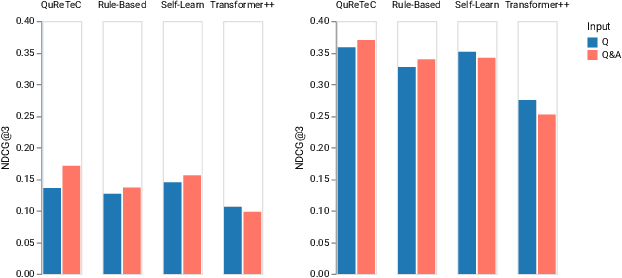
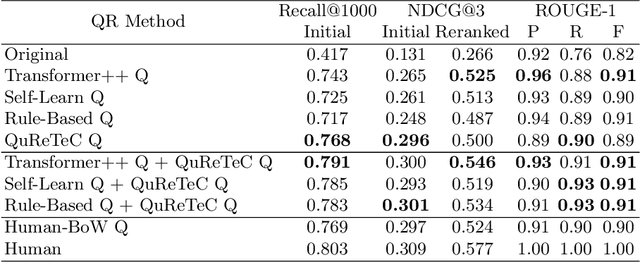
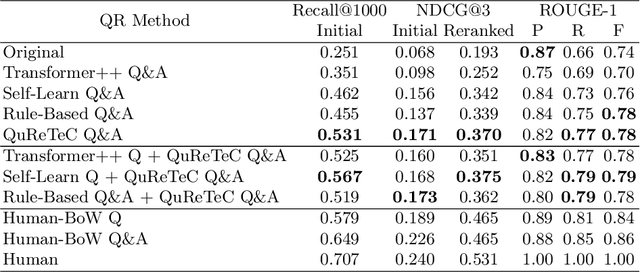
Conversational passage retrieval relies on question rewriting to modify the original question so that it no longer depends on the conversation history. Several methods for question rewriting have recently been proposed, but they were compared under different retrieval pipelines. We bridge this gap by thoroughly evaluating those question rewriting methods on the TREC CAsT 2019 and 2020 datasets under the same retrieval pipeline. We analyze the effect of different types of question rewriting methods on retrieval performance and show that by combining question rewriting methods of different types we can achieve state-of-the-art performance on both datasets.
Analysing the Effect of Clarifying Questions on Document Ranking in Conversational Search
Aug 11, 2020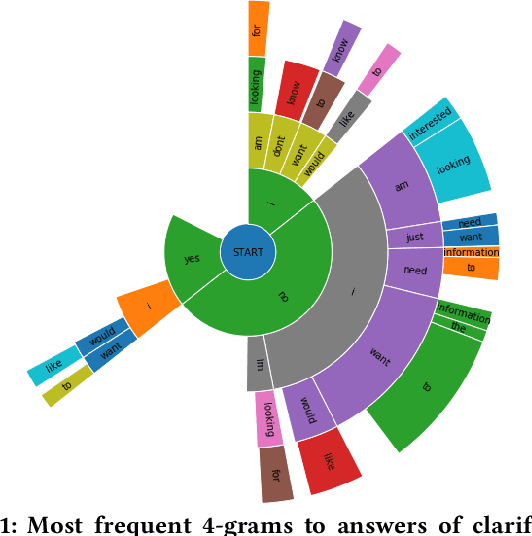
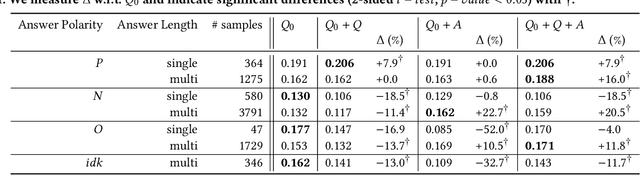
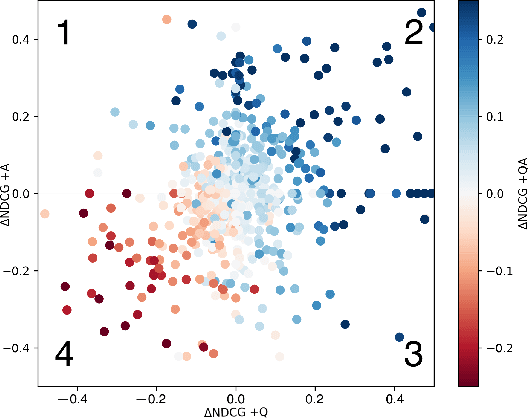
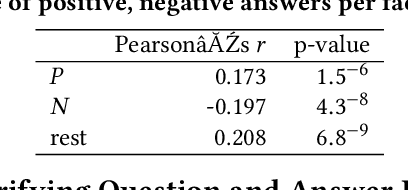
Recent research on conversational search highlights the importance of mixed-initiative in conversations. To enable mixed-initiative, the system should be able to ask clarifying questions to the user. However, the ability of the underlying ranking models (which support conversational search) to account for these clarifying questions and answers has not been analysed when ranking documents, at large. To this end, we analyse the performance of a lexical ranking model on a conversational search dataset with clarifying questions. We investigate, both quantitatively and qualitatively, how different aspects of clarifying questions and user answers affect the quality of ranking. We argue that there needs to be some fine-grained treatment of the entire conversational round of clarification, based on the explicit feedback which is present in such mixed-initiative settings. Informed by our findings, we introduce a simple heuristic-based lexical baseline, that significantly outperforms the existing naive baselines. Our work aims to enhance our understanding of the challenges present in this particular task and inform the design of more appropriate conversational ranking models.
Knowledge Graph Simple Question Answering for Unseen Domains
May 25, 2020
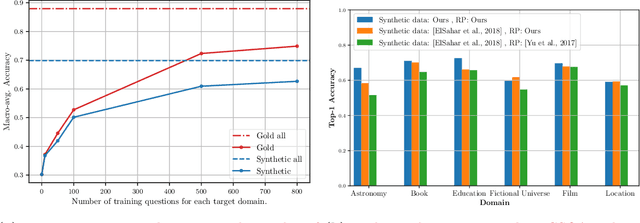
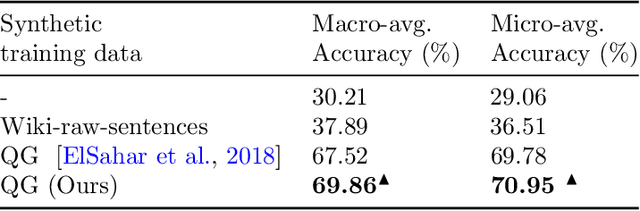
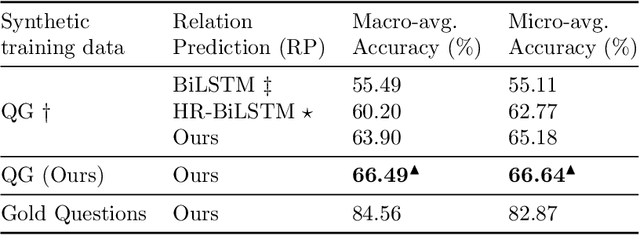
Knowledge graph simple question answering (KGSQA), in its standard form, does not take into account that human-curated question answering training data only cover a small subset of the relations that exist in a Knowledge Graph (KG), or even worse, that new domains covering unseen and rather different to existing domains relations are added to the KG. In this work, we study KGSQA in a previously unstudied setting where new, unseen domains are added during test time. In this setting, question-answer pairs of the new domain do not appear during training, thus making the task more challenging. We propose a data-centric domain adaptation framework that consists of a KGSQA system that is applicable to new domains, and a sequence to sequence question generation method that automatically generates question-answer pairs for the new domain. Since the effectiveness of question generation for KGSQA can be restricted by the limited lexical variety of the generated questions, we use distant supervision to extract a set of keywords that express each relation of the unseen domain and incorporate those in the question generation method. Experimental results demonstrate that our framework significantly improves over zero-shot baselines and is robust across domains.
Query Resolution for Conversational Search with Limited Supervision
May 24, 2020
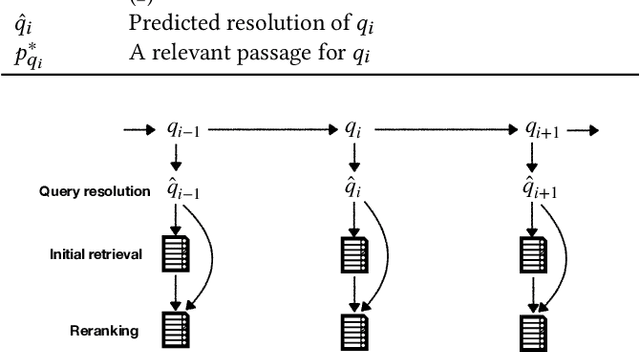


In this work we focus on multi-turn passage retrieval as a crucial component of conversational search. One of the key challenges in multi-turn passage retrieval comes from the fact that the current turn query is often underspecified due to zero anaphora, topic change, or topic return. Context from the conversational history can be used to arrive at a better expression of the current turn query, defined as the task of query resolution. In this paper, we model the query resolution task as a binary term classification problem: for each term appearing in the previous turns of the conversation decide whether to add it to the current turn query or not. We propose QuReTeC (Query Resolution by Term Classification), a neural query resolution model based on bidirectional transformers. We propose a distant supervision method to automatically generate training data by using query-passage relevance labels. Such labels are often readily available in a collection either as human annotations or inferred from user interactions. We show that QuReTeC outperforms state-of-the-art models, and furthermore, that our distant supervision method can be used to substantially reduce the amount of human-curated data required to train QuReTeC. We incorporate QuReTeC in a multi-turn, multi-stage passage retrieval architecture and demonstrate its effectiveness on the TREC CAsT dataset.
Weakly-supervised Contextualization of Knowledge Graph Facts
Jul 08, 2018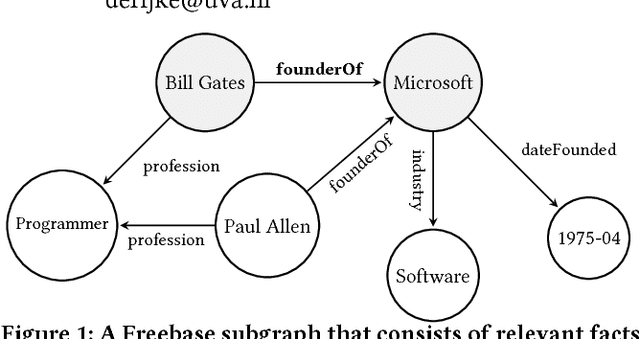
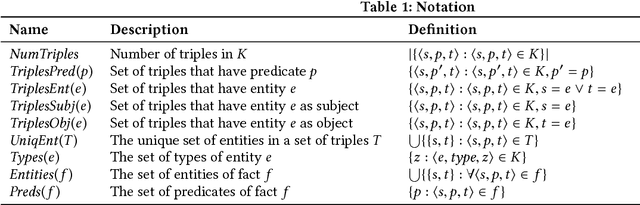
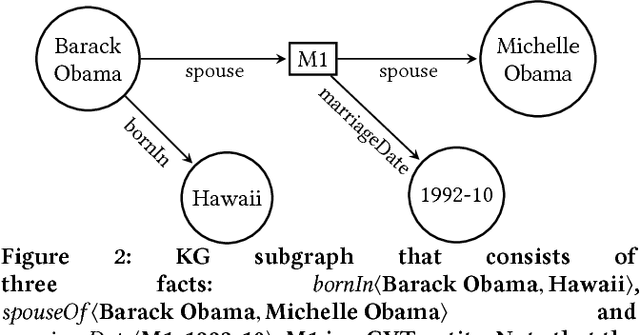
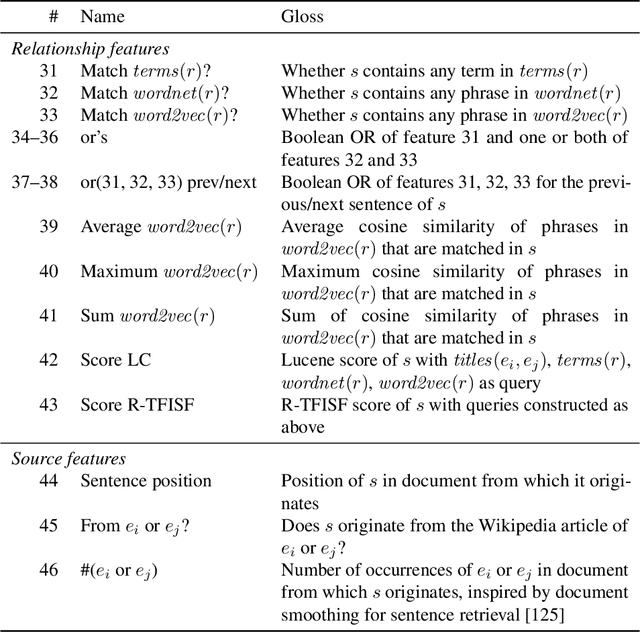
Knowledge graphs (KGs) model facts about the world, they consist of nodes (entities such as companies and people) that are connected by edges (relations such as founderOf). Facts encoded in KGs are frequently used by search applications to augment result pages. When presenting a KG fact to the user, providing other facts that are pertinent to that main fact can enrich the user experience and support exploratory information needs. KG fact contextualization is the task of augmenting a given KG fact with additional and useful KG facts. The task is challenging because of the large size of KGs, discovering other relevant facts even in a small neighborhood of the given fact results in an enormous amount of candidates. We introduce a neural fact contextualization method (NFCM) to address the KG fact contextualization task. NFCM first generates a set of candidate facts in the neighborhood of a given fact and then ranks the candidate facts using a supervised learning to rank model. The ranking model combines features that we automatically learn from data and that represent the query-candidate facts with a set of hand-crafted features we devised or adjusted for this task. In order to obtain the annotations required to train the learning to rank model at scale, we generate training data automatically using distant supervision on a large entity-tagged text corpus. We show that ranking functions learned on this data are effective at contextualizing KG facts. Evaluation using human assessors shows that it significantly outperforms several competitive baselines.