 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Set-Compositional and Negated Representations for First-Stage Ranking
Jan 13, 2025Set compositional and negated queries are crucial for expressing complex information needs and enable the discovery of niche items like Books about non-European monarchs. Despite the recent advances in LLMs, first-stage ranking remains challenging due to the requirement of encoding documents and queries independently from each other. This limitation calls for constructing compositional query representations that encapsulate logical operations or negations, and can be used to match relevant documents effectively. In the first part of this work, we explore constructing such representations in a zero-shot setting using vector operations between lexically grounded Learned Sparse Retrieval (LSR) representations. Specifically, we introduce Disentangled Negation that penalizes only the negated parts of a query, and a Combined Pseudo-Term approach that enhances LSRs ability to handle intersections. We find that our zero-shot approach is competitive and often outperforms retrievers fine-tuned on compositional data, highlighting certain limitations of LSR and Dense Retrievers. Finally, we address some of these limitations and improve LSRs representation power for negation, by allowing them to attribute negative term scores and effectively penalize documents containing the negated terms.
Corpus-informed Retrieval Augmented Generation of Clarifying Questions
Sep 27, 2024



This study aims to develop models that generate corpus informed clarifying questions for web search, in a way that ensures the questions align with the available information in the retrieval corpus. We demonstrate the effectiveness of Retrieval Augmented Language Models (RAG) in this process, emphasising their ability to (i) jointly model the user query and retrieval corpus to pinpoint the uncertainty and ask for clarifications end-to-end and (ii) model more evidence documents, which can be used towards increasing the breadth of the questions asked. However, we observe that in current datasets search intents are largely unsupported by the corpus, which is problematic both for training and evaluation. This causes question generation models to ``hallucinate'', ie. suggest intents that are not in the corpus, which can have detrimental effects in performance. To address this, we propose dataset augmentation methods that align the ground truth clarifications with the retrieval corpus. Additionally, we explore techniques to enhance the relevance of the evidence pool during inference, but find that identifying ground truth intents within the corpus remains challenging. Our analysis suggests that this challenge is partly due to the bias of current datasets towards clarification taxonomies and calls for data that can support generating corpus-informed clarifications.
Zero-shot Query Contextualization for Conversational Search
Apr 22, 2022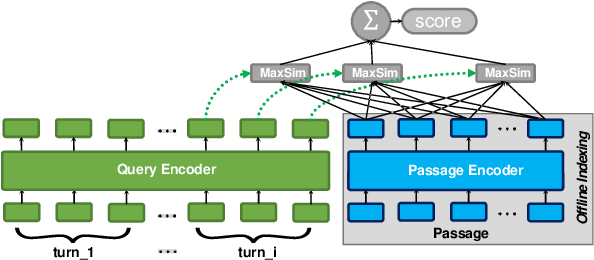
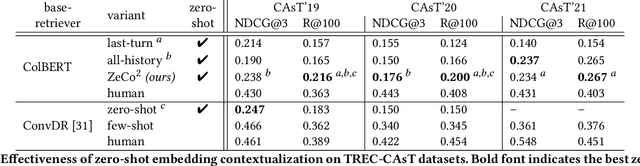
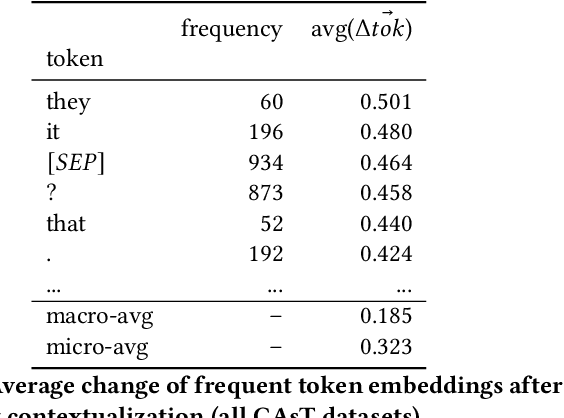
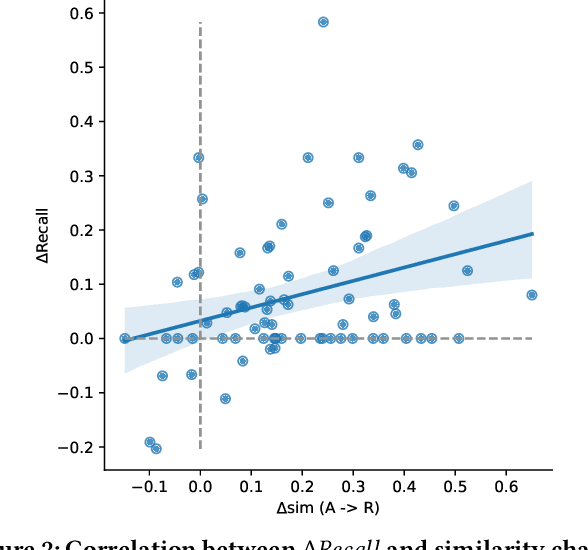
Current conversational passage retrieval systems cast conversational search into ad-hoc search by using an intermediate query resolution step that places the user's question in context of the conversation. While the proposed methods have proven effective, they still assume the availability of large-scale question resolution and conversational search datasets. To waive the dependency on the availability of such data, we adapt a pre-trained token-level dense retriever on ad-hoc search data to perform conversational search with no additional fine-tuning. The proposed method allows to contextualize the user question within the conversation history, but restrict the matching only between question and potential answer. Our experiments demonstrate the effectiveness of the proposed approach. We also perform an analysis that provides insights of how contextualization works in the latent space, in essence introducing a bias towards salient terms from the conversation.
Analysing the Effect of Clarifying Questions on Document Ranking in Conversational Search
Aug 11, 2020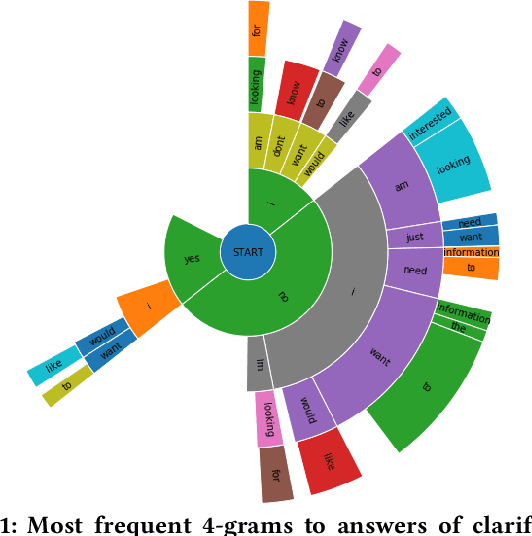
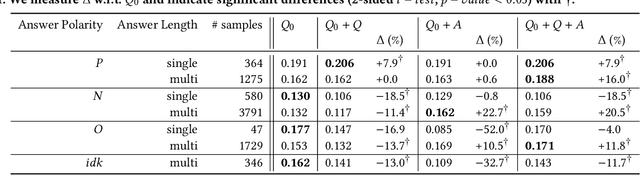
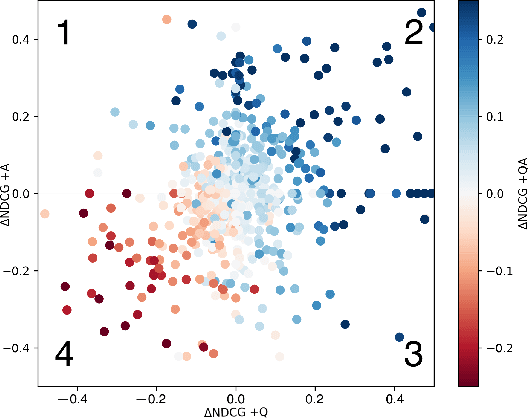
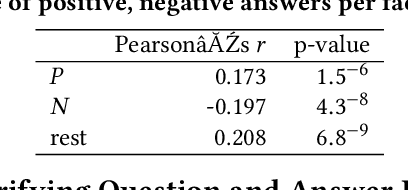
Recent research on conversational search highlights the importance of mixed-initiative in conversations. To enable mixed-initiative, the system should be able to ask clarifying questions to the user. However, the ability of the underlying ranking models (which support conversational search) to account for these clarifying questions and answers has not been analysed when ranking documents, at large. To this end, we analyse the performance of a lexical ranking model on a conversational search dataset with clarifying questions. We investigate, both quantitatively and qualitatively, how different aspects of clarifying questions and user answers affect the quality of ranking. We argue that there needs to be some fine-grained treatment of the entire conversational round of clarification, based on the explicit feedback which is present in such mixed-initiative settings. Informed by our findings, we introduce a simple heuristic-based lexical baseline, that significantly outperforms the existing naive baselines. Our work aims to enhance our understanding of the challenges present in this particular task and inform the design of more appropriate conversational ranking models.