 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing the Effect of Clarifying Questions on Document Ranking in Conversational Search
Paper and Code
Aug 11, 2020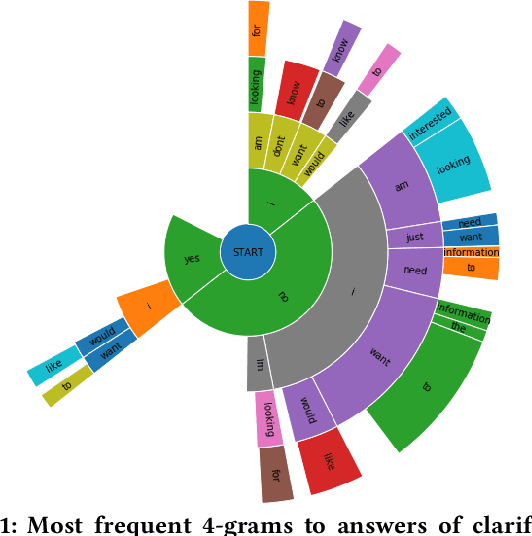
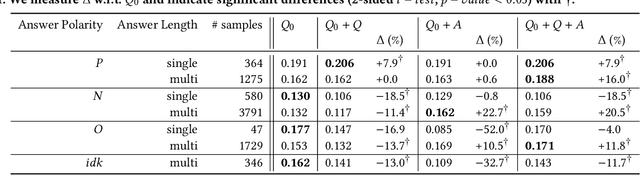
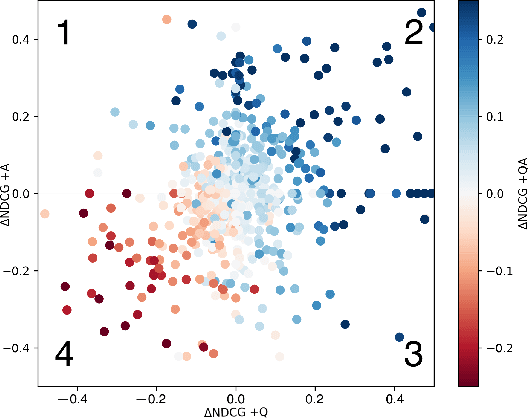
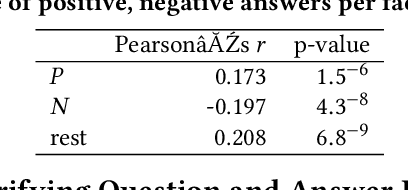
Recent research on conversational search highlights the importance of mixed-initiative in conversations. To enable mixed-initiative, the system should be able to ask clarifying questions to the user. However, the ability of the underlying ranking models (which support conversational search) to account for these clarifying questions and answers has not been analysed when ranking documents, at large. To this end, we analyse the performance of a lexical ranking model on a conversational search dataset with clarifying questions. We investigate, both quantitatively and qualitatively, how different aspects of clarifying questions and user answers affect the quality of ranking. We argue that there needs to be some fine-grained treatment of the entire conversational round of clarification, based on the explicit feedback which is present in such mixed-initiative settings. Informed by our findings, we introduce a simple heuristic-based lexical baseline, that significantly outperforms the existing naive baselines. Our work aims to enhance our understanding of the challenges present in this particular task and inform the design of more appropriate conversational ranking models.